Clear Sky Science · pl
MSRCTNet: nowa sieć kapsułek potrójnych wielkiej skali do wydajnego usuwania powtarzających się klatek w wideo z endoskopii kapsułkowej bezprzewodowej
Połknąć aparat, utopić się w obrazach
Wyobraź sobie diagnozowanie chorób jelit przez połknięcie kamery o wielkości witaminy, która po cichu fotografuje cały twój układ trawienny. Endoskopia kapsułkowa bezprzewodowa już to umożliwia, ale każde badanie generuje około 55 000 zdjęć, z których większość wygląda prawie tak samo. Lekarze muszą przesiać tę wizualną powódź, by dostrzec maleńkie ogniska krwawienia, stanu zapalnego czy guzy. Badanie stojące za MSRCTNet stawia proste, lecz kluczowe pytanie: czy inteligentny system może bezpiecznie usuwać podobne klatki, tak aby lekarze widzieli tylko to, co naprawdę istotne?
Dlaczego zbyt wiele zdjęć może być problemem
Tradycyjna endoskopia wymaga wprowadzenia giętkiej rurki przez usta lub odbyt — zabiegu, który wielu pacjentów uważa za nieprzyjemny i który nie zawsze pozwala dotrzeć do całego jelita cienkiego. Endoskopia kapsułkowa rozwiązuje ten problem, pozwalając kamerze‑pigułce swobodnie przemierzać jelita i robić zdjęcia co sekundę. Wadą jest przeciążenie: tylko około 1% klatek zawiera wyraźnie przydatne informacje, podczas gdy reszta głównie powtarza te same fałdy tkanki. Przeglądanie takiego wolumenu jest powolne i męczące, co zwiększa ryzyko, że wypalony klinicysta przeoczy subtelne zmiany. Wcześniejsze metody komputerowe próbowały pomagać, grupując podobne klatki, kompresując dane lub polegając na prostych cechach koloru i tekstury, ale często zawodziły przy zmianach oświetlenia, złożonym ruchu jelit albo gdy rzadkie nieprawidłowości występowały tylko kilka razy.
Inteligentniejsze wykrywanie powtórzeń
MSRCTNet (Multi‑Scale Capsule Triplet Network) to system uczenia głębokiego zaprojektowany, by służyć jako inteligentny filtr dla wideo z kapsułki. Zamiast traktować każde zdjęcie jak płaski obraz, system analizuje wzory na wielu skalach jednocześnie — drobne tekstury błony śluzowej i szersze kształty ściany jelita — używając mechanizmu uwagi, by uwypuklić najbardziej informacyjne detale. Wzbogacone cechy są następnie przekazywane do warstwy w stylu kapsułek, która zachowuje relacje przestrzenne między częściami obrazu, takie jak orientacja i układ fałdów czy zmian chorobowych. Na koniec specjalny moduł podobieństwa porównuje potrójki klatek — obraz odniesienia, taki, który powinien być podobny, i taki, który powinien być różny — aby nauczyć reprezentacji, w której naprawdę redundantne klatki grupują się ciasno, a charakterystyczne klatki wyraźnie się od siebie oddzielają.
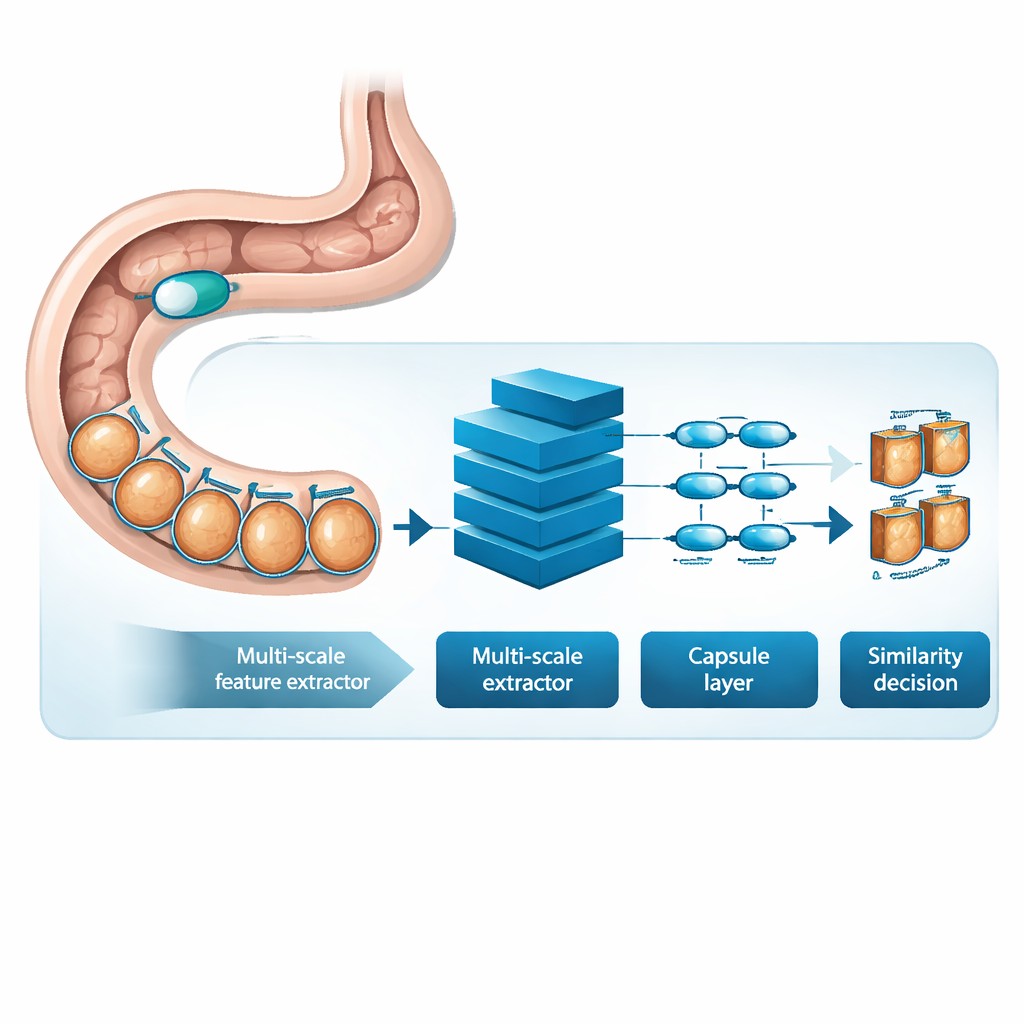
Nauka na prawdziwych badaniach pacjentów
Aby przetestować MSRCTNet, badacze zebrali duży zbiór danych składający się z 257 362 obrazów pochodzących z 60 badań kapsułkowych przeprowadzonych w szpitalu w Chinach. Zdjęcia obejmowały tkankę prawidłową, obszary zasłonięte pęcherzykami oraz wyraźne nieprawidłowości, takie jak krwawienie i zapalenie, wszystkie oznaczone przez doświadczonych klinicystów. System był trenowany, by oceniać, czy pary klatek są podobne, czy nie, wykorzystując kombinację dwóch celów uczenia: jednego, który przyciąga klatki z tej samej kategorii i odpycha te z różnych kategorii, oraz drugiego, który uczy sieć bezpośrednio stwierdzać, czy para jest podobna. Po przeszkoleniu model przegląda wideo po trzy klatki naraz i decyduje, które z sąsiadujących obrazów są faktycznie redundantne. Stosując proste reguły do tych decyzji o podobieństwie, odrzuca powtarzające się ujęcia, zachowując reprezentatywne klatki kluczowe.
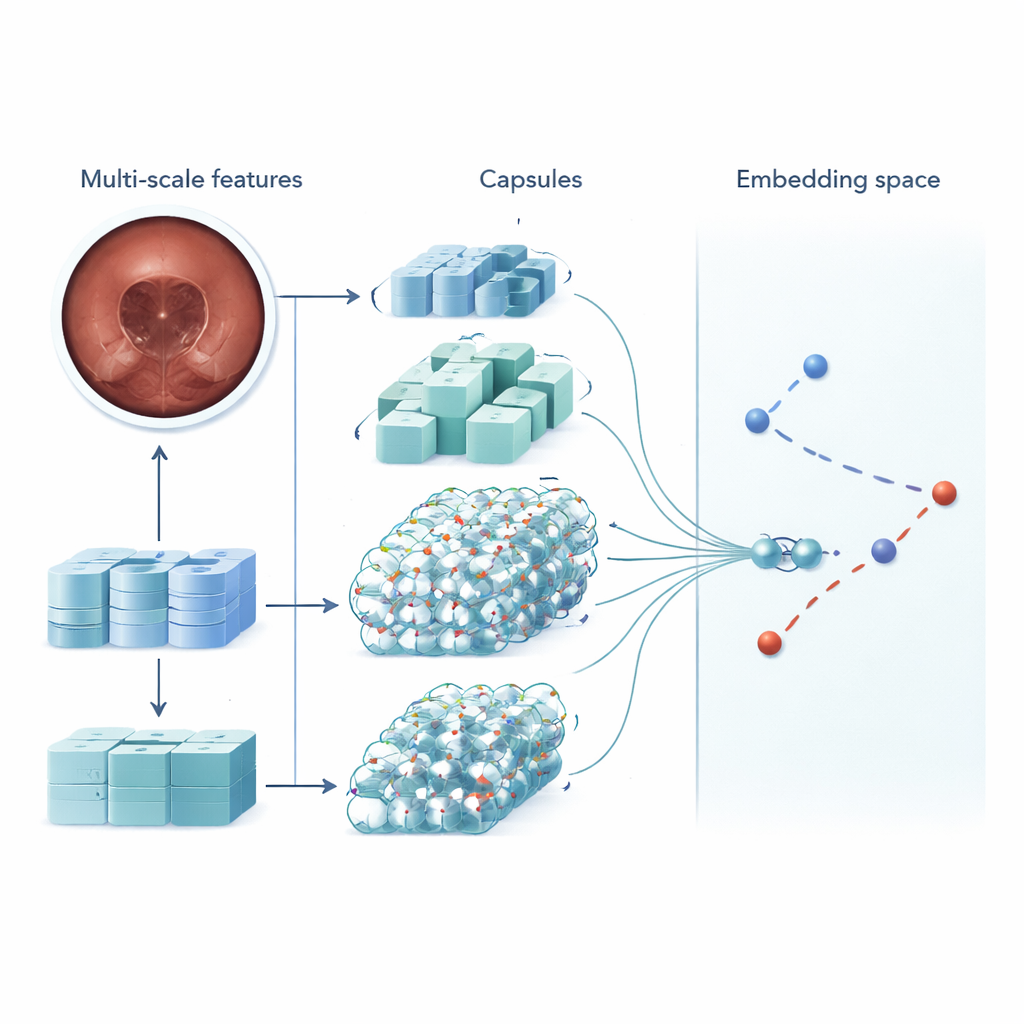
Szybkość, dokładność i mniej przeoczonych problemów
Na danych testowych MSRCTNet poprawnie rozpoznawał redundancję klatek w około 96% przypadków, z odsetkiem fałszywych alarmów poniżej 3% i wskaźnikiem pominiętych klatek poniżej 0,2%. W praktyce dla badania składającego się z 50 000 klatek odpowiada to pominięciu mniej niż 100 potencjalnie istotnych klatek — na tyle niewiele, że otaczające obrazy nadal dostarczają kontekstu przy szybkoci 6 klatek na sekundę. W porównaniu z kilkoma wcześniejszymi technikami opartymi na grupowaniu, analizie ruchu czy prostszych sieciach neuronowych, MSRCTNet był zarówno dokładniejszy, jak i bardziej odporny, gdy dane były niezbalansowane, czyli gdy obrazy prawidłowe zdecydowanie przeważały nad rzadkimi zmianami. System działał też szybko: około 0,02 sekundy na klatkę, czyli około 15 minut, by zmniejszyć pełne badanie do około 2 500 klatek kluczowych — objętości znacznie łatwiejszej do przejrzenia przez człowieka.
Co to oznacza dla pacjentów i lekarzy
Dla pacjentów postęp opisany w tym artykule nie zmienia kapsułki, którą połykają, ale może uczynić ich badanie bardziej efektywnym. Automatycznie przycinając niemal identyczne obrazy bez ręcznie dobieranych progów czy kruchych heurystyk, MSRCTNet umożliwia klinicystom skupienie uwagi na zwartej, bogatej w informacje syntezie podróży przez jelita. Podejście zachowuje klinicznie ważne odkrycia przy jednoczesnym zmniejszeniu zmęczenia i czasu spędzonego przy konsoli do odczytu, co potencjalnie czyni nieinwazyjne badania kapsułkowe bardziej atrakcyjnymi i powszechnie stosowanymi. W istocie metoda zamienia potok zdjęć w starannie zmontowane streszczenie, przybliżając obietnicę sztucznej inteligencji do codziennej opieki nad chorobami przewodu pokarmowego.
Cytowanie: Li, Q., Wang, S., Cheng, Z. et al. MSRCTNet: a novel multi-scale capsule triplet network for efficient redundant frame removal in wireless capsule endoscopy videos. Sci Rep 16, 6902 (2026). https://doi.org/10.1038/s41598-026-37669-7
Słowa kluczowe: endoskopia kapsułkowa bezprzewodowa, streszczanie wideo medycznego, uczenie głębokie, usuwanie zbędnych klatek, obrazowanie przewodu pokarmowego