Clear Sky Science · pl
Lekka architektura konwolucyjnej sieci neuronowej do wykrywania przemocy w sekwencjach wideo
Obserwowanie tłumów, żeby ludzie nie musieli
Od koncertów i aren sportowych po stacje metra i centra handlowe — kamery monitorują dziś niemal każde zatłoczone miejsce. Mimo to większość tych strumieni wideo wciąż nadzorują zmęczone ludzkie oczy, które łatwo mogą przegapić pierwsze sygnały bójki lub paniki. W artykule badano, jak szczupła, szybka forma sztucznej inteligencji może skanować wideo na żywo w poszukiwaniu zachowań agresywnych w czasie rzeczywistym, nawet na tanim sprzęcie, pomagając ochronie reagować szybko, zanim sytuacja wymknie się spod kontroli.
Dlaczego rozpoznawanie przemocy na wideo jest takie trudne
Początkowo poproszenie komputera o rozróżnienie „bójki” od „braku bójki” wydaje się proste: wystarczy wykryć ludzi uderzających się nawzajem. W praktyce problem jest jednak złożony. Oświetlenie może być słabe lub zmieniać się nagle, tłumy mogą zasłaniać widok, a kamery są umieszczone pod bardzo różnymi kątami. Zatłoczony koncert rockowy wygląda chaotycznie nawet wtedy, gdy nie dzieje się nic niebezpiecznego, podczas gdy walka bokserska wygląda na gwałtowną, lecz w ringu jest normalna. Tradycyjne systemy wizyjne analizowały ręcznie projektowane wzory ruchu i krawędzie klatka po klatce, i chociaż działały w laboratorium, często były zbyt wolne lub zbyt niedokładne dla zatłoczonych sieci nadzoru w rzeczywistych warunkach.
Szczuplejszy „mózg” dla strumieni z kamer
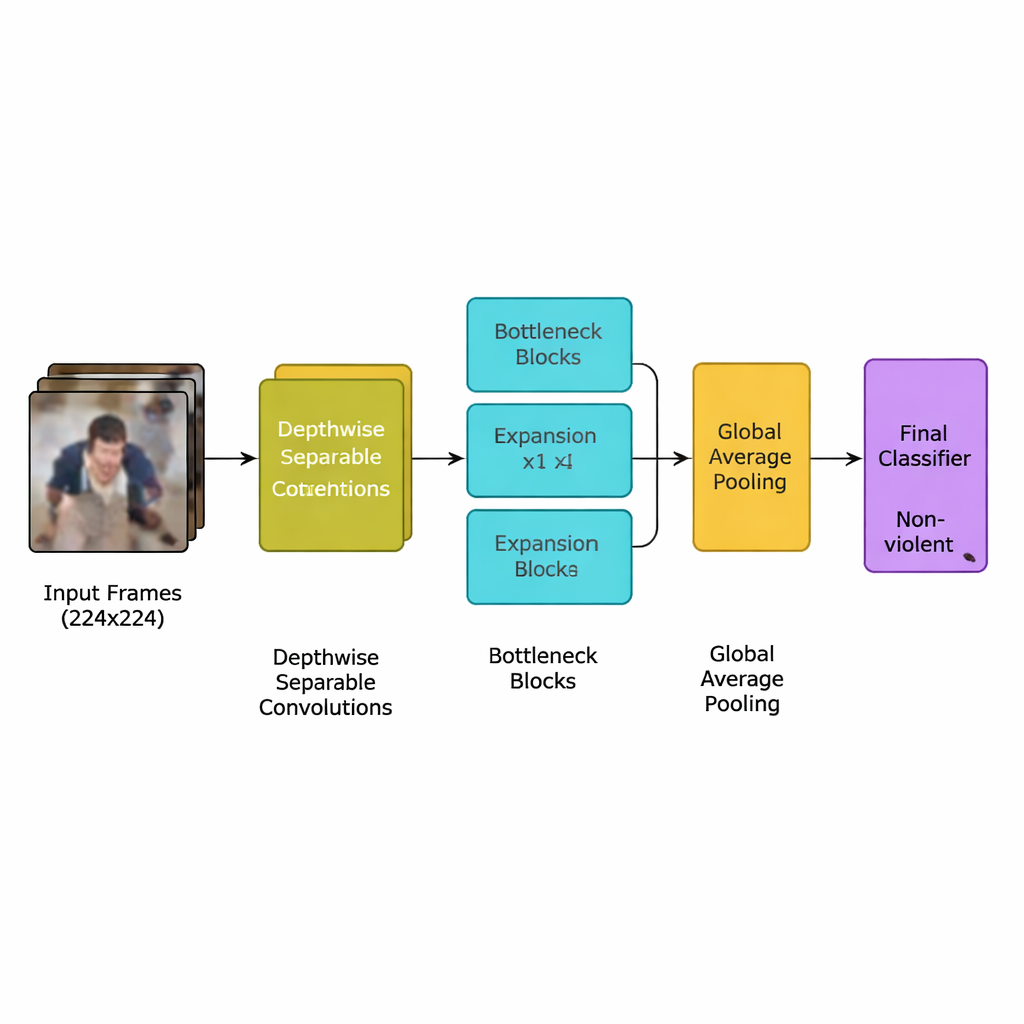
Autorzy przedstawiają nowy model głębokiego uczenia zaprojektowany specjalnie do tego zadania: lekka konwolucyjna sieć neuronowa (CNN) wywodząca się z efektywnej rodziny modeli znanej jako MobileNetV2. Zamiast stosować wiele ciężkich warstw wymagających wydajnych procesorów graficznych, sieć opiera się na konwolucjach separowalnych w głębokości — niewielkich, ukierunkowanych obliczeniach, które drastycznie zmniejszają liczbę operacji. Używa też bloków z „odwróconym wąskim gardłem” (inverted bottleneck), które chwilowo rozszerzają, a następnie kompresują informacje, zachowując istotne wskazówki ruchu przy redukcji redundancji. Dodatkowo zespół dodał mechanizm uwagi zwany squeeze‑and‑excitation, który pomaga sieci skoncentrować się na wzorcach ruchu w przestrzeni i czasie typowych dla incydentów gwałtownych, jednocześnie ignorując rozpraszające szczegóły tła.
Od surowego wideo do alertów o przemocy
Cały system realizuje jasny proces. Najpierw strumienie wideo są dzielone na klatki, a zachowywana jest tylko co piąta klatka, aby usunąć niemal identyczne obrazy przy zachowaniu nagłych ruchów, które często sygnalizują bójkę. Klatki są skalowane do standardu 224×224 pikseli, lekko rozmywane, by zmniejszyć szum tła, a podczas treningu losowo odbijane lub obracane, by model nauczył się radzić sobie z różnymi punktami widzenia kamer. Przygotowane obrazy trafiają do lekkiego CNN, który stopniowo przekształca surowe piksele w wyższej rangi wzorce zachowań tłumu. Po końcowym kroku uśredniania (poolingu), mały klasyfikator wydaje prostą decyzję: przemoc lub brak przemocy. Ponieważ model wykorzystuje tylko około 1,94 miliona parametrów — mniej niż jego poprzednicy MobileNet i MobileNetV2 — może działać w czasie rzeczywistym na skromnych urządzeniach umieszczonych blisko kamer, zamiast w odległym centrum danych.
Testy systemu
Aby sprawdzić, czy ta kompaktowa konstrukcja może konkurować z cięższymi sieciami, badacze trenowali i oceniali ją na dwóch powszechnie używanych zestawach testowych. Real‑Life Violence Situations Dataset zawiera 2000 krótkich klipów z YouTube pokazujących zarówno codzienne sceny, jak i prawdziwe bójki w różnych miejscach. Hockey Fight Dataset oferuje 1000 klipów z profesjonalnych meczów hokejowych, podzielonych między zwykłą grę a bójki na lodzie. Na tych zbiorach zaproponowany model poprawnie sklasyfikował około 97 procent klipów w scenariuszach z życia codziennego i 94 procent w materiałach hokejowych, dorównując lub przewyższając większe sieci CNN, takie jak InceptionV3 i VGG‑19, przy znacznie mniejszym zapotrzebowaniu na obliczenia. Testy krzyżowe między dwoma zestawami — trenowanie na jednym i testowanie na drugim — wykazały, że system nadal działał rozsądnie dobrze, co sugeruje, że wyłapuje ogólne wzorce ruchu zamiast zapamiętywać jedno środowisko.
Co to oznacza dla codziennego bezpieczeństwa
Dla osób nietechnicznych najważniejszy wniosek jest taki, że dziś możliwe jest budowanie systemów kamer, które automatycznie sygnalizują prawdopodobną przemoc szybko i tanio, bez potrzeby ogromnych serwerów czy stałej uwagi człowieka. Badanie pokazuje, że starannie przycięta i dostrojona sieć neuronowa może obserwować wiele strumieni jednocześnie, wysyłać alerty po wykryciu niebezpiecznego zachowania i nadal działać na urządzeniach o niskim poborze mocy, odpowiednich dla węzłów komunikacji publicznej, szkół, szpitali i ulic miejskich. Choć wyzwania pozostają — na przykład obsługa bardzo ciemnych scen, silnego zatłoczenia czy dodanie wskazówek dźwiękowych — praca ta wskazuje na przyszłość, w której inteligentne kamery działają jako niestrudzone czujniki wczesnego ostrzegania, pomagając zespołom ochrony skuteczniej chronić ludzi i zmniejszając obciążenie obserwatorów ludzkich.
Cytowanie: Tyagi, B., Jain, R., Jain, P. et al. A lightweight convolutional neural network architecture for violence detection in video sequences. Sci Rep 16, 7557 (2026). https://doi.org/10.1038/s41598-026-37743-0
Słowa kluczowe: wykrywanie przemocy, monitoring wideo, lekki CNN, MobileNetV2, bezpieczeństwo publiczne