Clear Sky Science · pl
Wykorzystanie obrazowania medycznego i głębokiego uczenia do diagnostyki raka piersi przy użyciu obrazów histopatologicznych
Dlaczego wczesne wykrycie ma znaczenie
Rak piersi jest jedną z głównych przyczyn zgonów z powodu nowotworów u kobiet na całym świecie, ale rokowania poprawiają się znacznie, gdy choroba zostanie wykryta wcześnie. Lekarze zazwyczaj diagnozują raka piersi, badając cienkie przekroje tkanki pod mikroskopem — proces zwany histopatologią. Te obrazy zawierają bogate informacje o tym, czy komórki są niegroźne czy niebezpieczne, jednak ich ocena jest czasochłonna i może się różnić między specjalistami. W tym badaniu zbadano, jak nowoczesna sztuczna inteligencja może pomóc patologom wykrywać raka piersi szybciej i bardziej konsekwentnie, co potencjalnie daje pacjentom szybsze wyniki i skuteczniejsze opcje leczenia.
Bliższe spojrzenie na obrazy tkanki
Pod mikroskopem tkanka piersi nie dzieli się wyraźnie na „zdrową” i „nowotworową”. Komórki nakładają się na siebie, barwienie różni się między pracowniami, a subtelne zmiany kształtu lub tekstury mogą mieć znaczenie decydujące o życiu. Tradycyjne systemy komputerowo‑wspomagane miały trudności z taką złożonością, ponieważ inżynierowie musieli ręcznie definiować cechy, na które komputer powinien zwracać uwagę, a niewielkie zmiany w barwieniu lub jakości obrazu mogły je zmylić. Głębokie uczenie, gałąź sztucznej inteligencji ucząca się wzorców bezpośrednio z danych, niedawno zrewolucjonizowało sposób, w jaki komputery interpretują obrazy, w tym skany medyczne. Autorzy budują na tym postępie, projektując system dostosowany do nieuporządkowanej rzeczywistości preparatów tkankowych.
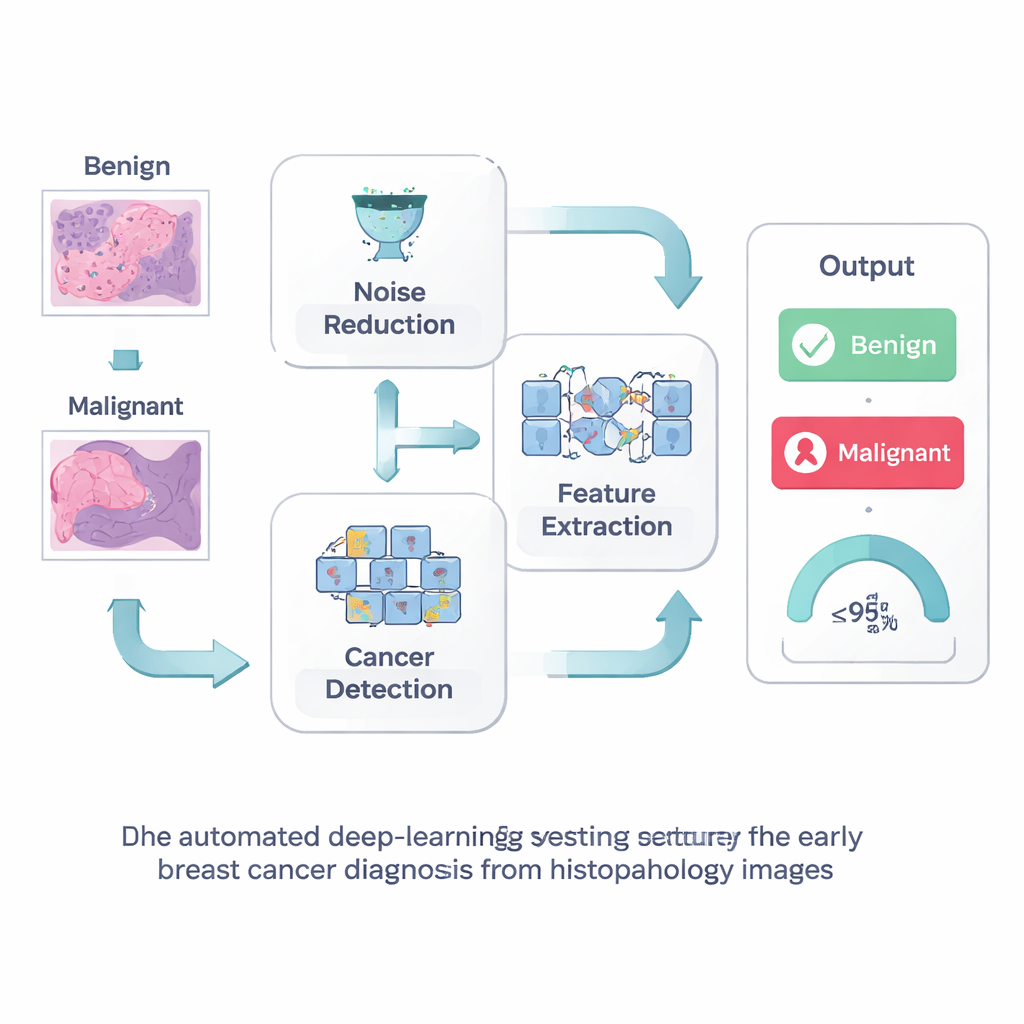
Oczyszczanie obrazu przed jego odczytem
Pierwszy krok w ich podejściu jest prosty, ale skuteczny: oczyścić obraz zanim poprosi się komputer o jego interpretację. Preparaty histopatologiczne często zawierają wizualny „szum” wynikający z procesu barwienia i obrazowania, który może zasłonić drobne struktury wskazujące wczesny rak. Badacze stosują technikę zwaną filtrowaniem Wienera, która wygładza losowe plamki, zachowując jednocześnie ostre krawędzie i drobne szczegóły, takie jak granice komórek czy małe skupiska. Przedstawiając komputerowi wyraźniejszy obraz, krok ten pomaga unikać zarówno przeoczeń nowotworów, jak i fałszywych alarmów kierujących pacjentów na niepotrzebne badania.
Nauczanie komputera, na co zwracać uwagę
Następnie zespół sięga po zaawansowany model głębokiego uczenia znany jako SE‑ResNet, aby analizować oczyszczone obrazy. Mówiąc prościej, model skanuje preparat kawałek po kawałku, stopniowo budując wewnętrzne „słownictwo” wzorców wizualnych: jak wyglądają normalne przewody, jak grupują się komórki nowotworowe i jak tekstury zmieniają się w miarę postępu choroby. Wbudowany mechanizm uwagi pomaga sieci podkreślić najbardziej informacyjne kanały obrazu i zredukować znaczenie nieistotnego tła. Dzięki temu model staje się bardziej wrażliwy na subtelne wzorce związane z chorobą, przy jednoczesnym utrzymaniu efektywności obliczeniowej pozwalającej na działanie na sprzęcie szpitalnym.
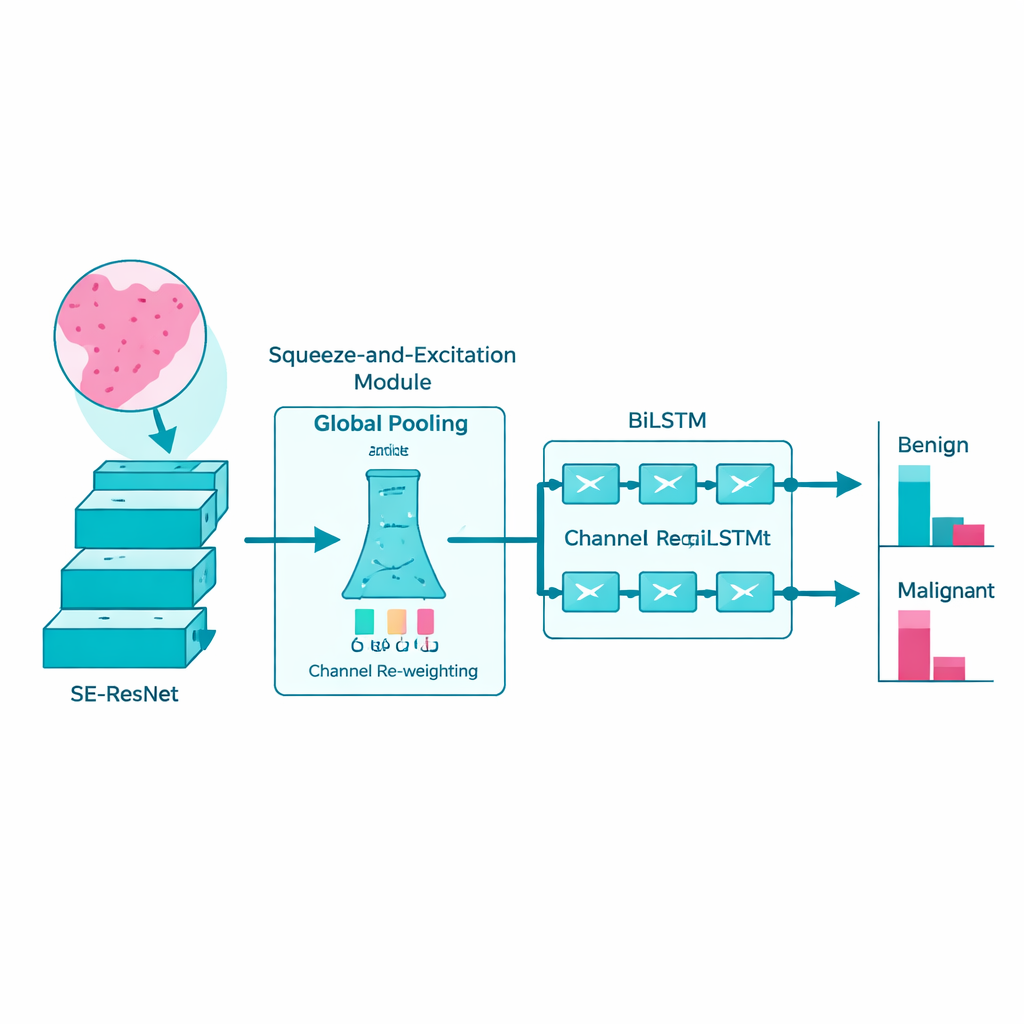
Śledzenie wzorców w przestrzeni jak opowieści
Zamiast traktować każdy fragment tkanki jako odizolowane ujęcie, badacze zauważają, że objawy choroby często rozwijają się jak opowieść na całym preparacie. Aby to uchwycić, podają cechy wyekstrahowane przez SE‑ResNet do dwukierunkowej sieci długiej krótkotrwałej pamięci, czyli BiLSTM. Ten typ modelu jest zaprojektowany do rozumienia sekwencji: analizuje, jak wzorce zmieniają się z regionu na region, zarówno w przód, jak i w tył, podobnie jak czytanie zdania w obu kierunkach, by uchwycić jego pełne znaczenie. Ucząc się tych przestrzennych relacji, BiLSTM lepiej rozróżnia zmiany łagodne od naprawdę złośliwych.
Jak dobrze system działa w praktyce
Autorzy przetestowali cały swój proces — redukcję szumu, uczenie cech i modelowanie sekwencji — na dużych publicznych zbiorach obrazów tkanki piersiowej, w tym powszechnie używanym zbiorze BreakHis. Podzielili dane na zbiory treningowe i testowe w różnych proporcjach i porównali swoją metodę z wieloma ustalonymi modelami głębokiego uczenia. W tych eksperymentach ich system poprawnie klasyfikował próbki jako łagodne lub złośliwe w niemal 99% przypadków, przewyższając konkurencyjne metody i działając przy tym szybciej. Model utrzymywał wysoką skuteczność przy różnych powiększeniach preparatu, co sugeruje zdolność adaptacji do slajdów przygotowanych w różnych warunkach. Jednak badanie wskazuje też ograniczenia: zbiory danych są wciąż umiarkowane rozmiarami, model skupia się na prostej decyzji dwuklasowej zamiast szczegółowej klasyfikacji podtypów guza i nie został jeszcze przetestowany w realnych przepływach pracy klinicznej.
Co to oznacza dla pacjentów i lekarzy
Dla osoby nieznającej tematu najważniejsza wiadomość jest taka, że komputery coraz lepiej czytają obrazy mikroskopowe tkanki piersiowej i wskazują podejrzane obszary. Proponowany system nie zastępuje patologa; działa raczej jak wyjątkowo uważny asystent, który podświetla rejony prawdopodobnie nowotworowe i dostarcza drugą opinię o bardzo wysokiej dokładności. Jeśli zostanie zwalidowany w większych i bardziej zróżnicowanych grupach pacjentek, takie narzędzia mogą skrócić czas do rozpoznania, zmniejszyć ryzyko przeoczenia małego nowotworu i pomóc przeciążonym szpitalom w obsłudze rosnącej liczby przypadków. Przyszłe prace będą musiały przetestować metodę na bardziej zróżnicowanych preparatach i zintegrować ją z rutyną laboratoriów, ale to badanie pokazuje, że starannie zaprojektowane systemy głębokiego uczenia mogą być potężnym sprzymierzeńcem w walce z rakiem piersi.
Cytowanie: Nagalakshmi, V., Ahammad, S.H. Leveraging medical imaging and deep learning for diagnosis of breast cancer using histopathological images. Sci Rep 16, 6236 (2026). https://doi.org/10.1038/s41598-026-37663-z
Słowa kluczowe: diagnostyka raka piersi, obrazy histopatologiczne, głębokie uczenie, obrazowanie medyczne, komputerowo wspomagana detekcja