Clear Sky Science · pl
Superrozdzielczość twarzy w warunkach rzeczywistych oparta na generatywnych sieciach przeciwnikowych i sieciach do wyrównywania twarzy
Bardziej ostre twarze z rozmytych zdjęć
Każdy, kto próbował powiększyć twarz z starego nagrania z monitoringu lub maleńkiego zdjęcia z mediów społecznościowych, zna to uczucie: im bardziej powiększasz, tym bardziej twarz zamienia się w rozmazany blok pikseli. Artykuł przedstawia nowe podejście sztucznej inteligencji, które potrafi przekształcić takie niskiej jakości zdjęcia twarzy w znacznie wyraźniejsze obrazy, lepiej zachowując tożsamość i wyraz osoby. Ma to oczywiste zastosowania w kamerach bezpieczeństwa, kryminalistyce zdjęciowej, a także w aplikacjach do poprawiania codziennych fotografii.
Dlaczego rozmyte twarze trudno naprawić
Sprawienie, by mały, zamazany obraz twarzy wyglądał na ostry, to nie tylko „dodawanie pikseli”. Tradycyjne metody opierały się na regułach zaprojektowanych ręcznie lub prostych wzorcach, a nowsze techniki głębokiego uczenia często uczyły się na sztucznie zdegradowanych obrazach: bierze się czystą, wysokiej rozdzielczości twarz, rozmywa i zmniejsza ją, a następnie uczy sieć odwracać ten proces. Problem w tym, że obrazy ze świata rzeczywistego — na przykład z kamer monitoringu czy skompresowanego wideo — są zdegradowane w nieporządny, nieprzewidywalny sposób. Rozmycie, szum i artefakty kompresji rzadko odpowiadają uporządkowanym, syntetycznym przykładom używanym podczas treningu, więc modele, które świetnie wyglądają w laboratorium, często zawodzą na rzeczywistych nagraniach. Co gorsza, mogą generować twarze, które wydają się wiarygodne, ale przestają przypominać oryginalną osobę.
Dwukierunkowa pętla uczenia dla obrazów z rzeczywistości
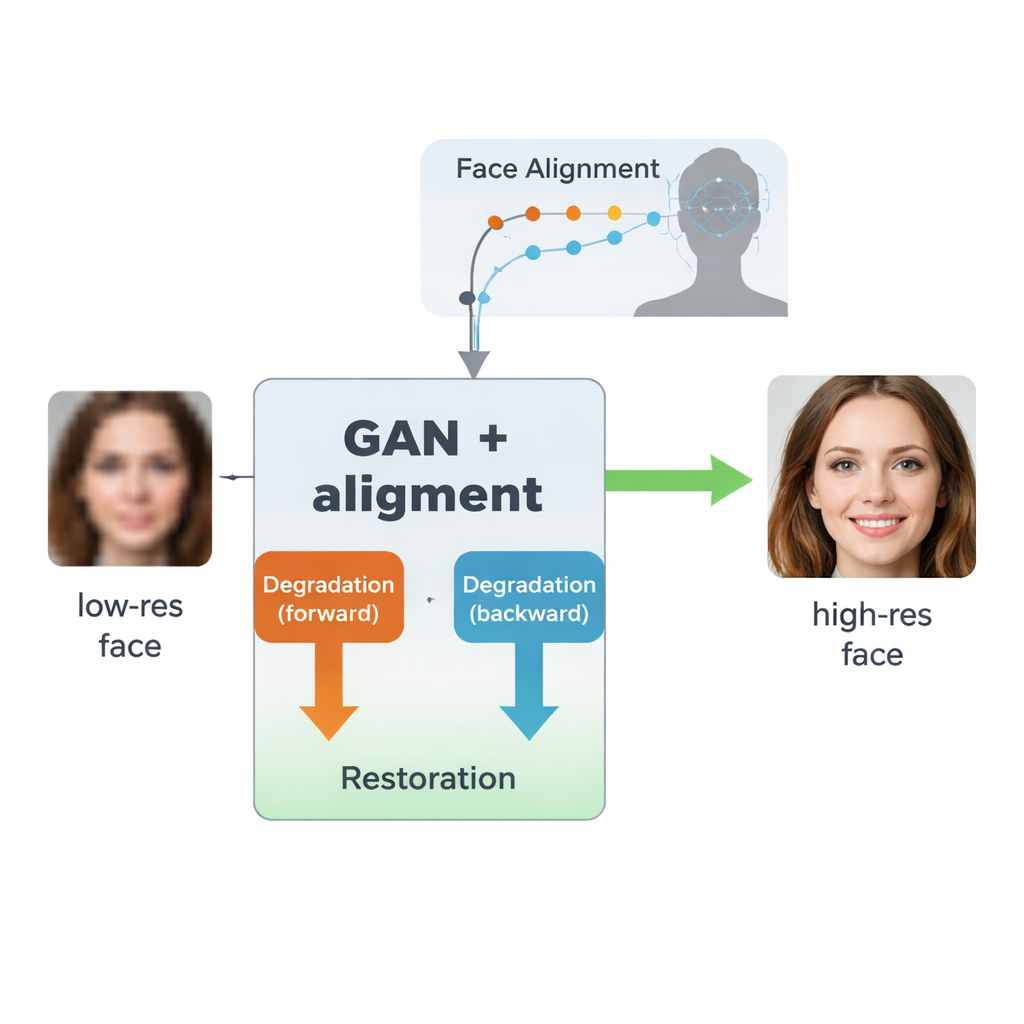
Autorzy budują na typie AI zwanym generatywną siecią przeciwnikową (GAN), która uczy się tworzyć realistyczne obrazy przez konfrontację dwóch sieci neuronowych: jedna generuje obrazy, druga ocenia ich wiarygodność. Ich konstrukcja, inspirowana wcześniejszym modelem SCGAN, używa struktury „pół-cyklu” z dwiema komplementarnymi pętlami. W pętli forward rzeczywiste twarze o wysokiej rozdzielczości są celowo degradawane przez jedną gałąź, aby uzyskać syntetyczne wersje niskiej rozdzielczości, a następnie przywracane przez wspólną gałąź restoracyjną. W pętli backward prawdziwe niskiej jakości twarze ze świata rzeczywistego są poprawiane przez tę samą gałąź restoracyjną, a następnie ponownie degradawane przez inną gałąź, aby przypominały prawdziwe obrazy niskiej rozdzielczości. Wymuszając spójność w obu kierunkach — degraduj, potem przywróć, lub przywróć, potem degraduj — system uczy się realistycznego modelu tego, jak twarze ulegają zniszczeniu w praktyce i jak odwrócić ten proces, nie potrzebując przy tym idealnie dopasowanych par obrazów niskiej i wysokiej jakości z prawdziwego świata.
Nauka, jak naprawdę wygląda twarz
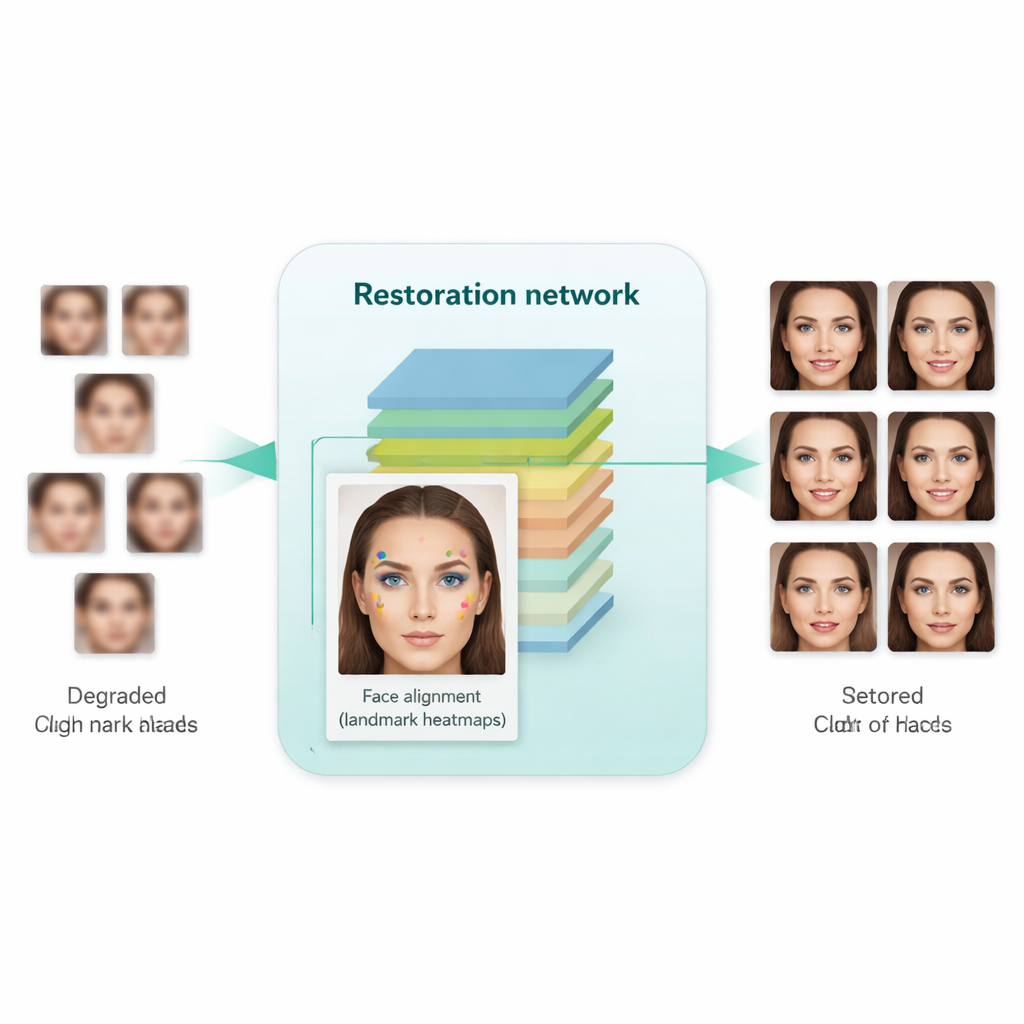
Kluczową innowacją w tej pracy jest nauczenie systemu nie tylko upiększania obrazu, ale respektowania podstawowej struktury ludzkiej twarzy. W tym celu autorzy integrują oddzielną sieć do wyrównywania twarzy, pierwotnie zaprojektowaną do lokalizowania punktów charakterystycznych takich jak kąciki oczu, koniuszek nosa czy kontur ust. Ta sieć wyrównująca przewiduje „mapy cieplne”, które podkreślają, gdzie każdy punkt powinien się znajdować. Podczas treningu model porównuje mapy cieplne z obrazu po przywróceniu z tymi z rzeczywistej, wysokiej rozdzielczości twarzy tej samej osoby i karze niezgodności. Co istotne, używa to wstępnie wytrenowanego modelu wyrównywania i nie wymaga ręcznego oznaczania punktów charakterystycznych dla każdego obrazu treningowego. Efektem jest swoisty przewodnik geometryczny: sieć poprawiająca jest popychana do umieszczania oczu, nosa i ust we właściwych pozycjach i kształtach, zamiast jedynie nakładać na rozmycie ogólne, przypominające twarz tekstury.
Jak dobrze to działa w praktyce?
Naukowcy trenowali swój system na dużym zbiorze twarzy wysokiej jakości oraz na oddzielnym zestawie autentycznie niskiej jakości twarzy pochodzących z rzeczywistych danych. Następnie testowali go zarówno na syntetycznych benchmarkach (gdzie dostępne są czyste obrazy referencyjne), jak i na obrazach ze świata rzeczywistego (gdzie można oceniać jedynie realizm wizualny i miary statystyczne). W porównaniu z wcześniejszymi metodami — w tym znanymi narzędziami jak Real-ESRGAN, GFPGAN i oryginalne SCGAN — nowe podejście wygenerowało obrazy, które nie tylko wyglądały bardziej naturalnie i mniej zniekształcone, lecz także poprawiły wyniki w praktycznych zadaniach. Po poprawieniu obrazy podawane do standardowych detektorów twarzy oraz popularnego modelu rozpoznawania twarzy (FaceNet) skutkowały zauważalnie lepszą wykrywalnością i weryfikacją, co sugeruje, że cechy istotne dla tożsamości zostały lepiej zachowane. Jednocześnie automatyczne miary jakości wskazywały, że wygenerowane twarze były bliższe rozkładowi rzeczywistych zdjęć wysokiej rozdzielczości.
Co to oznacza dla codziennego użytkowania
Mówiąc prosto, praca ta pokazuje, że można uzyskać ostrzejsze i bardziej wiarygodne twarze z obrazów niskiej jakości, łącząc dwie idee: nauczyć realistycznego modelu tego, jak obrazy ulegają zniszczeniu w rzeczywistości, oraz użyć informacji o punktach charakterystycznych twarzy, aby zachować jej strukturę. Zamiast jedynie „zgadywać” ładniej wyglądającą twarz, system zostaje poprowadzony do odtworzenia właściwej osoby z wyraźniejszymi oczami, ustami i ogólnym kształtem. Dzięki temu metoda wydaje się szczególnie obiecująca dla zastosowań w bezpieczeństwie, kryminalistyce i restaurowaniu archiwów, gdzie zarówno klarowność wizualna, jak i poprawna identyfikacja są kluczowe, a oryginalne wersje w wysokiej jakości rzadko są dostępne.
Cytowanie: Fathy, H., Faheem, M.T. & Elbasiony, R. Real-world face super-resolution based on generative adversarial and face alignment networks. Sci Rep 16, 7492 (2026). https://doi.org/10.1038/s41598-026-37573-0
Słowa kluczowe: superrozdzielczość twarzy, generatywne sieci przeciwnikowe, wyrównywanie twarzy, rozpoznawanie twarzy, restauracja obrazu