Clear Sky Science · pl
Ocena wydajności generatywnego transformera wstępnie wytrenowanego na Narodowym Egzaminie Lekarsko‑Weterynaryjnym w Japonii
Dlaczego lepsze egzaminy weterynaryjne mają znaczenie dla wszystkich
Za każdą wizytą w lecznicy stoją lata rygorystycznego szkolenia i egzamin wysokiej stawki. W Japonii przyszli lekarze weterynarii muszą zdać Narodowy Egzamin Lekarsko‑Weterynaryjny (NVLE), który sprawdza wszystko, od podstaw biologii po złożone osądy kliniczne. W badaniu zadano aktualne pytanie: czy dzisiejsze zaawansowane modele językowe AI, takie same jak te napędzające popularne chatboty, potrafią rozwiązać wymagający egzamin po japońsku — i co to mogłoby znaczyć dla edukacji weterynaryjnej oraz opieki nad zwierzętami?
Testowanie AI na rzeczywistym egzaminie weterynaryjnym
Badacze skupili się na trzech generacjach dużych modeli językowych firmy OpenAI: GPT‑4o, o1 i o3. Systemy te są zaprojektowane do czytania i generowania tekstu przypominającego ludzki język, jednak nie były specjalnie trenowane w medycynie weterynaryjnej. Aby je sprawdzić, zespół użył 74. NVLE w Japonii (2023) jako punktu odniesienia. Egzamin podzielony jest na pięć sekcji, w tym pytania tylko tekstowe oraz pytania z obrazami, pokazujące prześwietlenia, zdjęcia lub diagramy. Wszystkie pytania miały formę testu wielokrotnego wyboru z pięcioma opcjami, tak jak w prawdziwym egzaminie zdawanym przez studentów. Modele otrzymywały kolejne pytania za pomocą standardowego skryptu komputerowego i musiały odpowiadać wyłącznie numerem wybranej opcji, bez możliwości „wyjaśniania” lub negocjowania odpowiedzi.
Który model AI wypadł najlepiej?
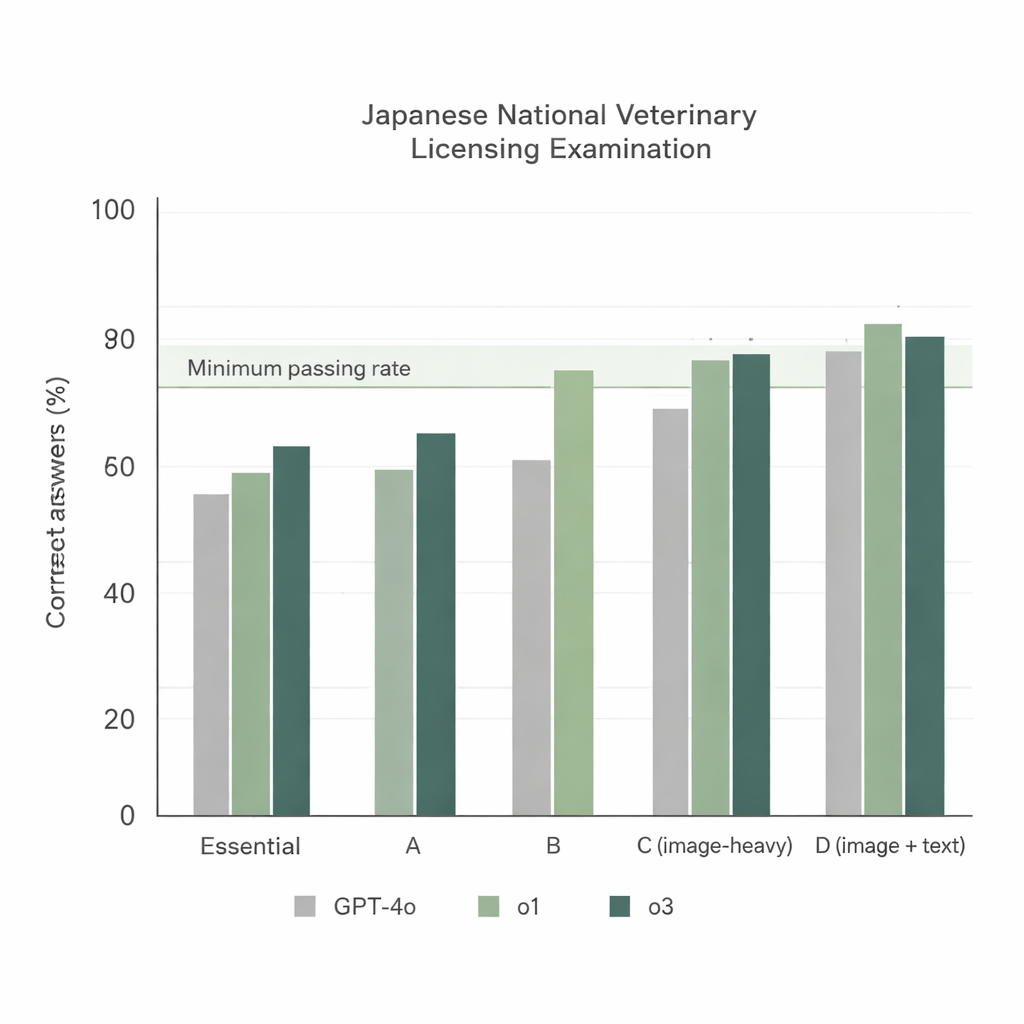
Gdy trzy modele rozwiązywały 74. NVLE w najprostszej konfiguracji — japońskie pytania i prosty prompt instrukcyjny — wyłoniły się dwie wyraźne tendencje. Po pierwsze, wszystkie modele radziły sobie dobrze w sekcjach tekstowych, lecz o1 i o3 konsekwentnie osiągały wyniki wyższe niż GPT‑4o. Po drugie, wyniki spadały w sekcjach z dużą liczbą obrazów, jednak o1 i o3 nadal utrzymywały się powyżej oficjalnego minimalnego progu zaliczenia, podczas gdy GPT‑4o nie sprostał jednej z tych sekcji. Ogółem GPT‑4o poprawnie odpowiedział na około 78% pytań, o1 osiągnął około 92%, a o3 około 93%. Ponieważ o3 nieznacznie wyprzedził o1 w całkowitym wyniku, badacze wybrali o3 do dalszych eksperymentów.
Czy prompty lub tłumaczenia naprawdę pomagają?
Dużo pisało się o „inżynierii promptów” — tworzeniu rozbudowanych instrukcji, by uzyskać lepsze odpowiedzi od AI — oraz o tłumaczeniu lokalnych pytań egzaminacyjnych na angielski, aby dopasować je do danych treningowych modeli. Badanie bezpośrednio sprawdziło te pomysły na modelu o3, porównując podstawowy prompt rozwiązujący z bardziej szczegółowym, zoptymalizowanym promptem oraz japońskie pytania z wersjami najpierw przetłumaczonymi na angielski przez ten sam model. Co zaskakujące, żadna z tych zmian nie przyniosła istotnej różnicy: o3 zaliczył egzamin komfortowo we wszystkich sześciu kombinacjach, a najprostsze podejście (oryginalny japoński tekst z podstawowym promptem) działało równie dobrze jak bardziej skomplikowane ustawienia. Sugeruje to, że przynajmniej w przypadku tych pytań weterynaryjnych najnowsze modele już wiarygodnie rozumieją język japoński i nie wymagają złożonego promptowania, by osiągnąć wysoki poziom.
Jak stabilna jest wydajność na nowszych egzaminach?
Aby sprawdzić, czy dobre wyniki nie były przypadkiem, zespół następnie poddał o3 75. (2024) i 76. (2025) NVLE, znów używając tylko oryginalnych japońskich pytań i standardowego promptu. Model uzyskał ogólne wyniki powyżej 92% na obu egzaminach i przekroczył próg zdawalności w każdej sekcji, w tym w obszarach zawierających dużo obrazów. Większość pytań otrzymała tę samą odpowiedź w trzech niezależnych uruchomieniach, co pokazuje, że odpowiedzi o3 były na ogół stabilne nawet przy pewnym stopniu losowości. Analiza błędów wykazała, że pomyłki koncentrowały się w dwóch obszarach: praktycznej wiedzy weterynaryjnej (takiej jak japońskie przepisy weterynaryjne) oraz medycynie klinicznej, które wymagają reguł specyficznych dla kraju i wieloetapowego rozumowania, a nie prostego odtwarzania faktów.
Co to oznacza — i czego nie oznacza
Badanie konkluduje, że nowoczesne modele w stylu GPT potrafią dziś zdać japoński egzamin uprawniający do wykonywania zawodu weterynarza w Japonii, bez sztuczek z tłumaczeniem czy złożonych promptów. Dla szkół weterynaryjnych i studentów otwiera to drogę do wykorzystania AI jako partnera do nauki, generatora pytań lub wyjaśniającego materiał egzaminacyjny. Dla społeczeństwa oznacza to, że AI staje się potężnym narzędziem do organizowania i udostępniania wiedzy weterynaryjnej. Jednak autorzy podkreślają, że te systemy nie są gotowe, by zastąpić weterynarzy ani podejmować decyzji medycznych samodzielnie. Modele wciąż mogą źle interpretować obrazy, mieć trudności ze zniuansowanymi osądami klinicznymi i czasem wymyślać fakty. Używane ostrożnie, mogą stać się wartościowymi asystentami w edukacji weterynaryjnej i wsparciu informacyjnym — lecz odpowiedzialność za zdrowie zwierząt pozostanie zdecydowanie po stronie ludzi.
Cytowanie: Kako, T., Kato, D., Iguchi, T. et al. Performance evaluation of generative pre-trained transformer on the National Veterinary Licensing Examination in Japan. Sci Rep 16, 4306 (2026). https://doi.org/10.1038/s41598-026-37300-9
Słowa kluczowe: egzaminy uprawniające do wykonywania zawodu weterynarza, duże modele językowe, sztuczna inteligencja w medycynie, wydajność GPT, japońska edukacja weterynaryjna