Clear Sky Science · pl
Ulepszenie reprezentacji wiedzy medycznej w dużych modelach językowych poprzez optymalizację tokenów klinicznych
Dlaczego inteligentniejsze czytanie medyczne ma znaczenie
Za każdym asystentem medycznym opartym na AI stoi prosta, lecz kluczowa umiejętność: sposób, w jaki dzieli on tekst na elementy, które potrafi zrozumieć. Gdy to „cięcie” zawodzi — szczególnie w przypadku złożonych chińskich terminów medycznych — system może przeoczyć istotne informacje w notatkach lekarzy lub pytaniach pacjentów. W artykule pokazano, że niewielka, lecz celowa zmiana na tym pierwszym etapie może poprawić zdolność dużych modeli językowych do czytania, rozumowania i odpowiadania na pytania dotyczące chińskich danych medycznych, bez konieczności tworzenia całkowicie nowego systemu od podstaw.
Dzieląc tekst na elementy we właściwy sposób
Współczesne modele językowe nie czytają bezpośrednio znaków czy słów; najpierw zamieniają tekst na krótkie jednostki zwane tokenami. Dla języka angielskiego działa to stosunkowo dobrze, ponieważ spacje wyznaczają granice słów. Chiński jest trudniejszy: spacji brak, a wiele wyrażeń medycznych to długie, wyspecjalizowane frazy. Standardowe tokenizery, projektowane głównie pod kątem angielskiego, mają skłonność do rozcinania tych fraz na wiele przypadkowych fragmentów. Gdy model widzi nazwę choroby lub badania laboratoryjnego podzieloną na kilka niepowiązanych kawałków, trudniej mu uchwycić rzeczywiste znaczenie terminu, a jego odpowiedzi na pytania medyczne mogą stać się nieprecyzyjne lub błędne.
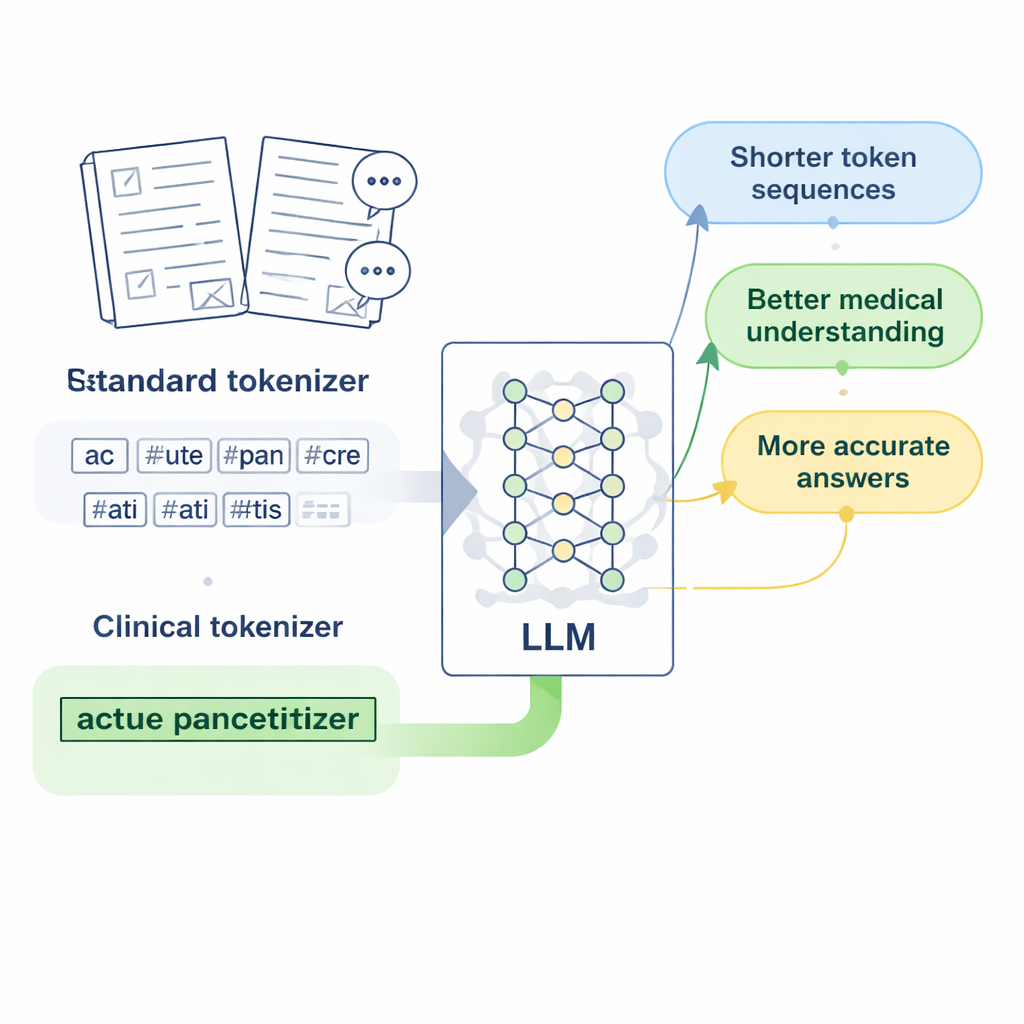
Projektowanie „tokenów klinicznych” dla medycyny chińskiej
Badacze skupili się na LLaMA2, popularnym otwartoźródłowym dużym modelu językowym, i postawili pytanie: co jeśli po prostu nauczymy jego tokenizer bogatszego słownictwa medycznego? Zgromadzili obszerne kolekcje chińskich tekstów medycznych, w tym starannie opracowane bazy tradycyjnej medycyny chińskiej, tysiące zapisów klinicznych oraz pary pytań i odpowiedzi pacjent–lekarz. Wykorzystując wersję Byte Pair Encoding na poziomie bajtów zaimplementowaną w narzędziu SentencePiece, wytrenowali nowy tokenizer, który uczy się zachowywać powszechne wyrażenia medyczne jako pojedyncze jednostki. Nowe jednostki, które autorzy nazywają „tokenami klinicznymi”, zostały następnie scalone z pierwotnym słownictwem LLaMA2, poszerzając je tak, by lepiej obejmowało chińską terminologię medyczną bez odrzucania dotychczasowej wiedzy modelu.
Od lepszych tokenów do lepszego modelu medycznego
Dodanie nowych tokenów to dopiero pierwszy krok; model musi nauczyć się dobrych reprezentacji dla tych jednostek. Zespół dostosował warstwę osadzeń (embedding) w LLaMA2, aby mogła przechowywać wektory dla rozszerzonego słownika, i przetestował dwa sposoby inicjalizacji tych nowych wektorów. Jedna metoda polegała na uśrednieniu wektorów starszych podjednostek słowa, a druga na zastosowaniu starannie skalowanych wartości losowych. Przeciwintuicyjnie metoda losowa dała lepsze wyniki, prawdopodobnie dlatego, że unika zablokowania modelu w złym początkowym przypuszczeniu co do znaczenia każdego terminu. Autorzy kontynuowali następnie trening modelu na tekstach medycznych, a potem dopracowali go w trybie instrukcyjnym na zadaniach pytanie‑odpowiedź medyczne, stosując oszczędną w zasoby metodę LoRA, tworząc wyspecjalizowaną wersję nazwaną Medical-LLaMA.
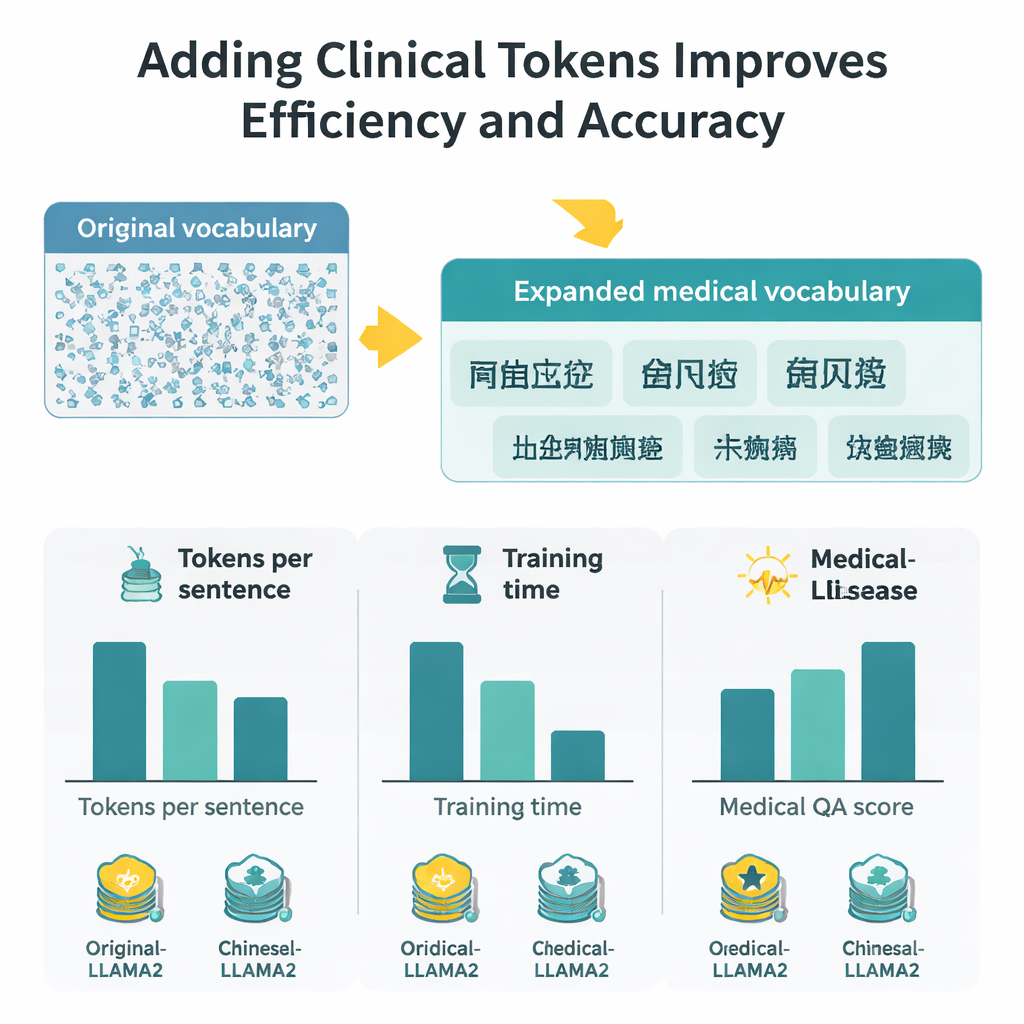
Pomiary zysków w prędkości, kontekście i dokładności
Dzięki rozszerzonemu słownikowi każdy chiński znak wymaga teraz około połowy tokenów w porównaniu z poprzednio, co oznacza, że model może przetwarzać dłuższe fragmenty w tym samym stałym oknie tokenów. W praktyce efektywna długość kontekstu w chińskim w przybliżeniu się podwaja, a czas dostrajania na dużym zestawie pytań i odpowiedzi medycznych skraca się niemal o połowę. Aby ocenić jakość odpowiedzi, autorzy połączyli dwie strategie ewaluacyjne: BERTScore, mierzący semantyczną bliskość wygenerowanej odpowiedzi względem odniesienia, oraz zaawansowany model oceniający (DeepSeek-R1), punktujący trafność, dokładność, kompletność i płynność. We wszystkich tych miarach Medical-LLaMA konsekwentnie przewyższa zarówno oryginalne LLaMA2, jak i chińsko-optymalizowaną wariantę, która nie uwzględniała tokenów specyficznych dla medycyny. Pokazuje też niewielkie, lecz stałe poprawy w powiązanych zadaniach, takich jak rozpoznawanie jednostek medycznych i klasyfikacja tekstu klinicznego, przy jednoczesnym zachowaniu wydajności w ogólnych, niemedycznych pytaniach.
Co to oznacza dla przyszłości medycznej AI
Dla osób niezwiązanych bezpośrednio ze specjalizacją kluczowa wiadomość jest taka, że mądrzejsze „okulary do czytania” dla AI — w tym przypadku lepszy sposób dzielenia języka medycznego — mogą zauważalnie poprawić, jak dobrze system rozumie i odpowiada na pytania zdrowotne. Wstawiając starannie dobrane tokeny kliniczne do słownika istniejącego modelu, autorzy zwiększają zarówno efektywność, jak i dokładność bez potrzeby przeprowadzania ogromnych nowych treningów czy projektowania całkowicie nowych architektur. Choć praca ogranicza się do modelu o 7 miliardach parametrów i chińskich tekstów medycznych, wskazuje praktyczny przepis: dostosuj najwcześniejszą warstwę przetwarzania języka do danej dziedziny, a następnie przeprowadź lekkie ponowne treningi. Taka strategia może pomóc przyszłym narzędziom AI w medycynie stać się bardziej wiarygodnymi partnerami dla klinicystów i pacjentów, zwłaszcza w językach i specjalnościach, które standardowe modele mają trudności odczytać.
Cytowanie: Li, Q., Tong, J., Liu, S. et al. Medical knowledge representation enhancement in large language models through clinical tokens optimization. Sci Rep 16, 6563 (2026). https://doi.org/10.1038/s41598-026-37438-6
Słowa kluczowe: medyczne modele językowe, chiński tekst kliniczny, tokenizacja, słownictwo kliniczne, odpowiadanie na pytania medyczne