Clear Sky Science · pl
Ulepszanie wyszukiwania międzymodalnego poprzez optymalizację grafu etykiet i hybrydowe funkcje straty
Smutniejsze i mądrzejsze przeszukiwanie obrazów i słów
Każdego dnia przewijamy oceany zdjęć, filmów i tekstów. Znalezienie dokładnie tego, czego szukamy — na przykład wszystkich obrazów pasujących do krótkiego podpisu — zależy od tego, jak dobrze komputery potrafią powiązać obrazy z językiem. Artykuł ten bada nowy sposób, by uczynić to powiązanie bardziej precyzyjnym, szczególnie w złożonych, rzeczywistych scenach, gdzie pojawia się wiele pomysłów i obiektów jednocześnie. Efekt to inteligentniejsze narzędzia wyszukiwania, które lepiej „rozumieją” nasze intencje, a nie tylko dosłowne słowa.
Dlaczego wiele znaczeń na jednym obrazie ma znaczenie
Pojedyncze zdjęcie rzadko pokazuje tylko jedną rzecz. Fotografia wieloryba wyskakującego z oceanu może jednocześnie obejmować morze, niebo, fale, wiatr i dziką przyrodę. Przy oznaczaniu takiego obrazu często przypisujemy kilka etykiet powiązanych w subtelny sposób. Istniejące systemy wyszukiwania zwykle traktują te etykiety jak niepowiązane pola wyboru. Takie uproszczenie pozbawia nas użytecznych wskazówek: jeśli „wieloryb” często występuje z „morzem”, pojawienie się jednego powinno zwiększać prawdopodobieństwo drugiego. Praca ta koncentruje się na uchwyceniu tych ukrytych powiązań między etykietami, tak aby wyszukiwanie jednego pojęcia mogło znaleźć obrazy i teksty wyrażające pojęcia blisko spokrewnione.

Budowanie sieci powiązanych etykiet
Autorzy wprowadzają technikę nazwaną Dwuwarstwową Grafową Siecią Splotową, czyli L2-GCN, do modelowania relacji między etykietami. Mówiąc prościej, każdą etykietę (taką jak „niebo” czy „wieloryb”) traktuje się jako punkt w sieci, a krawędzie między punktami odzwierciedlają, jak często te etykiety występują razem. Metoda wielokrotnie pozwala każdej etykiecie „słuchać” sąsiadów, łącząc informacje od powiązanych etykiet przy jednoczesnym zachowaniu własnej tożsamości. Po tym procesie system uzyskuje bogatsze opisy etykiet, które lepiej oddają strukturę rzeczywistych scen — od równorzędnych pojęć („morze” i „plaża”) po bardziej hierarchiczne („zwierzę” i „wieloryb”).
Nauczanie obrazów i tekstów wspólnej przestrzeni
Oczywiście etykiety to tylko połowa historii; system musi także uczyć się z samych obrazów i tekstów. Ramy wykorzystują ustalone narzędzia do przekształcania surowych pikseli i słów w cechy numeryczne, a następnie umieszczają oba typy danych w wspólnej przestrzeni, gdzie ich znaczenia mogą być bezpośrednio porównywane. Moduł adwersarialny — luźno inspirowany mechaniką generatywnych sieci przeciwstawnych — zniechęca model do przywiązywania się do osobliwości samych obrazów lub tekstów. Dzięki temu wspólna przestrzeń skupia się na treści zamiast na formacie, dzięki czemu obraz zatłoczonej ulicy i krótki podpis go opisujący znajdują się blisko siebie w tym wspólnym „mapowaniu” znaczeń.
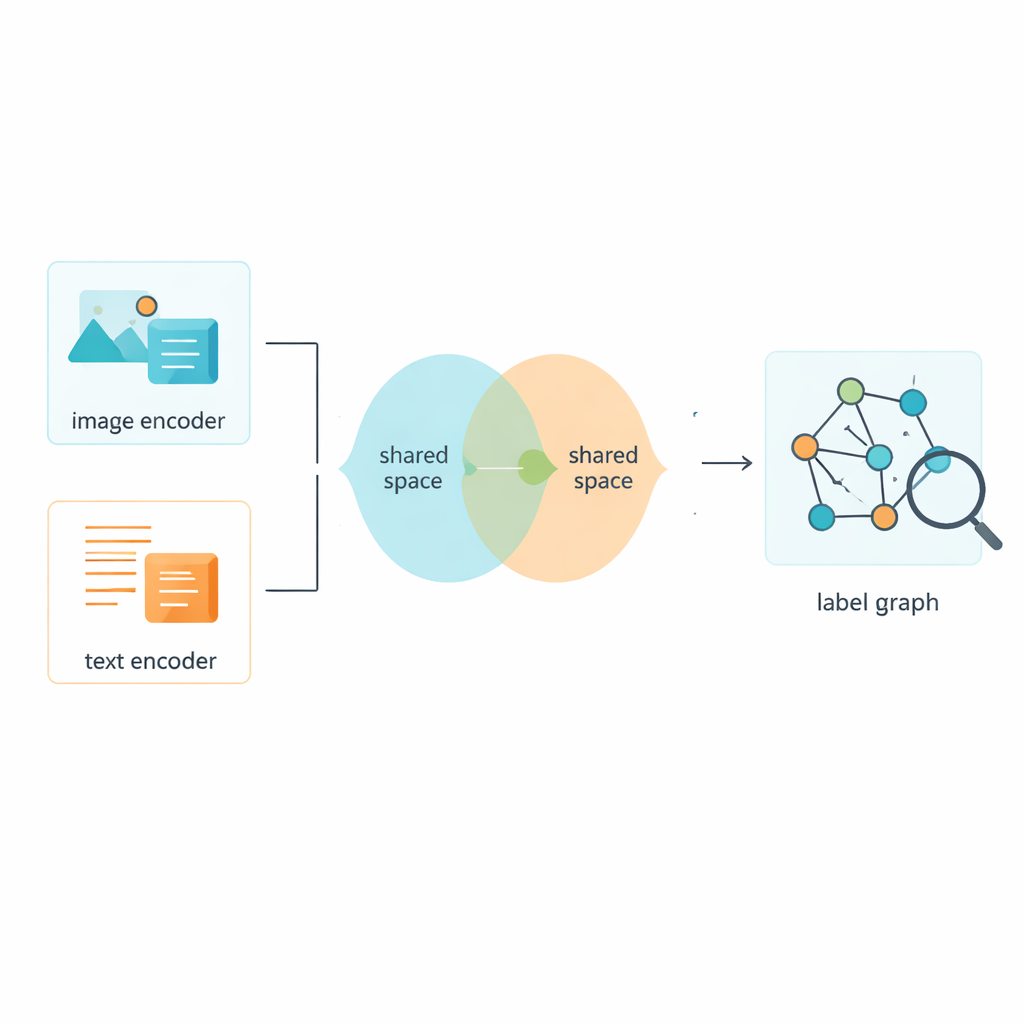
Hybrydowa strategia uczenia dla ostrzejszych rozróżnień
Trenowanie takiego systemu wymaga więcej niż jednej reguły uczenia. Autorzy zaprojektowali złożoną funkcję straty nazwaną Circle-Soft, która łączy dwie komplementarne koncepcje. Jedna część zachęca przykłady z tej samej kategorii do silnego grupowania się, jednocześnie elastycznie odpychając różne kategorie. Druga część skupia się na tym, jak dobrze obrazy i teksty opisujące tę samą scenę są wyrównane między formatami. Regulowany współczynnik równoważy te dwa cele, aby model nie przetrenowywał się ani względem ostrych granic kategorii, ani względem samego dopasowania między modalnościami. Dodatkowe straty klasyfikacyjne i adwersarialne wspierają zgodność między udoskonalonymi etykietami a wspólnymi cechami obraz–tekst.
O ile lepsze staje się dzięki temu wyszukiwanie?
Aby sprawdzić, czy te pomysły przekładają się na lepsze wyszukiwanie, autorzy przetestowali swoją metodę na trzech popularnych zbiorach par obraz–tekst pochodzących z rzeczywistych danych: MIRFlickr, NUS-WIDE i MS-COCO. Zbiory te zawierają od kilku tysięcy do kilkuset tysięcy zdjęć z powiązanymi tagami lub opisami, obejmując codzienne sceny od ulic miast po przyrodę. We wszystkich trzech benchmarkach nowe podejście konsekwentnie wyprzedzało szeroki zakres konkurencyjnych metod, w tym inne zaawansowane systemy korzystające już z modelowania etykiet za pomocą grafów. Zyski — rzędu około pół punktu procentowego do jednego punktu procentowego w rygorystycznym mierniku odzyskiwania — mogą wydawać się niewielkie, ale w dojrzałych benchmarkach nawet małe poprawy sygnalizują bardziej precyzyjne rozumienie treści. W praktyce oznacza to, że gdy użytkownik wpisze krótze zapytanie tekstowe lub prześle obraz, system ma większe szanse umieścić najbardziej istotne dopasowania międzymodalne na górze wyników.
Co to oznacza dla codziennych użytkowników
Dla osób nienależących do specjalistów kluczowy przekaz jest taki, że mądrzejsze traktowanie etykiet i strategii treningowych może zauważalnie poprawić sposób, w jaki maszyny łączą obrazy i słowa. Traktując etykiety jako splecioną sieć zamiast izolowanych znaczników oraz precyzyjnie kształtując sposób, w jaki informacje wizualne i tekstowe spotykają się we wspólnej przestrzeni, to podejście sprawia, że wyszukiwanie międzymodalne jest bardziej niezawodne w złożonych, wielotematycznych scenach. Z czasem techniki takie mogą zasilać bardziej intuicyjne biblioteki zdjęć, platformy medialne i inteligentnych asystentów, którzy znajdują to, co mamy na myśli — nawet gdy nasze słowa nie pasują idealnie do obrazów, które mamy na myśli.
Cytowanie: Wang, L., Wang, C. & Peng, S. Enhancing cross-modal retrieval via label graph optimization and hybrid loss functions. Sci Rep 16, 6400 (2026). https://doi.org/10.1038/s41598-026-37525-8
Słowa kluczowe: wyszukiwanie obraz–tekst, wyszukiwanie multimodalne, grafowe sieci neuronowe, etykiety semantyczne, uczenie maszynowe