Clear Sky Science · pl
Analiza porównawcza wydajności dużych modeli językowych w egzaminie specjalizacyjnym z zakresu stomatologii
Dlaczego inteligentne chatboty mają znaczenie dla przyszłych dentystów
Sztuczna inteligencja szybko zmienia sposób, w jaki lekarze i stomatolodzy się uczą i pracują. Jednym z najbardziej widocznych narzędzi są konwersacyjne chatboty oparte na dużych modelach językowych — ta sama technologia, która stoi za wieloma popularnymi asystentami AI. W tym badaniu postawiono proste, lecz istotne pytanie: jeśli studenci stomatologii korzystaliby z tych narzędzi, przygotowując się do wysoce konkurencyjnego egzaminu specjalizacyjnego z radiologii jamy ustnej i twarzoczaszki, jak dobrze poradziłyby sobie maszyny?
Testowanie AI na rzeczywistym egzaminie
Aby to sprawdzić, badacze sięgnęli do Dentystycznego Egzaminu Wstępnego na Specjalizację (DUS) w Turcji, który pomaga wyłonić kandydatów na zaawansowane programy szkoleniowe. Z poprzednich lat ogólnokrajowego testu wybrali 208 pytań wielokrotnego wyboru obejmujących zagadnienia, które muszą opanować specjaliści radiologii — od fizyki promieniowania i technik obrazowania po nowotwory szczęk i choroby zatok. Większość pytań miała formę tekstową, ale mniejszy zestaw wymagał interpretacji obrazów radiograficznych, odzwierciedlając diagnostyczną rzeczywistość.
Siedem chatbotów podjęło to samo wyzwanie
Zespół zadał następnie każde pytanie, w języku tureckim, siedmiu powszechnie używanym chatbotom AI opartym na różnych dużych modelach językowych: dwóm wersjom ChatGPT oraz Gemini, Copilot, DeepSeek, Claude i Grok. Każde pytanie wprowadzano starannie i oddzielnie, aby uniknąć przenoszenia kontekstu między rozmowami. Drugi badacz porównał każdą odpowiedź AI z oficjalnym kluczem i oznaczył ją jako prawidłową lub błędną. Na koniec autorzy zastosowali standardowe testy statystyczne do porównania modeli ogólnie oraz w obrębie konkretnych obszarów tematycznych.
Kto zdobył najwięcej punktów — i gdzie popełniano błędy
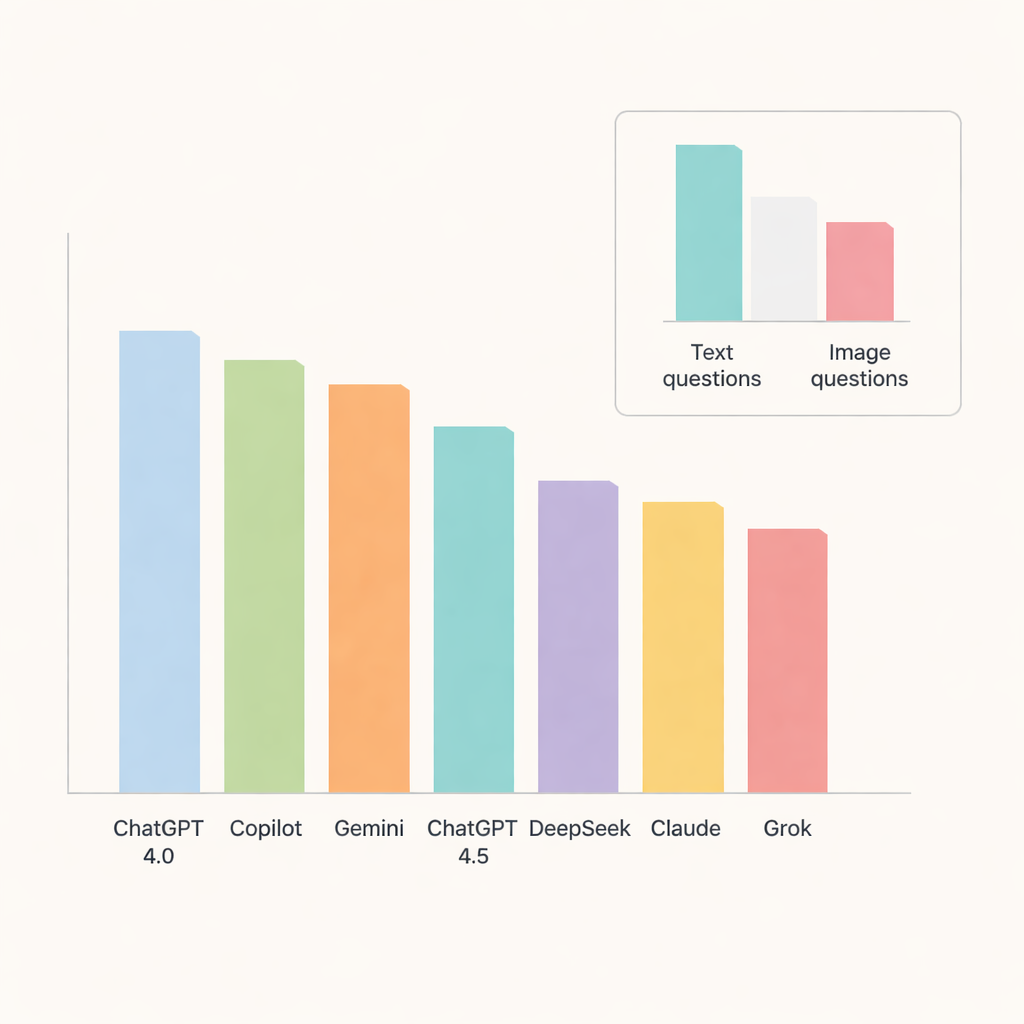
Wśród wszystkich chatbotów wyróżniał się ChatGPT 4.0, odpowiadając prawidłowo na około 91 procent pytań. Copilot i Gemini uplasowały się nieco niżej z dokładnością w środkowych–wysokich 80. procentach, podczas gdy ChatGPT 4.5, DeepSeek, Claude i Grok osiągały nieco słabsze wyniki. Po rozbiciu wyników według tematów, modele radziły sobie szczególnie dobrze z patologią jamy ustnej i schorzeniami gruczołów ślinowych, gdzie trafność zbliżała się do 90 procent lub ją przekraczała. Natomiast anatomia radiograficzna i zwapnienia tkanek miękkich okazały się zauważalnie trudniejsze, obniżając wyniki w tych obszarach i wskazując na aspekty, w których AI wciąż ma problemy z rozróżnieniem drobnych szczegółów.
Obrazy nadal trudniejsze niż tekst
Kluczowym testem było sprawdzenie, czy chatboty poradzą sobie z obrazami tak samo dobrze jak z tekstem. Tutaj ujawniły się ich ograniczenia. Trafność odpowiedzi znacząco spadła w przypadku pytań opartych na obrazach, nawet dla najlepiej ocenianych modeli. ChatGPT 4.0, Gemini i Copilot prowadziły w tej kategorii, ale i tak poprawnie odpowiedziały tylko na około dwie trzecie pytań wizualnych. Najsłabiej w obrazach wypadł DeepSeek, z nieco ponad jedną trzecią prawidłowych odpowiedzi. W przypadku większości modeli różnica między wynikami dla tekstu i obrazu była na tyle duża, że miała znaczenie statystyczne, podkreślając, że interpretacja obrazów medycznych pozostaje trudnym zadaniem dla dzisiejszych ogólnych modeli AI.
Co to oznacza dla studentów i pacjentów
Wniosek z badania jest taki, że nowoczesne chatboty mogą być potężnymi pomocnikami w edukacji stomatologicznej, szczególnie przy powtarzaniu faktów i ćwiczeniu pytań w stylu egzaminacyjnym z radiologii. Jednak nawet najsilniejsze systemy popełniają wystarczającą liczbę błędów — zwłaszcza w zadaniach wymagających rozbudowanej analizy wizualnej lub bardzo wyspecjalizowanej wiedzy — by nie mogły bezpiecznie zastąpić fachowego osądu. Dla studentów i klinicystów narzędzia te najlepiej traktować jako inteligentnych partnerów do nauki lub wsparcie decyzyjne, a nie jako samodzielne autorytety. Stosowane z odpowiednią ostrożnością i nadzorem, mogą przyspieszyć naukę i zwiększyć dostęp do wysokiej jakości wyjaśnień, podczas gdy ostateczna odpowiedzialność za diagnozę i leczenie pozostaje po stronie wykwalifikowanych specjalistów.
Cytowanie: Geduk, G., Hasırcı, U.C., Kusay, D.D. et al. A comparative analysis of the performance of large Language models in the dentistry specialty examination. Sci Rep 16, 6739 (2026). https://doi.org/10.1038/s41598-026-37800-8
Słowa kluczowe: kształcenie stomatologiczne, sztuczna inteligencja, duże modele językowe, radiologia jamy ustnej i twarzoczaszki, egzaminy medyczne