Clear Sky Science · pl
Badania nad modułami poprawiającymi korelacje etykiet w głębokim uczeniu wieloetykietowym plug-and-play
Nauczanie maszyn radzenia sobie z nadmiarem tagów
Sklepy internetowe, archiwa prawne i bazy medyczne opierają się na oprogramowaniu, które szybko oznacza każdy nowy dokument odpowiednimi etykietami. Nowoczesne systemy często jednak mierzą się z dziesiątkami tysięcy, a nawet milionami możliwych tagów — od kategorii produktów po dziedziny medyczne — podczas gdy każdy tekst potrzebuje tylko kilku z nich. W artykule wprowadzono nowy dodatek, nazwany Label Correlation Enhancement Network (LCENet), który pomaga istniejącym modelom głębokiego uczenia lepiej wykorzystać rzeczywiste współwystępowanie etykiet, co skutkuje bardziej precyzyjnym i szybszym oznaczaniem tekstów.
Dlaczego etykietowanie w skali sieci jest tak trudne
Wiele zastosowań w praktyce wpisuje się w to, co badacze nazywają ekstremalną klasyfikacją tekstu wieloetykietowego: mając krótką notkę lub długi dokument, system musi wybrać niewielki podzbiór trafnych etykiet z ogromnego katalogu. Przykłady to przypisywanie kategorii produktom w e‑commerce, indeksowanie artykułów biomedycznych terminami MeSH, dobieranie reklam do stron internetowych czy mapowanie tekstów prawnych do szczegółowych kodów. Te zadania łączy trzy wyzwania: lista etykiet jest niezwykle długa, większość etykiet występuje rzadko, a dowolny tekst używa tylko kilku etykiet. Tradycyjne techniki albo dzielą problem na wiele małych klasyfikatorów, albo kompresują etykiety do niższych wymiarów, lecz często opierają się na prostych zliczeniach słów i nie są w stanie w pełni uchwycić znaczenia ani relacji między etykietami.
Czego nadal brakuje standardowym modelom głębokim
Nowoczesne podejścia z zakresu głębokiego uczenia, takie jak sieci konwolucyjne, rekurencyjne czy modele typu Transformer jak BERT, znacznie poprawiły rozumienie tekstu przez uczenie bogatych reprezentacji semantycznych. Jednak niemal wszystkie z nich dokonują kluczowego uproszczenia na etapie końcowym: po zakodowaniu tekstu do wektora przewidują każdą etykietę niezależnie. W praktyce etykiety silnie na siebie oddziałują. Artykuł medyczny oznaczony jako „cukrzyca” częściej będzie też dotyczył „insulinooporności”, a gadżet oznaczony jako „smartfon” zwykle wiąże się z „elektroniką” i „urządzeniami komunikacyjnymi”. Ignorowanie tych wzorców uniemożliwia modelom wykorzystanie etykiet o wysokim zaufaniu do wspierania słabszych i może prowadzić do kombinacji etykiet, które nie mają sensu razem.
Wtyczka, która uczy się relacji między etykietami
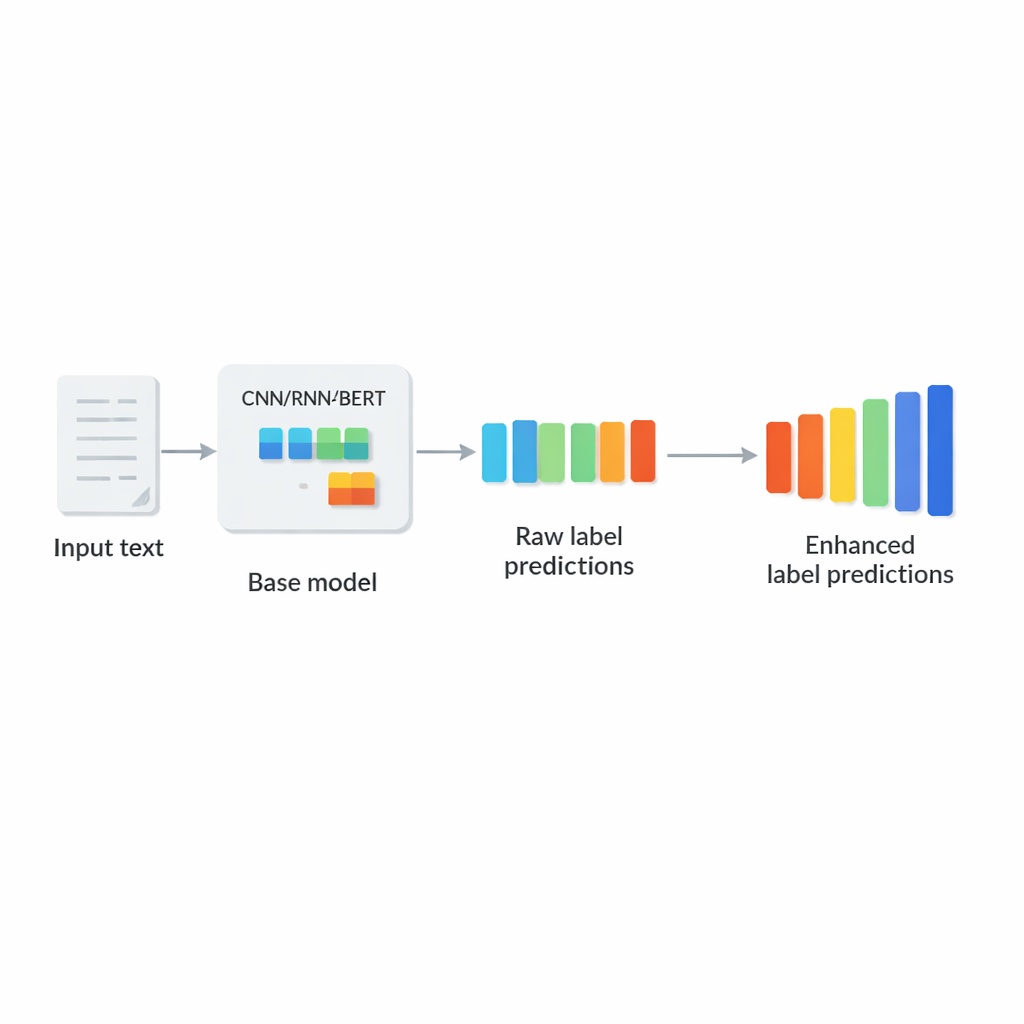
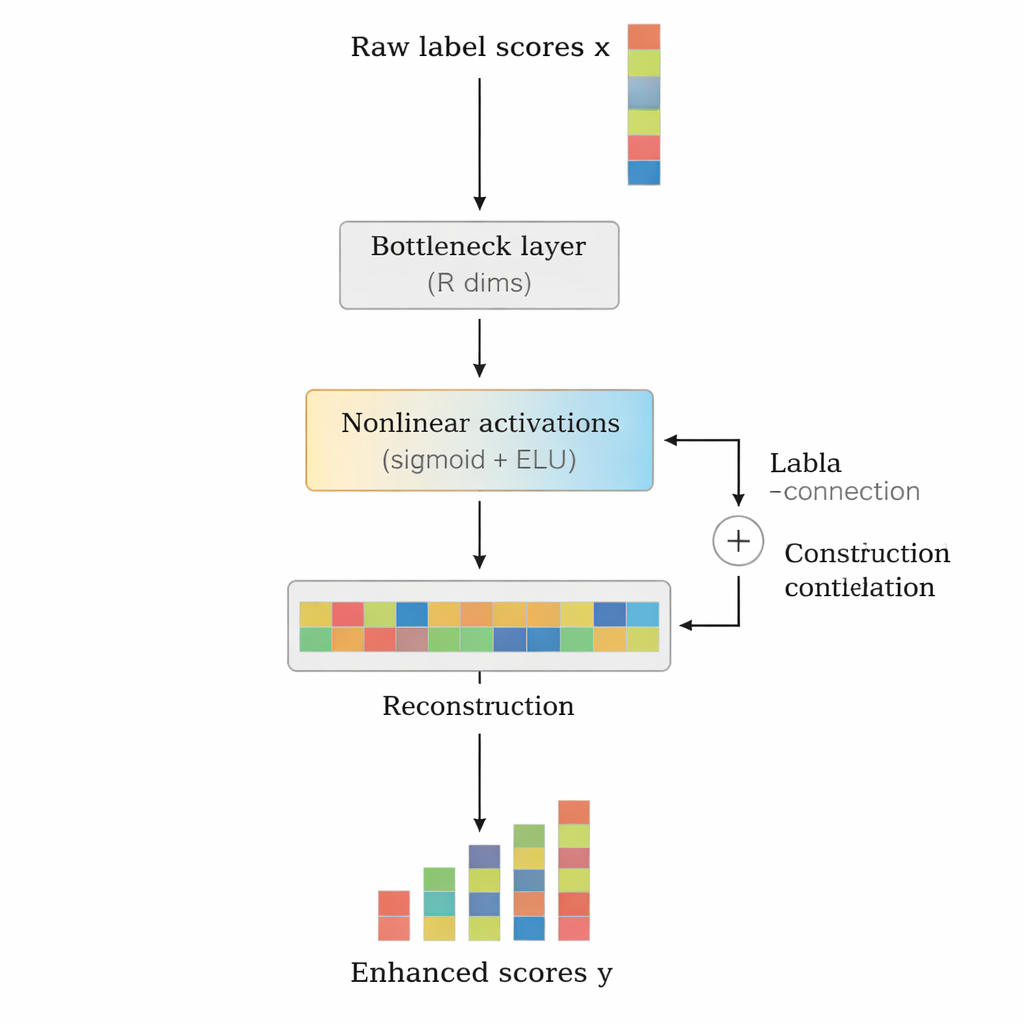
Autorzy proponują LCENet jako lekkie, plug-and-play moduł umieszczany za istniejącym klasyfikatorem tekstu. Zamiast zmieniać sposób, w jaki model bazowy czyta tekst, LCENet przyjmuje surowe wyniki dla etykiet, które generuje, i przeprowadza je przez zwartą „butelkę” (bottleneck), zmuszając system do odkrycia niskowymiarowej reprezentacji, w której powiązane etykiety grupują się razem. Nieliniowe funkcje aktywacji pozwalają modułowi uchwycić złożone, wyższych rzędów zależności, nie tylko proste powiązania parami. Połączenie rezydualne (skip connection) przesyła oryginalne wyniki bezpośrednio do wyjścia obok skorygowanych, co stabilizuje uczenie i zapewnia, że dodatek nie zepsuje łatwo działania. Co istotne, LCENet zmniejsza liczbę dodatkowych parametrów z takiej, która rosłaby w kwadracie liczby etykiet, do dużo bardziej przystępnego wzrostu liniowego, dzięki czemu pozostaje wykonalny nawet przy setkach tysięcy etykiet.
Udowadnianie korzyści na różnych modelach i zbiorach
Aby sprawdzić, czy LCENet jest naprawdę uniwersalny, autorzy podłączyli go do czterech różniących się znacznie modeli głębokich, w tym architektur opartych na CNN i BERT, a także systemów zaprojektowanych specjalnie do zadań biomedycznych i ekstremalnej liczby etykiet. Kombinacje te oceniono na trzech publicznych benchmarkach: europejskim korpusie prawnym (EUR-Lex), zbiorze produktów Amazon (AmazonCat-13K) oraz ogromnej kolekcji Wikipedii z ponad pół miliona etykiet (Wiki-500K). We wszystkich modelach, na wszystkich zbiorach i w sześciu metrykach skupionych na rankingach LCENet konsekwentnie poprawiał wyniki, czasem podnosząc precyzję top‑1 o ponad pięć punktów procentowych na największym zbiorze. Krzywe uczenia pokazały także, że LCENet często skraca liczbę kroków treningowych potrzebnych do osiągnięcia danej dokładności niemal o połowę, ponieważ dodana struktura korelacji etykiet zapewnia wyraźniejsze sygnały uczenia od samego początku.
Dlaczego to ma znaczenie dla systemów codziennego użytku
Dla praktyków, którzy już opierają oznaczanie tekstów na modelach głębokich, LCENet oferuje praktyczny sposób na poprawę dokładności i szybkości treningu bez przeprojektowywania systemów czy zbierania nowych rodzajów adnotacji. Traktuje przestrzeń etykiet jako źródło wiedzy — uczy się, które tagi mają tendencję do współwystępowania lub wzajemnego wykluczania się — i odpowiednio koryguje przewidywania. Chociaż opracowano go dla tekstu, ta sama idea ulepszania przewidywań za pomocą nauczonych relacji między wyjściami może być zastosowana do obrazów, danych multimodalnych i innych zadań przewidywań strukturalnych. Mówiąc prościej, LCENet pomaga maszynom „pamiętać”, jak etykiety się odnoszą do siebie, dzięki czemu przewidują mniej jak odrębne pola wyboru, a bardziej jak kompetentny człowiek rozumiejący, jak pojęcia się łączą.
Cytowanie: Zhang, J., Yuan, C. & Li, X. Research on plug-and-play correlation enhancement modules in deep multi-label learning. Sci Rep 16, 6788 (2026). https://doi.org/10.1038/s41598-026-37565-0
Słowa kluczowe: ekstremalna klasyfikacja tekstu wieloetykietowego, korelacja etykiet, głębokie uczenie, klasyfikacja tekstu, sieci neuronowe