Clear Sky Science · pl
DMSCA: dynamic multi-scale channel-spatial attention for enhanced feature representation in convolutional neural networks
Nauczanie komputerów lepszego zwracania uwagi
Nowoczesne systemy rozpoznawania obrazów potrafią wykrywać koty, znaki drogowe czy guzy na skanach — ale nie zawsze wiedzą, na czym w obrazie warto się skupić. W artykule przedstawiono nowe podejście, które pomaga tym systemom koncentrować się na najważniejszych fragmentach obrazu, poprawiając dokładność i zwiększając niezawodność w trudnych, rzeczywistych warunkach. Metoda, nazwana Dynamic Multi-Scale Channel-Spatial Attention (DMSCA), wpinana jest w istniejące splotowe sieci neuronowe i pozwala im inteligentniej rozumieć zarówno „co” się znajduje na obrazie, jak i „gdzie”.
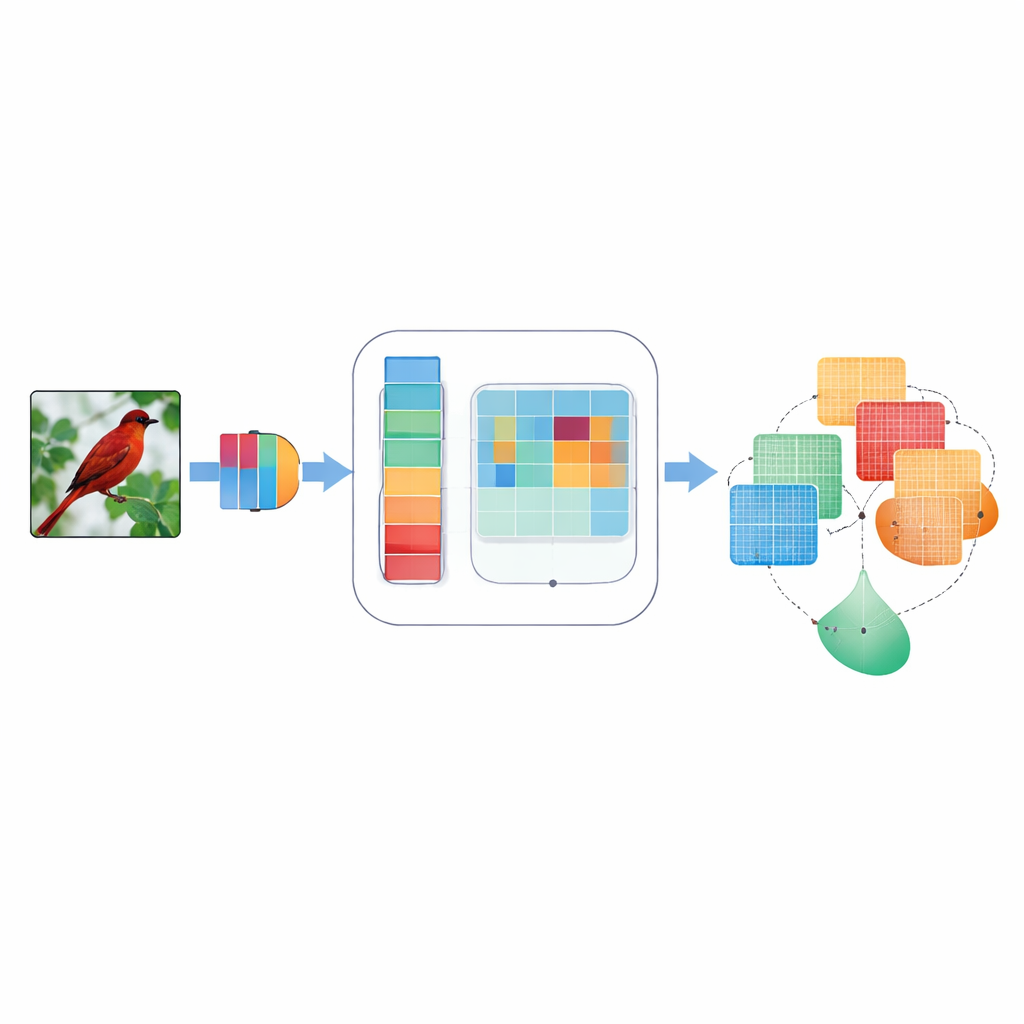
Dlaczego koncentracja uwagi ma znaczenie dla widzenia maszynowego
Splotowe sieci neuronowe, będące filarem wielu zastosowań w przetwarzaniu obrazu, zazwyczaj traktują wszystkie sygnały wewnętrzne jako jednakowo istotne. Oznacza to, że ledwie widoczny kontur skrzydła ptaka i skrawek nieba mogą otrzymać podobną wagę, choć tylko jeden z nich pomaga rozpoznać gatunek. Wcześniejsze metody „uwagi” próbowały to naprawić, ważając niektóre sygnały bardziej niż inne — albo wzdłuż kanałów przypominających kolory, albo w przestrzennym układzie dwuwymiarowym obrazu. Jednak tamte podejścia często opierały się na stałych, ręcznie zaprojektowanych regułach, analizowały tylko jedną skalę szczegółów lub łączyły informacje w sztywny sposób, nieprzystosowujący się do różnych obrazów. W efekcie bywały podatne na pomijanie drobnych detali, ignorowanie kierunków takich jak „poziomo kontra pionowo” lub problemy przy szumie i rozmyciu obrazu.
Sprytniejszy moduł uwagi
DMSCA zaprojektowano jako mały, dołączany moduł, który można wstawić do znanych sieci neuronowych, takich jak ResNet, bez zmiany ich ogólnej struktury. Wewnątrz koordynuje on sześć ściśle powiązanych części, które pracują razem zamiast osobno. Jedna część podsumowuje cały obraz, by uchwycić charakterystyki globalne, podczas gdy inna uczy się, jak mocno powinien liczyć się każdy kanał wewnętrzny, stosując kontrolowaną „temperaturę”, która może zaostrzać lub łagodzić decyzje w zależności od potrzeby. Po stronie przestrzennej DMSCA używa kilku rozmiarów okien jednocześnie, aby wychwycić zarówno drobne tekstury, jak i większe kształty, i wyraźnie zwraca uwagę na kierunki poziome i pionowe, żeby długie krawędzie czy pasy nie zostały rozmyte. Wreszcie, zamiast po prostu sumować te sygnały, moduł uczy się, piksel po pikselu, ile ufać informacjom „co” płynącym z kanałów w stosunku do informacji „gdzie” płynących z przestrzeni.
Analiza obrazu w wielu skalach i kierunkach
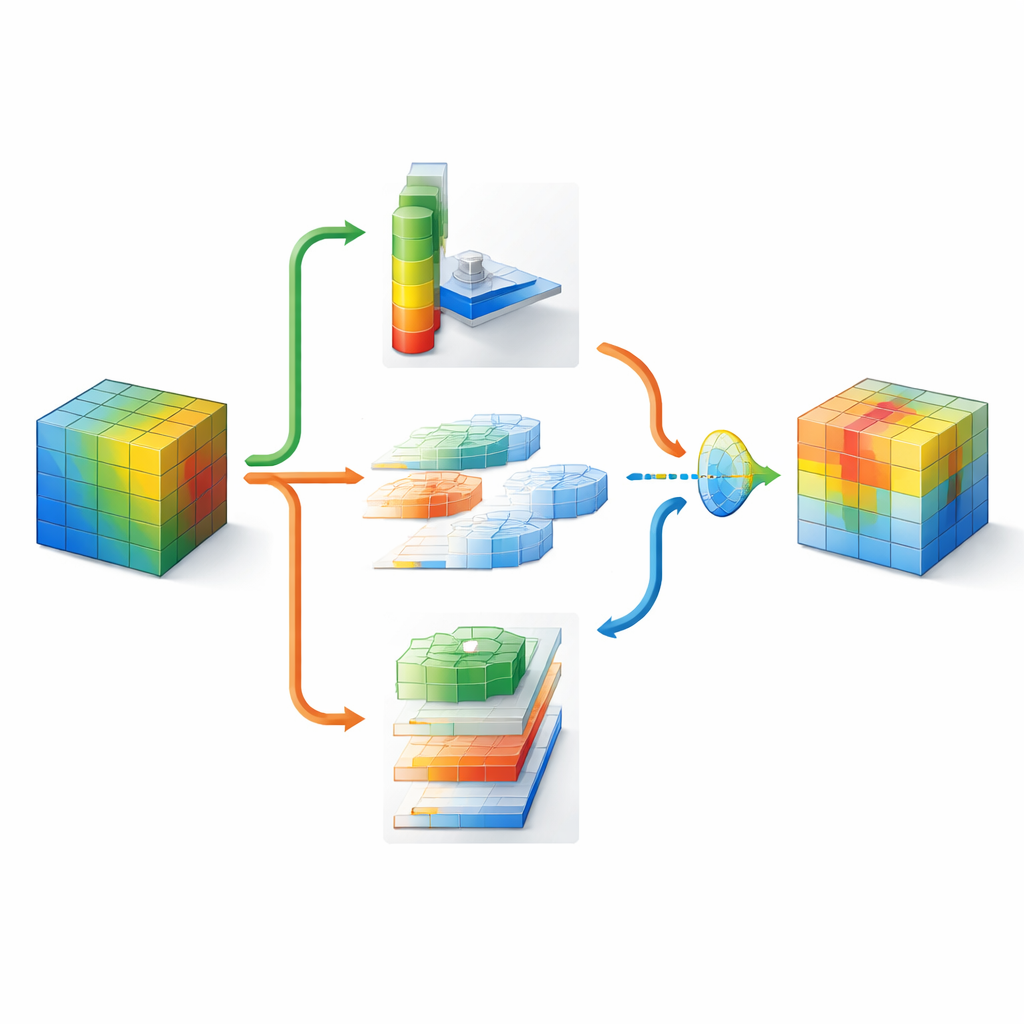
Aby określić, gdzie patrzeć na obrazie, DMSCA najpierw kompresuje wiele kanałów wewnętrznych do zwartej, dwuwarstwowej mapy, która podkreśla zarówno tło, jak i wyróżniające się cechy. Następnie przepuszcza tę mapę przez kilka równoległych filtrów o różnych rozmiarach. Małe filtry rozpoznają drobne detale, takie jak futro czy pióra, podczas gdy większe wychwytują kształty, np. całe głowy czy sylwetki. Równolegle, jednostka kierunkowa skanuje oddzielnie wzdłuż wierszy i kolumn, zachowując dokładne położenie istotnych struktur. Te poziome i pionowe widoki mogą następnie ze sobą współdziałać, tak że silny sygnał pionowy na przykład może wzmocnić odpowiednie lokalizacje poziome. W rezultacie powstaje bogata mapa uwagi, która mówi sieci nie tylko, że coś jest ważne, ale też gdzie się znajduje i w jakiej skali.
Pozwalając sieci zdecydować, co jest najważniejsze
Ponieważ różne części obrazu mogą wymagać różnych strategii, DMSCA nie narzuca stałego przepisu na łączenie informacji kanałowych i przestrzennych. Zamiast tego buduje małą „bramkę”, która analizuje oba rodzaje informacji i decyduje — niezależnie dla każdego piksela — jaką wagę przypisać każdemu z nich. W zagraconym tle system może bardziej polegać na wyróżniających się kanałach, podczas gdy przy ostrych krawędziach obiektów może podkreślać wskazówki przestrzenne. Końcowy etap adaptacyjnej aktywacji działa jak wyuczone ściemnianie: wzmacnia naprawdę informacyjne obszary i przygładza pozostały szum. Ten wieloetapowy proces pomaga kierować uwagę sieci ku spójnym, związanym z obiektami regionom, co potwierdzają zarówno wizualne mapy cieplne, jak i miary ilościowe dopasowania wyróżnionych obszarów do obiektów z danych referencyjnych.
Ostrość widzenia za umiarkowany koszt
Autorzy przetestowali DMSCA na kilku standardowych zestawach testowych, od niewielkich kolekcji malutkich obrazów po dużą bazę ImageNet. Po dodaniu do popularnych modeli ResNet, DMSCA konsekwentnie poprawiał dokładność klasyfikacji — o maksymalnie około 2 punkty procentowe w małych zbiorach i 1,5 punktu procentowego na ImageNet — przewyższając szereg istniejących metod uwagi. Zwiększał też odporność modeli na typowe degradacje obrazu, takie jak szum, rozmycie czy silna kompresja, oraz poprawiał wyniki w powiązanych zadaniach, takich jak wykrywanie obiektów czy etykietowanie scen. Te korzyści występowały przy jedynie umiarkowanym wzroście zapotrzebowania obliczeniowego i pamięciowego. Mówiąc prościej: DMSCA daje sieciom splotowym bardziej elastyczny i uwzględniający kontekst sposób decydowania, na co patrzeć, a na co nie zwracać uwagi — przybliżając widzenie maszynowe do selektywnej uwagi wzroku ludzkiego.
Cytowanie: Zong, L., Nan, S.J., Die, Z.F. et al. DMSCA: dynamic multi-scale channel-spatial attention for enhanced feature representation in convolutional neural networks. Sci Rep 16, 8044 (2026). https://doi.org/10.1038/s41598-026-37546-3
Słowa kluczowe: mechanizmy uwagi, rozpoznawanie obrazów, splotowe sieci neuronowe, reprezentacja cech, odporna wizja komputerowa