Clear Sky Science · pl
Potok przetwarzania obrazów do charakterystyki megabiblioteki nanocząstek sterowanej przez AI
Dlaczego maleńkie cząstki potrzebują pomocy wielkich zbiorów danych
Współczesna nauka o materiałach coraz częściej opiera się na wytwarzaniu i badaniu ogromnych ilości drobnych cząstek, by odkrywać lepsze katalizatory, ogniwa i inne zaawansowane materiały. Nowe metody pozwalają teraz wyhodować miliony różnych nanocząstek na jednym chipie, ale sprawdzanie jakości każdej z nich za pomocą mikroskopu generuje znacznie więcej obrazów, niż człowiek jest w stanie rozsądnie przejrzeć. Artykuł opisuje, jak badacze zbudowali zautomatyzowany potok przetwarzania obrazów i AI, który szybko rozdziela obrazy „dobre” od „złych”, zmniejszając koszty obliczeniowe i przyspieszając eksperymenty przy zachowaniu wysokiej wiarygodności decyzji.
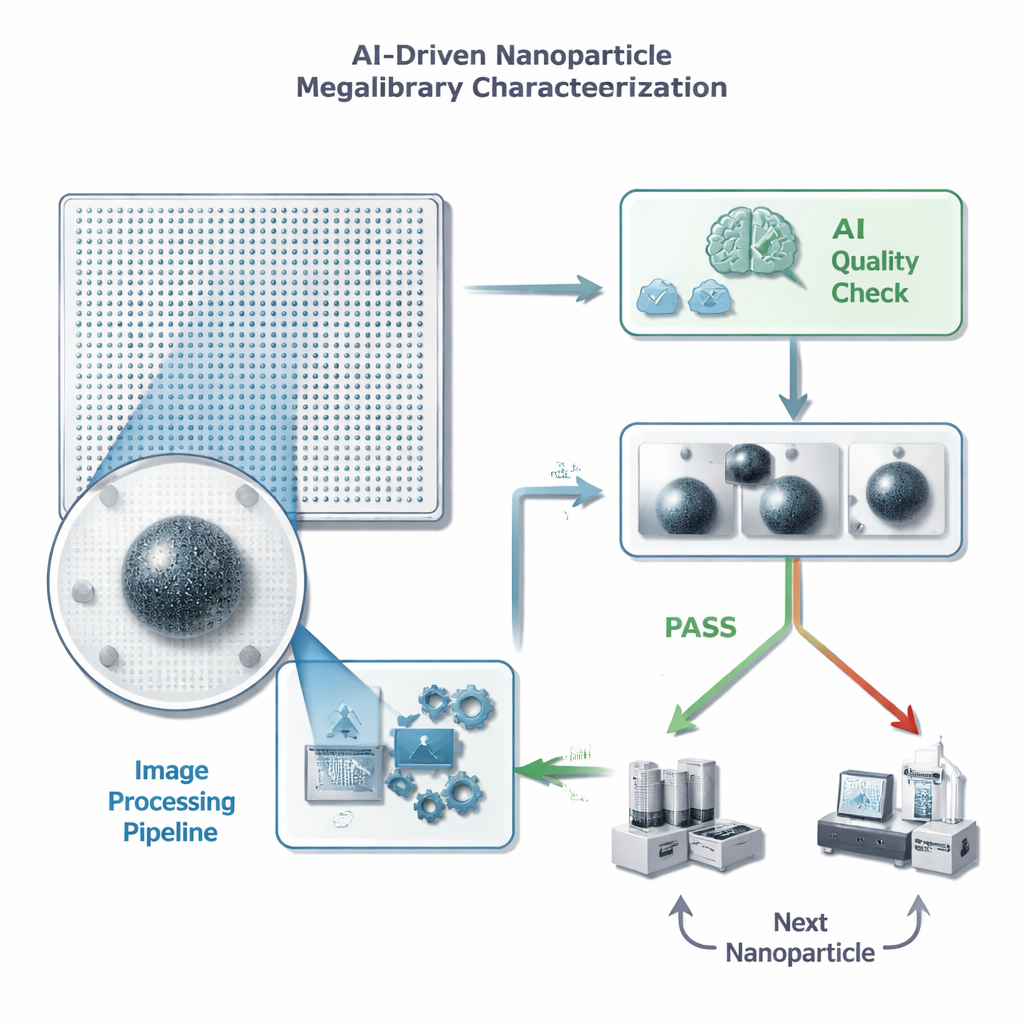
Z niekończących się obrazów do szybkich decyzji
Każda nanocząstka na chipie typu „megalibrary” znajduje się w znanym położeniu i można ją obrazować mikroskopem elektronowym. Zanim naukowcy zainwestują czas i kosztowne, pogłębione pomiary w dowolną cząstkę, potrzebna jest szybka kontrola jakości: czy w kadrze jest dokładnie jedna dobrze ostrzona cząstka, bez zakłócająych elementów lub artefaktów? Autorzy formułują to jako proste zadanie zalicz/odrzuć dla modelu uczenia maszynowego, ale z rygorystycznym ograniczeniem czasu na obraz — mniej niż pół sekundy, ponieważ pojedynczy chip może zawierać miliony cząstek. Podkreślają też, że fałszywe pozytywy są szczególnie szkodliwe: jeśli AI błędnie przepuści zły obraz, marnuje czas i miejsce na przechowywanie na bezwartościowe, szczegółowe pomiary, podczas gdy sporadyczne przeoczenie dobrej cząstki szkodzi postępowi w mniejszym stopniu.
Oczyszczanie obrazu zanim zajrzy AI
Zamiast wrzucać surowe, zaszumione obrazy mikroskopowe bezpośrednio do dużej, złożonej sieci neuronowej, zespół zaprojektował niestandardowy potok przetwarzania obrazu, który najpierw „oczyszcza” zdjęcia. Potok usuwa szumy tła, wyostrza krawędzie, przycina obraz ciasno wokół cząstki, a następnie zmniejsza jego rozdzielczość. Co kluczowe, to wstępne przetwarzanie uwydatnia słabe cechy i naśladuje wygląd obrazu o większym powiększeniu bez potrzeby ponownego obrazowania próbki. Efektem jest zwarty, o wysokim kontraście obraz, który można podać stosunkowo prostej sieci neuronowej, co skraca czas treningu i potrzeby pamięciowe, zachowując jednocześnie istotne szczegóły potrzebne do oceny jakości.
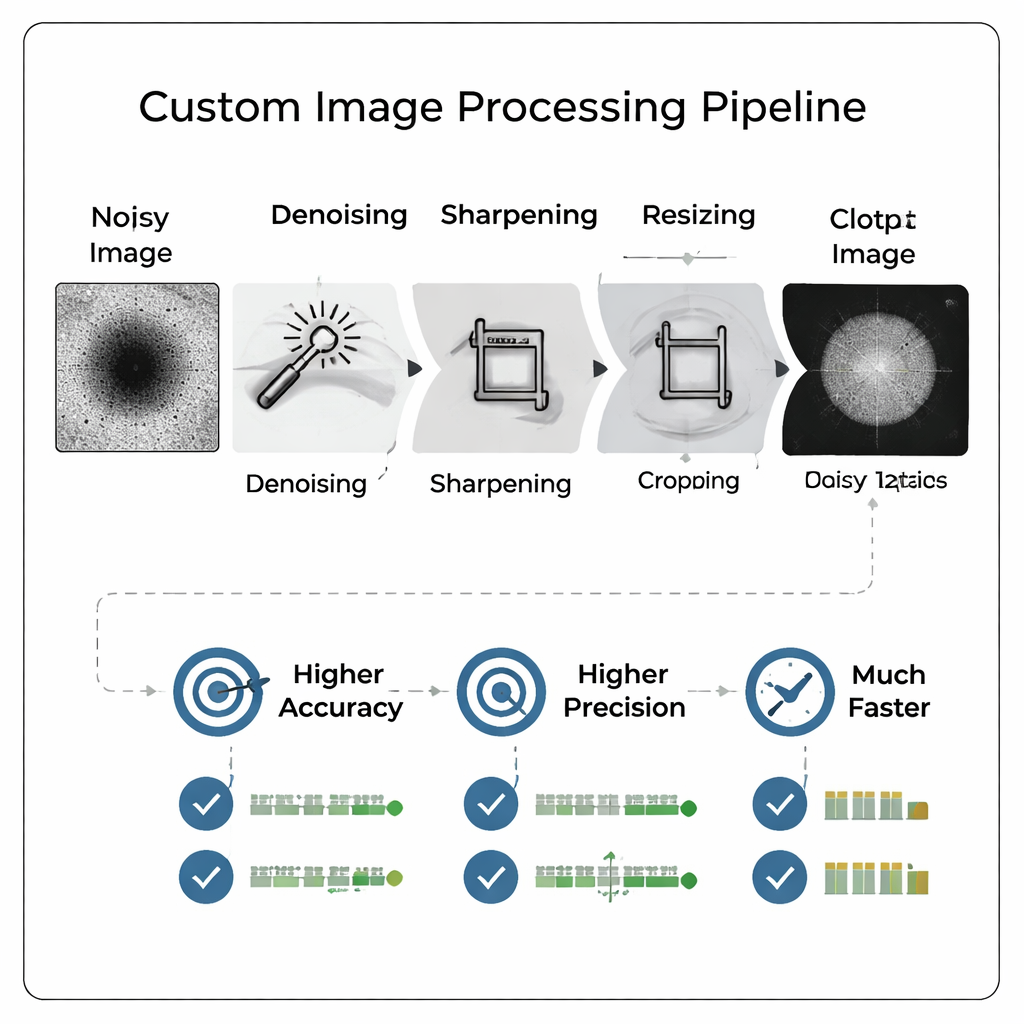
Inteligentniejsze obrazy przewyższają większe modele
Badacze rygorystycznie porównali wiele wariantów potoku i rozdzielczości, ostatecznie trenując 800 różnych modeli, by zbadać, jak rozmiar obrazu i przetwarzanie wpływają na wydajność. Odkryli, że starannie przetworzone obrazy o umiarkowanej rozdzielczości (np. 128×128 pikseli) pozwalają małej splotowej sieci neuronowej przewyższyć wcześniejszy, znacznie większy model znaleziony przez automatyczne wyszukiwanie architektury i trenowany na pełnych obrazach 512×512. Dokładność poprawiła się o ponad 13 punktów procentowych, podczas gdy czułość — zdolność do poprawnego wykrywania dobrych cząstek — wzrosła o ponad 18 punktów procentowych. Precyzja, kluczowy wskaźnik zapobiegający marnotrawstwu wysiłku na złe cząstki, osiągnęła około 96 procent, a preferowana przez autorów złożona miara wydajności również uległa poprawie.
Więcej osiągnięć przy znacznie mniejszej ilości danych
Jednym z najbardziej uderzających rezultatów jest to, że przetwarzanie ma większe znaczenie niż surowy rozmiar obrazu. Gdy zespół porównał modele trenowane na prostych obrazach jedynie „pomniejszonych” wobec tych korzystających z pełnego, niestandardowego potoku, obrazy przetworzone konsekwentnie wygrywały — nawet po zmniejszeniu do ekstremalnie małych rozmiarów, takich jak 16×16 pikseli. W rzeczywistości najlepszy model używający przetworzonych obrazów 16×16 pokonał najlepszy model używający nieprzetworzonych obrazów 128×128 we właściwie wszystkich metrykach. Potok okazał się też szczególnie pomocny przy niższych powiększeniach mikroskopu, gdzie obrazy są zwykle trudniejsze do interpretacji. Ponieważ obrazy przy niższym powiększeniu uzyskuje się szybciej, laboratoria mogą skanować chipy szybciej bez utraty jakości decyzji.
Szybsze decyzje dla zautomatyzowanych laboratorium
Łącząc inteligentne przetwarzanie obrazu z oszczędnym modelem AI, autorzy skrócili czas treningu z wielu godzin na superkomputerze do mniej niż minuty na pojedynczym procesorze graficznym. Po wytrenowaniu system potrafi przetworzyć i sklasyfikować nowy obraz w około 75 milisekund, znacznie poniżej celu 500 milisekund i dużo szybciej niż człowiek. W praktyce przekłada się to na szybkie, niezawodne przesiewanie megabibliotek nanocząstek, pomagając badaczom skoncentrować kosztowne przyrządy na najbardziej obiecujących kandydatów. W miarę jak laboratoria zmierzają ku bardziej zautomatyzowanym, „samosterującym” systemom odkryć, podejścia takie jak to — najpierw oczyszczanie danych, potem zastosowanie odchudzonego AI — oferują potężny sposób przekształcania przytłaczających strumieni obrazów w praktyczną wiedzę naukową.
Cytowanie: Day, A.L., Wahl, C.B., dos Reis, R. et al. Image processing pipeline for AI-driven nanoparticle megalibrary characterization. Sci Rep 16, 7675 (2026). https://doi.org/10.1038/s41598-026-37566-z
Słowa kluczowe: nanocząstki, przetwarzanie obrazów, uczenie maszynowe, odkrywanie materiałów, mikroskopia elektronowa