Clear Sky Science · pl
Wykrywanie spamu SMS międzyjęzykowego z użyciem augmentacji opartej na GAN dla niezbilansowanych zbiorów danych
Dlaczego Twoje wiadomości tekstowe wciąż potrzebują ochrony
Wielu z nas ufa, że niechciane SMS-y trafią po cichu do folderu spamu, ale w rzeczywistości to bardzo trudny problem. Prawdziwy spam jest rzadki w porównaniu z codziennymi wiadomościami i coraz częściej pojawia się jednocześnie w wielu językach. W artykule przedstawiono nowy sposób wykrywania niebezpiecznego spamu w SMS-ach, łączący potężne modele językowe z pomysłowym „generatoren fałszywych danych”, dzięki czemu filtry mogą uczyć się na znacznie większej liczbie przykładów złośliwych wiadomości, nie narażając prywatności użytkowników.
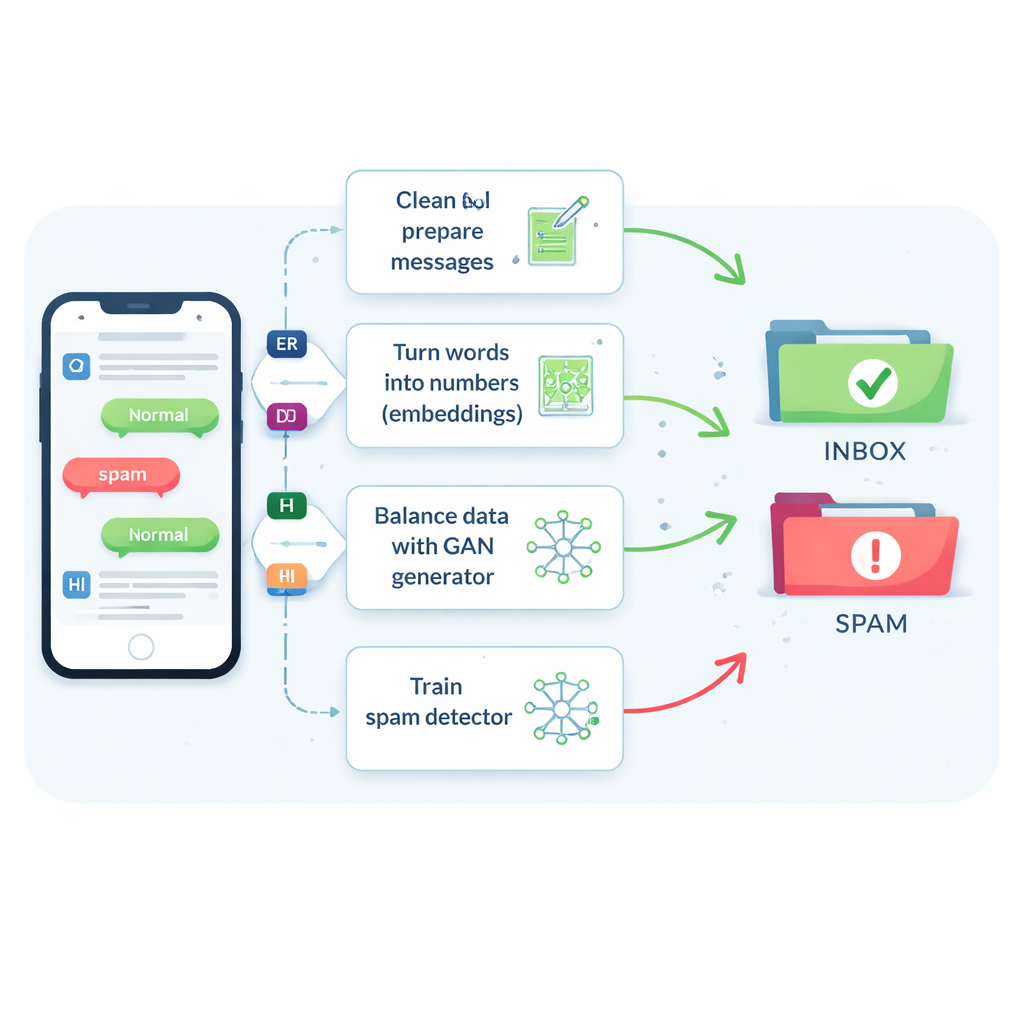
Problem rzadkiego i zmiennego spamu
Wiadomości typu spam stanowią zaledwie około jednej na siedem wiadomości, a mimo to przeoczenie nawet niewielkiej części z nich może narazić ludzi na oszustwa, złośliwe oprogramowanie i kradzież tożsamości. Tradycyjne filtry mają trudności, ponieważ SMS-y są krótkie, pełne slangu i skrótów oraz przychodzą w czasie rzeczywistym z małą ilością dodatkowego kontekstu. W efekcie wiele systemów skłania się ku oznaczaniu wiadomości jako bezpieczne, co utrzymuje zadowolenie użytkowników, ale pozwala równie szkodliwym treściom się przedostać. Starsze triki polegające na prostym duplikowaniu spamu lub tworzeniu nowych przykładów przez drobne zmiany słów mogą trochę pomóc, ale często mylą filtr lub generują nierealistyczne przykłady, które nie odpowiadają temu, co faktycznie wysyłają przestępcy.
Nauka maszyn rozumienia znaczenia wiadomości
Autorzy zaczynają od porównania ośmiu różnych algorytmów uczących się, od powszechnie znanych narzędzi, takich jak maszyny wektorów nośnych i drzewa decyzyjne, po bardziej zaawansowane sieci neuronowe czytające tekst jako sekwencję, takie jak sieci LSTM (long short-term memory). Testują też pięć sposobów zamiany słów na liczby, które komputer potrafi wykorzystać. Proste zliczenia, jak often występowanie słów (znane jako bag-of-words lub TF–IDF), są szybkie, ale nie dostrzegają znaczenia. Nowsze «osadzenia» (embeddings) jak Word2Vec i GloVe umieszczają słowa o podobnym znaczeniu blisko siebie w przestrzeni numerycznej. Najbardziej zaawansowane są modele oparte na transformerach, takie jak BERT, które dostosowują reprezentację słowa w zależności od otaczającego zdania, pomagając systemowi rozróżnić na przykład przyjazne przypomnienie od przekonującego oszustwa.
Wykorzystanie inteligentnego „fałszywego” spamu do naprawy niezbilansowanego zbioru
Główną innowacją jest sposób, w jaki badanie rozwiązuje brak przykładów spamu. Zamiast generować pełne fałszywe zdania, zespół szkoli typ sieci neuronowej zwany Generative Adversarial Network (GAN) bezpośrednio na numerycznych osadzeniach (embeddings) spamu. Jedna część GAN-a, generator, uczy się tworzyć syntetyczne punkty podobne do spamu w tej wysokowymiarowej przestrzeni, podczas gdy druga część, dyskryminator, uczy się odróżniać je od prawdziwych. Dzięki tej rywalizacji generator produkuje realistyczne nowe osadzenia spamu, które rozszerzają zbiór treningowy. Kontrola jakości oparta na podobieństwie zapewnia, że zachowywane są tylko syntetyczne przykłady ściśle przypominające autentyczny spam, zmniejszając ryzyko nonsensownych danych, które mogłyby wprowadzić w błąd klasyfikator.
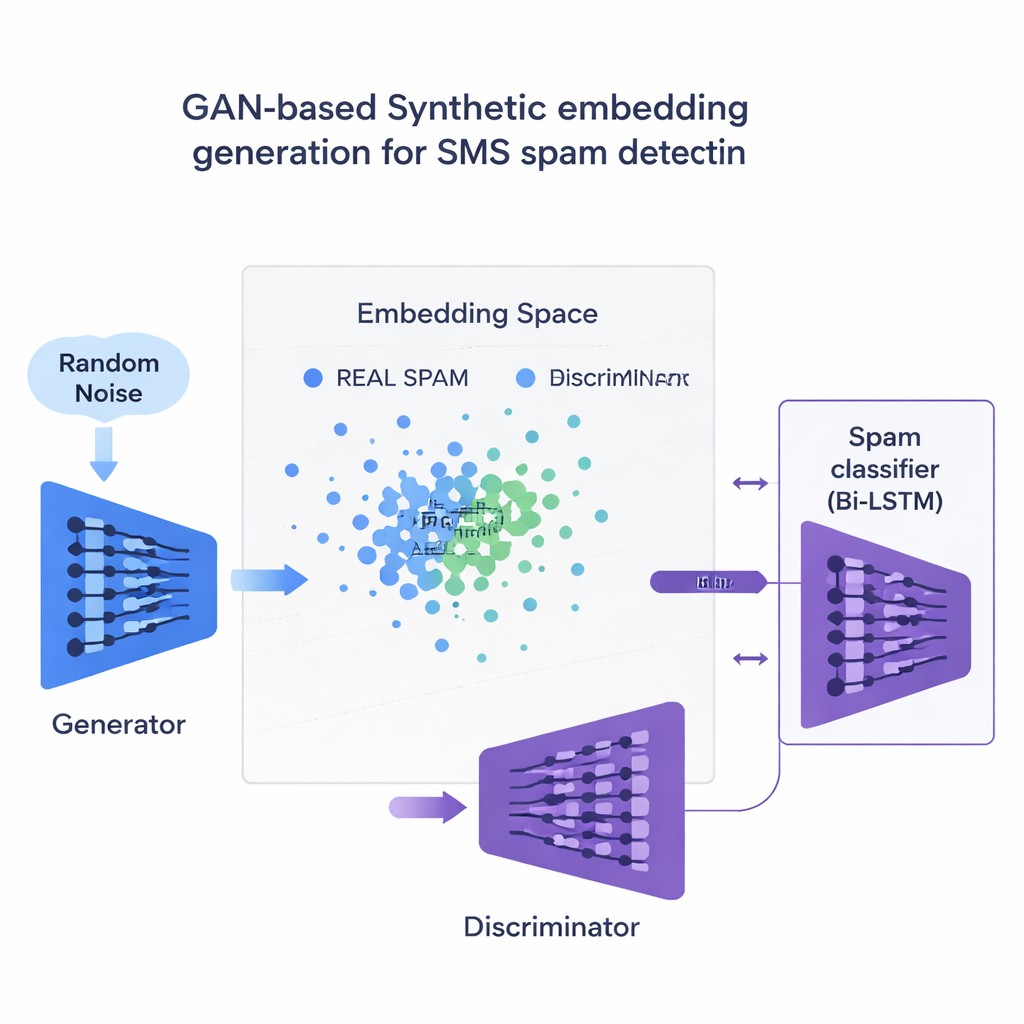
Wyniki w różnych językach i na różnych urządzeniach
Badacze testują 120 różnych kombinacji modeli, osadzeń i metod balansowania danych, zarówno na angielskim zbiorze SMS, jak i na wielojęzycznej wersji przetłumaczonej na francuski, niemiecki i hindi. W całym badaniu kontekstowe osadzenia, takie jak BERT, przewyższają starsze podejścia oparte na zliczaniu słów. Najlepsze ustawienie — dwukierunkowy LSTM zasilany osadzeniami BERT i trenowany z przykładami spamu wygenerowanymi przez GAN — osiąga F1 około 97,6% dla wiadomości angielskich i 94,4% dla zestawu wielojęzycznego, wyprzedzając dotychczasowe systemy o zaawansowanej skuteczności. Co istotne, dzieje się to przy zachowaniu bardzo niskiego poziomu fałszywych alarmów, co jest ważne, aby jednorazowe hasła i powiadomienia bankowe nie zostały błędnie ukryte przed użytkownikami. Badanie porównuje też tę strategię GAN z bardziej powszechnymi narzędziami do wyrównywania danych, takimi jak SMOTE i ADASYN, wykazując, że GAN produkuje czystsze, bardziej realistyczne dane treningowe i daje nieco lepsze ogólne wyniki.
Co to oznacza dla zwykłych użytkowników
Dla osób niezajmujących się na co dzień tematem wniosek jest taki, że filtry spamu zaczynają rozumieć sens i kontekst Twoich wiadomości, a nie tylko pojedyncze słowa, i można je „uczyć” przy pomocy starannie przygotowanych danych syntetycznych zamiast przeglądać więcej Twoich prawdziwych wiadomości. Pracując bezpośrednio w przestrzeni, w której zakodowane jest znaczenie wiadomości, proponowana metoda daje systemom bezpieczeństwa pełniejszy obraz tego, jak wygląda spam w wielu językach, bez zalewania ich nieporęcznymi falsyfikatami. Zwiększa to prawdopodobieństwo, że niebezpieczne wiadomości zostaną wykryte, a prawdziwe dostarczone, oferując silniejszą i bardziej adaptacyjną ochronę użytkownikom mobilnym w obliczu ciągłych zmian taktyk oszustów.
Cytowanie: Filali, A., Shorfuzzaman, M., Abdellaoui Alaoui, E. et al. Cross-lingual SMS spam detection using GAN-based augmentation for imbalanced datasets. Sci Rep 16, 7128 (2026). https://doi.org/10.1038/s41598-026-37769-4
Słowa kluczowe: Wykrywanie spamu w SMS, Augmentacja danych GAN, Osadzenia tekstu BERT, Wielojęzyczne cyberbezpieczeństwo, Phishing mobilny