Clear Sky Science · pl
Odcisk palca DNS oparty na aktywności użytkownika
Dlaczego twoje wizyty w sieci zostawiają ukryty ślad
Za każdym razem, gdy przeglądasz sieć, twój komputer po cichu pyta specjalny rodzaj książki adresowej, zwaną Systemem Nazw Domen (DNS), jak dojść do danej strony. Te zapytania nie znikają bez śladu. W ciągu dni i tygodni układają się w wzorce, które rodzaje stron odwiedzasz, kiedy i jak często. Artykuł pokazuje, że te wzorce są wystarczająco charakterystyczne, by działać jak odcisk behawioralny, pozwalając zaawansowanym algorytmom rozróżniać użytkowników — nawet gdy zmienia się ich widoczny adres IP — co stwarza zarówno możliwości dla bezpieczeństwa, jak i poważne pytania dotyczące prywatności.
Książka telefoniczna internetu i twoje nawyki
DNS służy do tłumaczenia czytelnych dla człowieka adresów internetowych, jak www.google.com, na numeryczne adresy IP, których komputery używają do komunikacji. Większość ludzi o tym nie myśli, ale każde wyszukiwanie, odtwarzanie wideo, sprawdzanie poczty czy aktualizacja aplikacji wyzwala jedno lub kilka zapytań DNS. Zapytania te zazwyczaj obsługują lokalne lub publiczne serwery DNS i są zapisywane jako proste rekordy: który adres IP pytał o którą domenę i kiedy. Zebrane w dostatecznej liczbie, te rekordy dają szczegółowy obraz, na jakich usługach online polega dany użytkownik — od narzędzi biznesowych i chmury po serwisy społecznościowe i platformy streamingowe. Podczas gdy wcześniejsze badania wykorzystywały takie ślady do wykrywania złośliwego oprogramowania lub identyfikacji typów urządzeń, to badanie stawia bardziej bezpośrednie pytanie: czy mogą one precyzyjnie zidentyfikować poszczególnych użytkowników lub maszyny wyłącznie na podstawie powtarzalnego zachowania DNS?
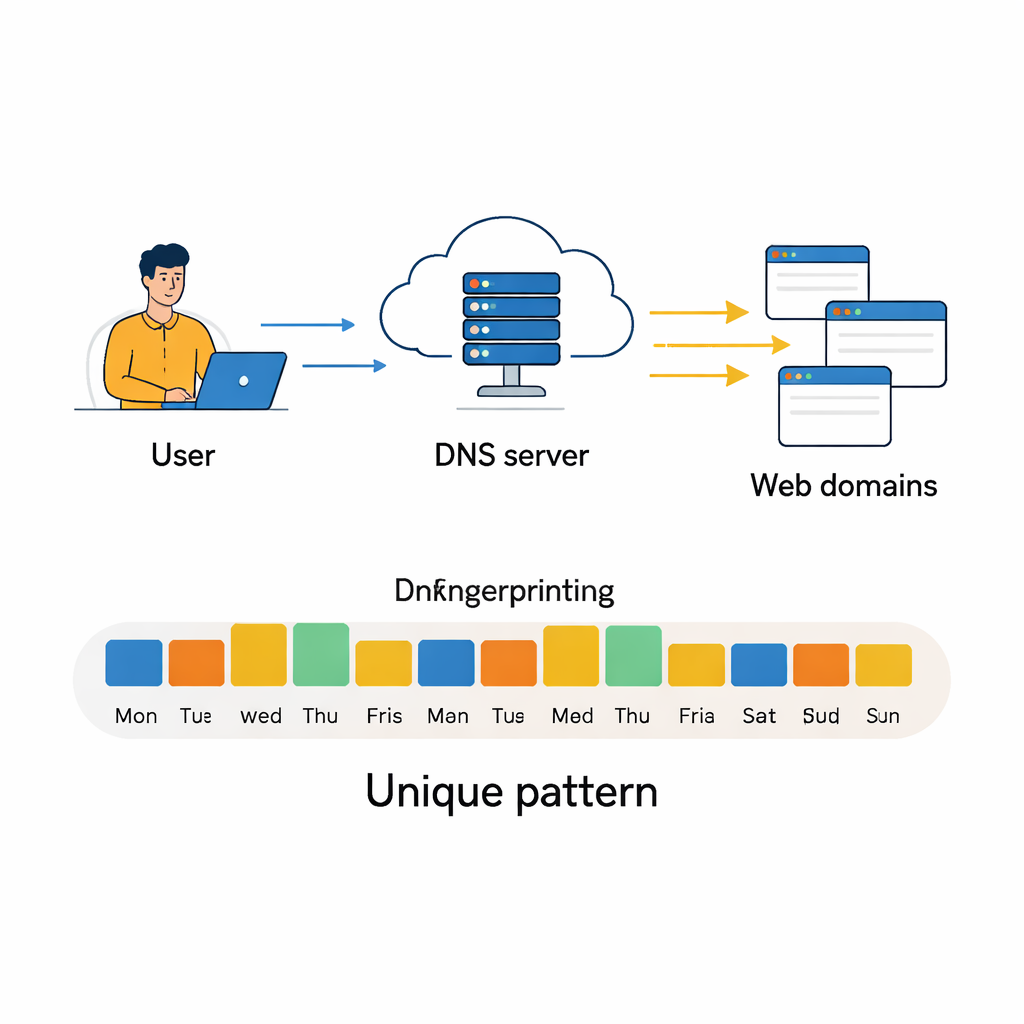
Przekształcanie codziennych kliknięć w odcisk behawioralny
Autorzy opierają się na dużym, publicznie dostępnym zbiorze danych DNS zebranym od lokalnego dostawcy internetu przez trzy miesiące. Codziennie agregują aktywność DNS dla każdego aktywnego adresu IP do zwartego podsumowania: liczby zapytań ogółem, ile różnych domen było sprawdzanych oraz, co kluczowe, jak te domeny rozkładają się w 75 kategoriach treści, takich jak „Biznes ogólny”, „Oprogramowanie / Sprzęt” czy „Serwisy społecznościowe”. Zachowują tylko adresy IP, które pojawiają się co najmniej w 80 procent dni, co zapewnia wystarczającą historię dla każdego użytkownika, i ostrożnie usuwają redundantne lub niemal puste cechy. Stosują też narzędzia statystyczne do wykrywania silnie skorelowanych pól, filtrują skrajne wartości w wolumenie zapytań, a następnie kompresują dane metodą analizy głównych składowych (PCA), tak aby większość użytecznej zmienności została zachowana w znacznie mniejszej liczbie wymiarów. Wizualizując oczyszczone dane techniką zwaną t‑SNE, stwierdzają, że wiele adresów IP tworzy zwarte, dobrze oddzielone klastry — wczesny sygnał, że automatyczna klasyfikacja może być wykonalna.
Testowanie modeli uczenia maszynowego
Mając przetworzony zbiór danych, zespół traktuje identyfikację użytkownika jako ogromny problem klasyfikacji: mając jedną dobę statystyk DNS, zdecydować, do którego z 1 727 adresów IP należy. Porównują zestaw modeli, od klasycznych metod jak Naiwny Bayes i Las Losowy (Random Forest) po bardziej zaawansowane narzędzia, takie jak XGBoost i głębokie sieci neuronowe. Każdy model jest trenowany i walidowany na różnych wersjach danych (surowe, przeskalowane, wystandaryzowane lub zredukowane wymiarowo) i oceniany na podstawie tego, jak często poprawnie przypisuje właściwą klasę, wraz z miarami precyzji i czułości. Modele tradycyjne radzą sobie całkiem nieźle — Random Forest osiąga około 73 procent trafności, a XGBoost przekracza 81 procent poprawnych klasyfikacji, prawidłowo rozróżniając ponad 99 procent wszystkich klas. Jednak wyróżniają się sieci neuronowe, zwłaszcza niestandardowa splotowa sieć neuronowa (CNN), która traktuje wektor cech jak jednowymiarowy obraz codziennego zachowania.
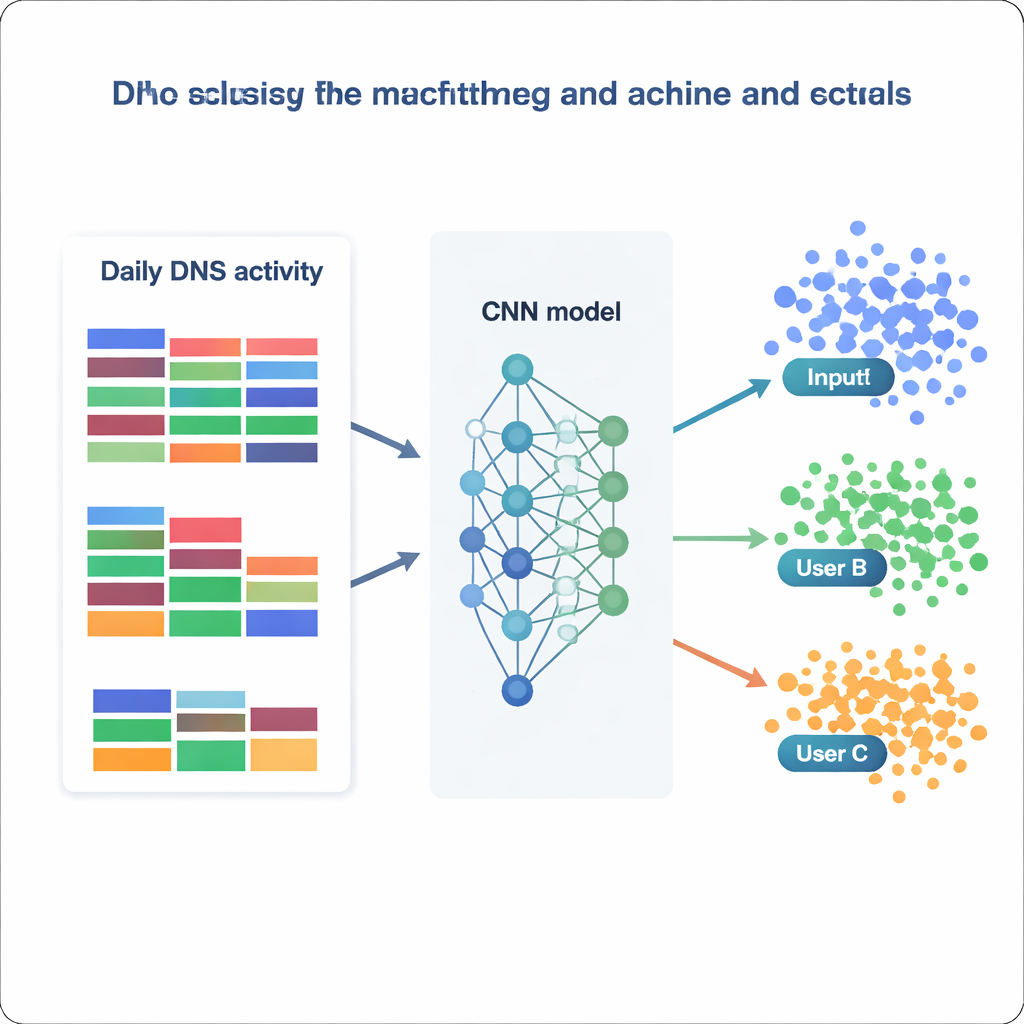
Jak dobrze model może wiedzieć „kim” jesteś?
Najlepszy CNN, trenowany na znormalizowanych danych, poprawnie identyfikuje źródłowy adres IP na prawie 87 procentach dni w zbiorze testowym i skutecznie przewiduje 1 694 z 1 727 odrębnych adresów IP. W praktyce oznacza to, że większość użytkowników — lub małe grupy ukrywające się za wspólnym adresem IP — wykazuje stabilne, rozpoznawalne wzorce DNS w czasie. Analizując, na jakich cechach modele opierają się najbardziej, autorzy wyróżniają dwie uzupełniające się strategie. Niektóre modele silnie wykorzystują bardzo powszechne kategorie, takie jak usługi biznesowe czy oprogramowanie, chwytając szerokie nawyki. Inne, jak XGBoost, zyskują dodatkową siłę dzięki rzadkim, lecz wymownym kategoriom związanym z bezpieczeństwem, polityką czy niszowymi zainteresowaniami. Razem wyniki te pokazują, że nawet proste, zgrupowane statystyki — bez analizy pełnej listy nazw domen — mogą zawierać wystarczającą strukturę, by zaskakująco wiarygodnie ponownie identyfikować użytkowników.
Obietnice, ograniczenia i stawka dla prywatności
Dla organów ścigania i obrońców sieci odciski DNS mogą stać się cennym narzędziem do śledzenia powracających przestępców, wykrywania skompromitowanych maszyn czy identyfikowania botnetów, które używają zmieniających się adresów IP, by unikać blokowania. Jednocześnie badanie podkreśla wyraźne ograniczenia: odciski DNS są najbardziej stabilne, gdy publiczny IP jest przypisany jednemu użytkownikowi, co jest bardziej realistyczne w nowoczesnych sieciach IPv6 niż w dzisiejszym świecie IPv4, gdzie wielu użytkowników dzieli jeden adres przez NAT. Częsta zmiana serwerów DNS lub korzystanie z publicznego Wi‑Fi również osłabia sygnał. Co najważniejsze, praca podkreśla ryzyko dla prywatności, które jest trudne do zauważenia przez zwykłych użytkowników. Ponieważ logowanie DNS jest w dużej mierze niewidoczne i pasywne, śledzenie behawioralne może zachodzić bez instalowania ciasteczek czy inwazyjnych skryptów. Autorzy udostępniają swój zbiór danych i modele otwarcie, argumentując, że przezroczyste badania są potrzebne, aby społeczeństwo mogło zważyć korzyści bezpieczeństwa płynące z odcisków DNS wobec ich potencjału do cichej inwigilacji i zdecydować, jakie zabezpieczenia i polityki powinny regulować tę potężną nową formę identyfikacji online.
Cytowanie: Morozovič, D., Konopa, M. & Fesl, J. DNS fingerprint based on user activity. Sci Rep 16, 7314 (2026). https://doi.org/10.1038/s41598-026-37631-7
Słowa kluczowe: odcisk palca DNS, śledzenie użytkownika, prywatność w internecie, bezpieczeństwo sieci, uczenie maszynowe