Clear Sky Science · pl
Algorytm łączenia obrazów podczerwonych i widzialnych oparty na NSCT i ulepszonej detekcji saliencyjnej FT
Widzieć w ciemności i przez chaos
Nowoczesne kamery dają nam ostre, kolorowe obrazy świata, ale zawodzą przy mgle, w ciemności czy w silnym odblasku — właśnie wtedy, gdy najbardziej potrzebujemy niezawodnego widzenia do jazdy, nadzoru, poszukiwań i ratownictwa albo dla dronów. Czujniki podczerwieni rejestrują ciepło zamiast koloru i doskonale radzą sobie w tych trudnych warunkach, ale tworzą rozmyte, mało szczegółowe obrazy. W pracy zaprezentowano metodę inteligentnego łączenia obrazów podczerwonych i widzialnych, tak aby końcowy obraz zawierał zarówno wyraźne szczegóły, jak i wyraźnie podkreślone osoby czy obiekty, nawet w trudnych scenach.
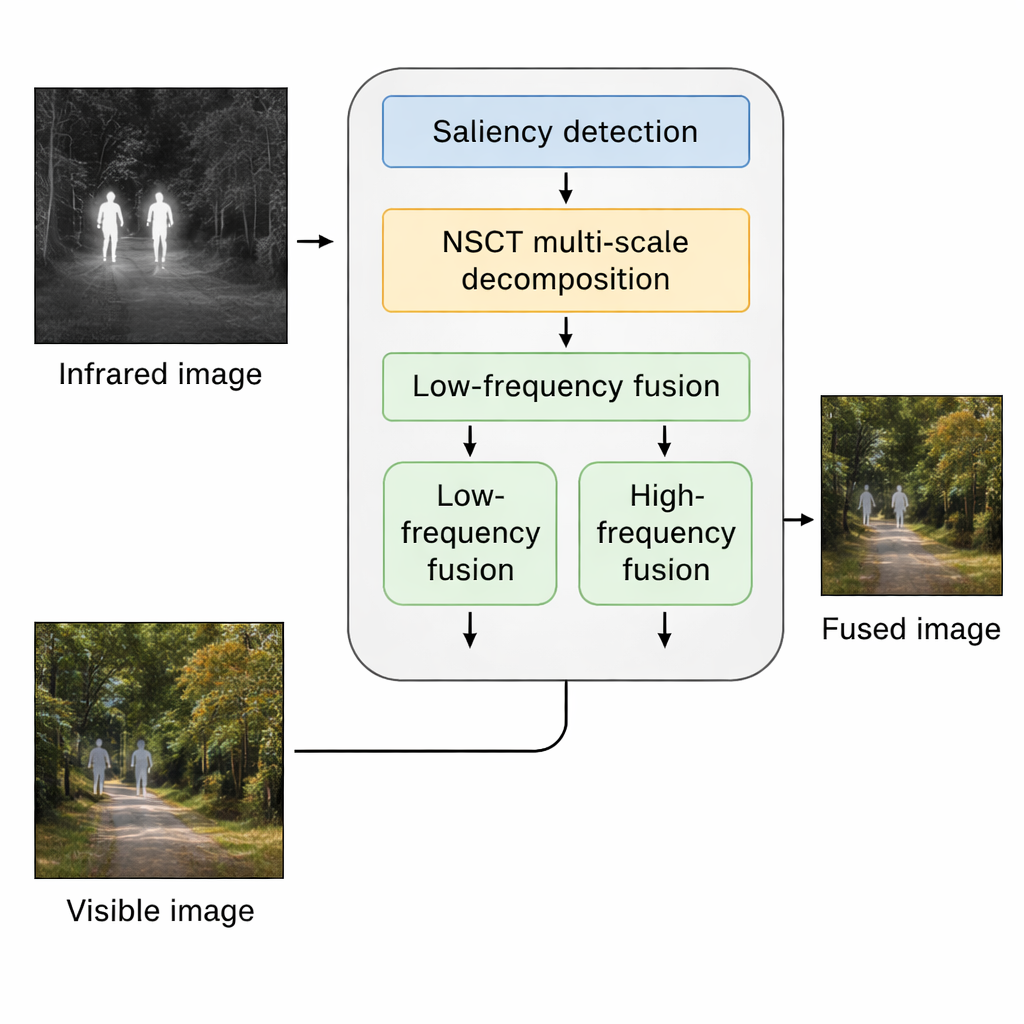
Dlaczego dwa „oczy” są lepsze niż jedno
Kamera widzialnego rejestruje drobne tekstury i bogate tło, ale jej skuteczność spada nocą lub w głębokim cieniu, a cele mogą zlewać się z podobnie zabarwionym otoczeniem. Kamery podczerwieni robią odwrotnie: wychwytują ciepłe ciała i emitujące ciepło obiekty na tle ciemnego otoczenia, w dzień i w nocy, lecz tracą wiele subtelnej struktury budynków, drzew i dróg. Fuzja tych dwóch rodzajów obrazów może w zasadzie połączyć najlepsze cechy obu. Jednak wiele istniejących metod fuzji albo rozmywa kontrast, albo zatraca krawędzie obiektów, albo pozwala, by szumowe wzory z podczerwieni zdominowały użyteczne szczegóły z obrazu widzialnego.
Główna idea: niech ważne fragmenty się wyróżniają
Autorzy podchodzą do fuzji jako do problemu rozwiązywania konfliktów między dwoma typami obrazów. Koncentrują się na trzech powtarzających się kwestiach: wykrywaniu, które obszary są rzeczywiście istotne ("saliencyjne"), wyrównaniu ogólnej jasności między gorącymi celami z podczerwieni a jasnym tłem widzialnym oraz zachowaniu delikatnych tekstur przy tłumieniu szumu z podczerwieni. Aby to osiągnąć, udoskonalają popularną technikę zwaną detekcją saliencyjną dostrojoną częstotliwościowo (frequency‑tuned), która próbuje naśladować ludzki system wzrokowy poprzez podkreślanie regionów naturalnie przyciągających uwagę. Zamiast polegać na prostym rozmyciu, stosują parę inteligentniejszych filtrów — jeden wygładzający przy zachowaniu krawędzi, a drugi wzmacniający kontrast — aby wyciąć czystszą, ostrzejszą mapę miejsc, gdzie znajdują się interesujące cele z podczerwieni.
Oddzielanie grubych kształtów od drobnych detali
Gdy algorytm wie już, gdzie leżą kluczowe cele z podczerwieni, rozkłada oba obrazy — podczerwony i widzialny — na warstwy oddzielające struktury ogólne od drobnych detali, używając narzędzia matematycznego nazwanego niezpodpróbkowanym transformatem konturowym (Non‑Subsampled Contourlet Transform). Warstwy niskich częstotliwości zawierają szerokie wzory jasności, takie jak niebo, drogi czy ściany, podczas gdy warstwy wysokich częstotliwości przechwytują krawędzie, tekstury i małe elementy. Dla warstw grubych metoda miesza informacje, wykorzystując zarówno ulepszoną mapę saliencyjną podczerwieni, jak i miarę Laplasjanu określającą ostrość lokalnych struktur. To pomaga uniknąć wypranych obrazów, w których albo ciepłe obiekty dominują scenę, albo tło widzialne przytłacza ważne cele.
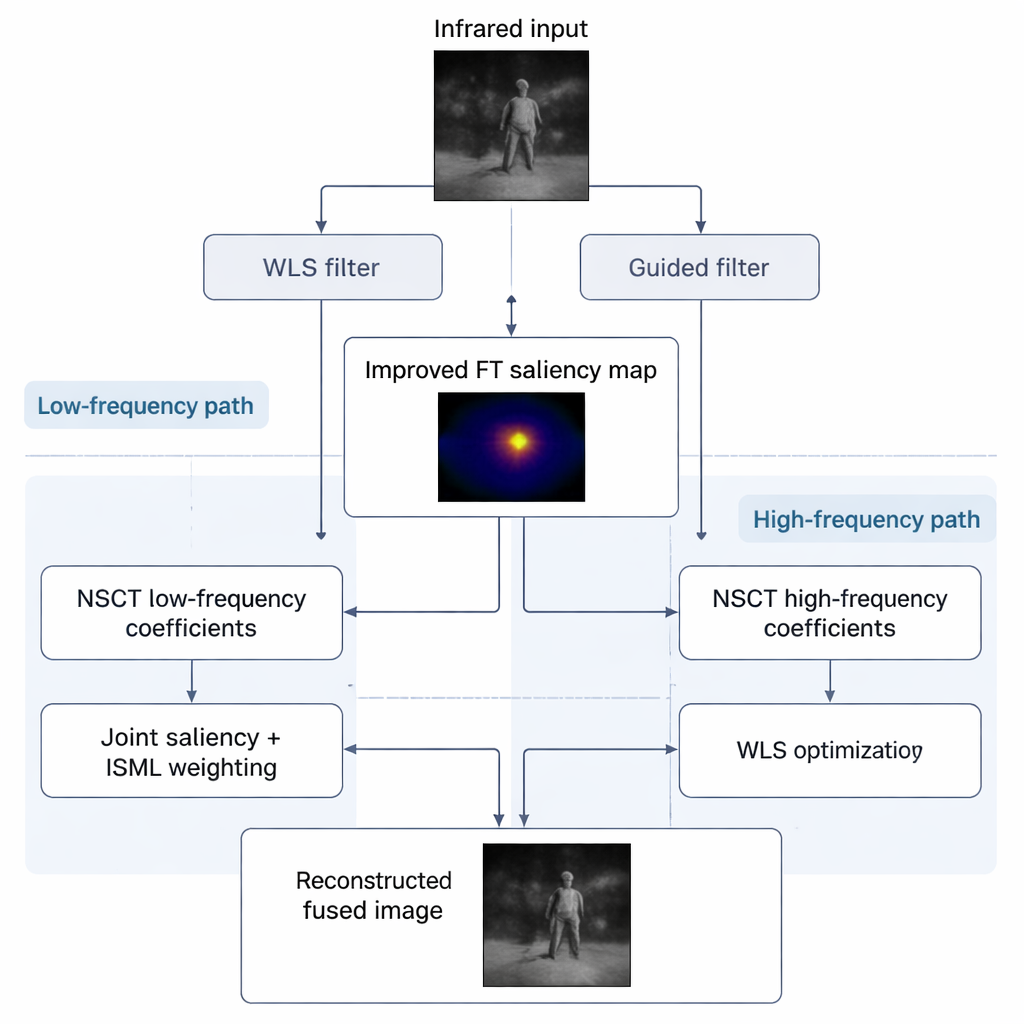
Zachowanie ostrych tekstur i kontrola szumu
Warstwy wysokich częstotliwości wymagają innej strategii, ponieważ to w nich mieszczą się zarówno użyteczne tekstury, jak i rozpraszający szum. Tutaj metoda najpierw wybiera, region po regionie, który czujnik oferuje silniejsze lokalne detale. Następnie dopracowuje ten wstępny wybór za pomocą procedury ważonych najmniejszych kwadratów, która skłania się ku czyściejszym, bardziej informacyjnym teksturom z obrazu widzialnego, jednocześnie pozwalając przenikać znaczącym wzorom z podczerwieni. Efektem jest obraz z fuzji, w którym gałęzie drzew, krawędzie budynków i oznakowania drogowe wyglądają ostro, a jednocześnie zredukowano ziarniste artefakty podczerwieni.
Lepsze obrazy, lepsze decyzje maszyn
Zespół przetestował swoje podejście na kilku publicznych zbiorach danych i własnych obrazach o niskim oświetleniu, porównując je z tradycyjnymi technikami i nowoczesnymi metodami uczenia głębokiego. Inspekcja ludzka wykazała, że ich obrazy z fuzji mają czystsze tła, wyższy kontrast i bardziej widoczne cele, zwłaszcza w ciemnych korytarzach, ulicach nocą i zagraconych scenach zewnętrznych. Obiektywne miary zawartości informacji, ostrości i kontrastu przeważnie faworyzowały nową metodę lub wskazywały, że jest ona dobrze zbalansowana pod względem metryk. Co ważne, gdy te obrazy z fuzji zostały podane popularnemu systemowi wykrywania obiektów (YOLOv5s), dokładność wykrywania, precyzja i czułość wszystkie wyraźnie się poprawiły. Mówiąc prosto, algorytm nie tylko tworzy ładniejsze obrazy; pomaga także zautomatyzowanym systemom bardziej niezawodnie odnajdywać ludzi i obiekty. To sugeruje, że inteligentniejsza fuzja obrazów podczerwieni i widzialnych może odegrać kluczową rolę w bezpieczniejszym autonomicznym prowadzeniu, skuteczniejszym nadzorze i bardziej niezawodnych robotach działających w ciemności lub w wizualnie złożonych środowiskach.
Cytowanie: Fan, X., Kong, F., Shi, H. et al. Infrared and visible image fusion algorithm based on NSCT and improved FT saliency detection. Sci Rep 16, 7144 (2026). https://doi.org/10.1038/s41598-026-37670-0
Słowa kluczowe: fuzja podczerwień‑widzialne, saliencyjność obrazu, obrazowanie wieloczujnikowe, widzenie w nocy, widzenie komputerowe