Clear Sky Science · pl
Zastosowanie hierarchicznego samouczenia kontrastowego w dopasowywaniu międzydomenowym wielomodalnych obrazów teledetekcyjnych
Oglądanie Ziemi różnymi oczami
Satelity pogodowe, misje radarowe i wysokorozdzielcze kamery kosmiczne obserwują tę samą planetę w bardzo odmienny sposób. Ta różnorodność jest atutem w zadaniach takich jak śledzenie powodzi, mapowanie miast czy monitoring lasów — pod warunkiem że potrafimy wiarygodnie wyrównać obrazy. Artykuł streszczony tutaj przedstawia nową metodę sztucznej inteligencji, która uczy komputery lepiej dopasowywać te bardzo różne ujęcia Ziemi przy znacznie mniejszym nakładzie oznaczonych danych, otwierając drogę do szybszego i bardziej odpornego monitoringu środowiska.
Dlaczego dopasowywanie różnych obrazów jest takie trudne
Obrazy teledetekcyjne pochodzą z wielu rodzajów sensorów: kamery optyczne widzą podobnie jak nasze oczy, systemy radarowe mierzą chropowatość powierzchni, a instrumenty wielozakresowe rejestrują subtelne różnice barw. Ponieważ każdy sensor „widzi” inaczej, ten sam budynek, statek czy pole może wyglądać zupełnie inaczej na różnych obrazach — ziarnisty w radarze, ostry w obrazie optycznym lub zabarwiony w nietypowy sposób w widmach wielozakresowych. Tradycyjne metody dopasowywania polegają albo na ręcznie projektowanych cechach wizualnych, albo na w pełni nadzorowanych sieciach głębokich, które wymagają ogromnych ilości starannie oznaczonych danych. Oba podejścia zawodzą, gdy różnica wyglądu między sensorami jest duża albo gdy przykładów z etykietami brakuje — co często ma miejsce w czasie katastrof lub w trudno dostępnych regionach.
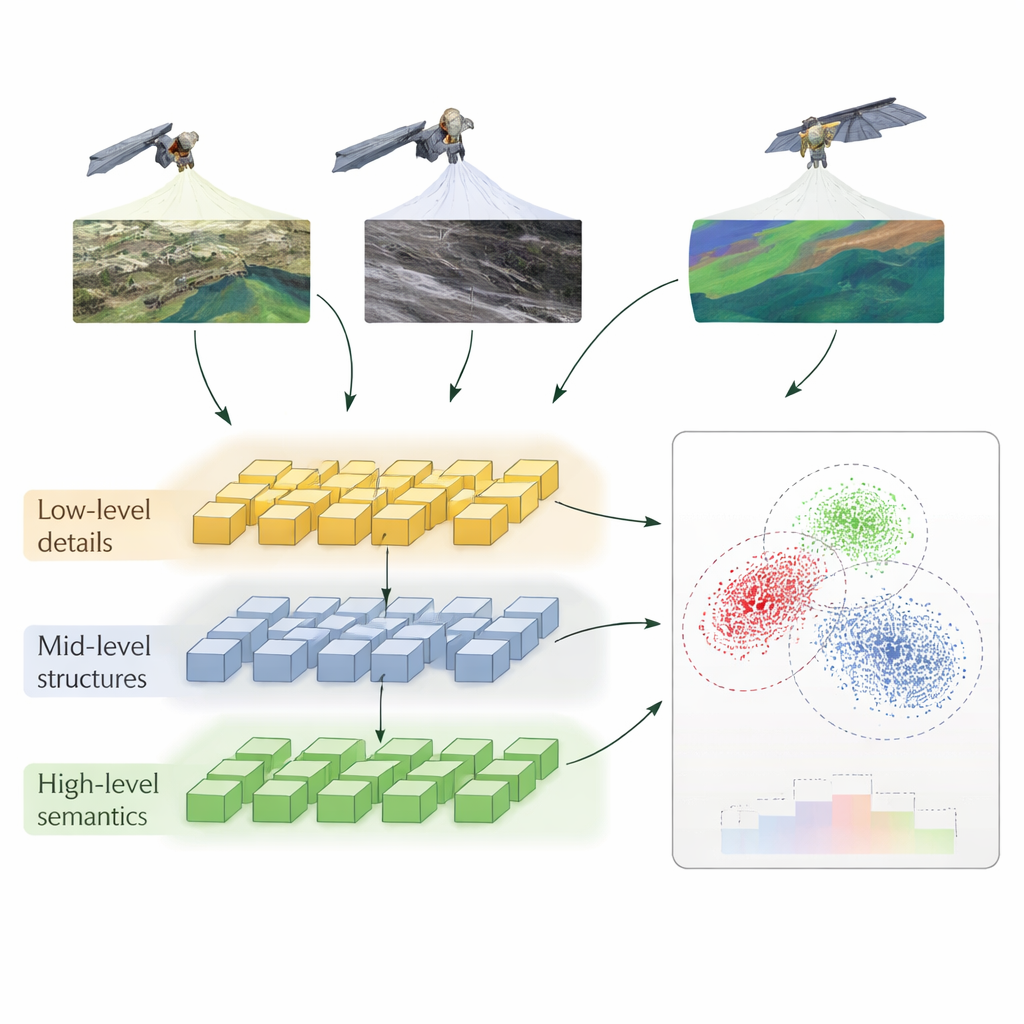
Warstwowy sposób uczenia komputerów porównywania
Autorzy proponują metodę nazwaną Hierarchical Self‑Supervised Contrastive Learning (HSSCL), która zmienia sposób, w jaki sieć neuronowa uczy się porównywać obrazy. Zamiast opierać się tylko na jednym podsumowaniu każdego obrazu, sieć wydobywa informacje na trzech poziomach: drobne detale, takie jak krawędzie i tekstury; wzory średniej skali, takie jak drogi i kontury budynków; oraz szerokie struktury, takie jak układ miasta czy typy pokrycia terenu. Na każdym poziomie system zachęca cechy pochodzące z różnych sensorów przedstawiające ten sam obszar do zbliżenia się, jednocześnie odpychając cechy pochodzące z niepowiązanych rejonów. To kontrastowe uczenie odbywa się bez etykiet ludzi: model wykorzystuje znane parowania obrazów z różnych sensorów dla tej samej lokalizacji oraz automatycznie znalezione podobne przykłady, by zbudować bogate wyobrażenie o tym, jak „ten sam miejsce” wygląda w różnych modalnościach.
Usuwanie szumów i zachowanie geometrii
Dane teledetekcyjne są w praktyce nieporządne — obrazy radarowe zawierają szum typu speckle, obrazy optyczne mogą być zamglone, a wszystkie mogą być przesunięte o kilka pikseli. HSSCL radzi sobie z tym, najpierw dzieląc obrazy na małe bloki i stosując dopasowane metody odszumiania, co pomaga sieci skupić się na istotnej strukturze zamiast losowych fluktuacji. Następnie cechy z różnych bloków trafiają do modułu opartego na grafie, który traktuje każdy region jako węzeł i łączy regiony będące blisko siebie i wyglądające podobnie. Operując na tym grafie, wyspecjalizowana sieć grafowa wzmacnia zgodność geometryczną dopasowań, zwiększając prawdopodobieństwo, że drogi zgadzają się z drogami, a budynki z budynkami, nawet w trudnych warunkach.
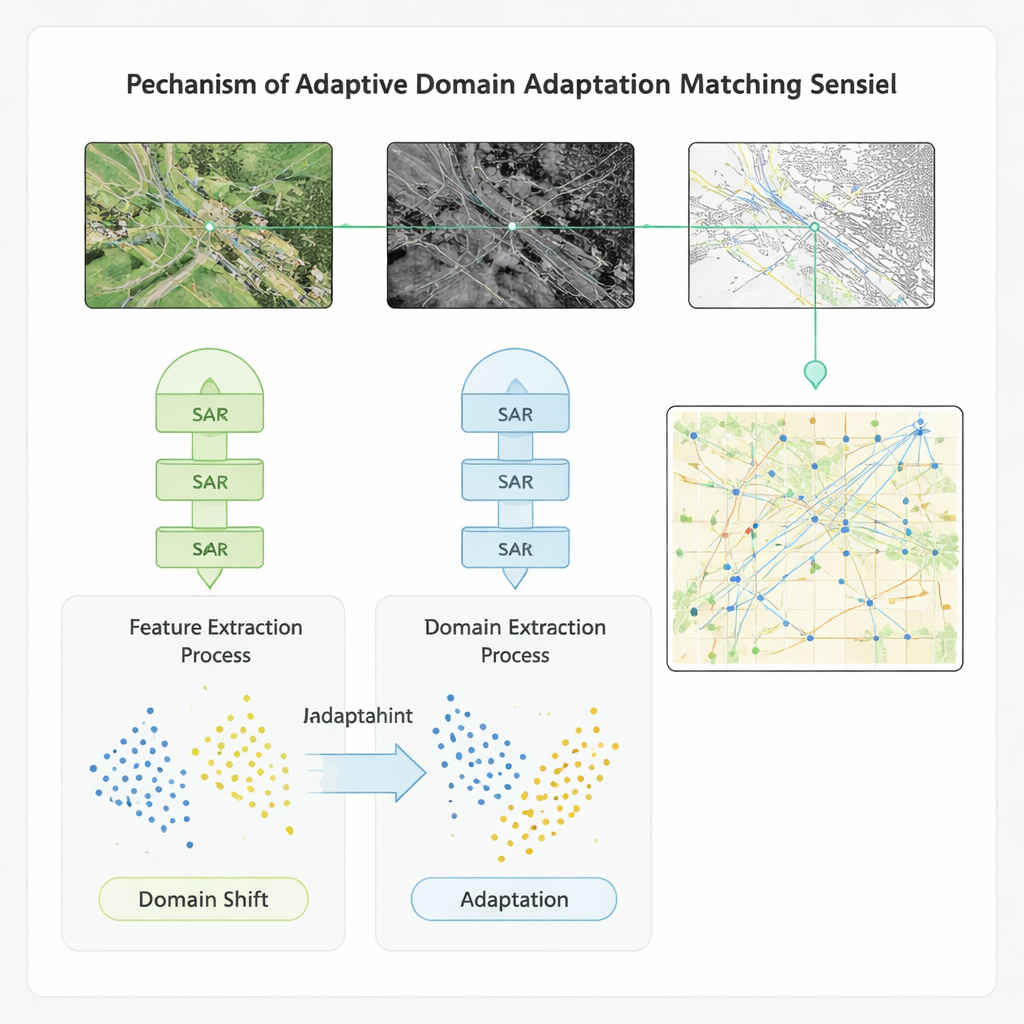
Adaptacja między zbiorami danych i warunkami
Aby zapewnić działanie metody poza pojedynczym benchmarkiem, autorzy osadzają swój schemat uczenia w modelu adaptacji domeny. Ten komponent celowo zmniejsza różnicę między statystycznymi właściwościami cech pochodzących z różnych sensorów i zbiorów danych, tak aby model wytrenowany na jednym regionie lub instrumencie można było stosować w innym bez większej utraty dokładności. Testowany na czterech publicznych zbiorach obejmujących globalne obrazy wielozakresowe, pary radar‑optyka o wysokiej rozdzielczości, sceny pokrycia terenu i obrazy statków, nowy sposób przewyższa kilka zaawansowanych metod bazowych. Poprawia dokładność, recall i F1 o około 20 punktów procentowych, przyspiesza dopasowywanie o ponad 20% i zwiększa dokładność wykrywania defektów w stylu wideo — istotną dla monitorowania zmian w czasie — o ponad 40%. Metoda wykazuje też większą odporność na szum i na przesunięcia między warunkami treningu a zastosowania.
Co to oznacza dla rzeczywistego monitoringu
Dla laika badanie pokazuje, jak można nauczyć komputery rozpoznawać „to jest to samo miejsce” na obrazach, które dla ludzkiego oka wyglądają zupełnie inaczej. Dzięki uczeniu na kilku poziomach szczegółu, oczyszczaniu szumów i jawnej adaptacji do nowych sensorów i regionów, metoda HSSCL ułatwia łączenie wielu strumieni danych satelitarnych w spójny obraz. To z kolei może pomóc służbom ratunkowym szybciej wyrównać obrazy radarowe i optyczne po burzy, wspierać planistów w śledzeniu zmian miast czy lasów na przestrzeni lat oraz umożliwiać ciągłe śledzenie statków na morzu. Choć autorzy zauważają, że ekstremalny szum i bardzo duże zniekształcenia wciąż stanowią wyzwanie, ich praca oferuje obiecującą i praktyczną ścieżkę do szybszego, bardziej niezawodnego dopasowywania wielu „oczu” na orbicie.
Cytowanie: Li, Y., Luo, Z., Zhu, G. et al. Application of hierarchical self-supervised contrastive learning in domain adaptation matching of multimodal remote sensing image. Sci Rep 16, 6445 (2026). https://doi.org/10.1038/s41598-026-37312-5
Słowa kluczowe: teledetekcja, wielomodalne obrazy, uczenie samonadzorowane, uczenie kontrastowe, adaptacja domeny