Clear Sky Science · pl
Wpływ wyboru K w k‑krotnej walidacji krzyżowej na błąd systematyczny i wariancję w modelach uczących się nadzorowanie
Dlaczego sprawdzanie modelu dwa razy naprawdę ma znaczenie
Od diagnoz medycznych po oceny kredytowe, wiele decyzji zależy dziś od modeli uczących się, trenowanych na danych historycznych. Skąd jednak mamy pewność, że model wyglądający dobrze na ekranie zachowa się poprawnie wobec nowych, niewidzianych przypadków? Popularnym sposobem „testowania" modeli jest k‑krotna walidacja krzyżowa, w której dane wielokrotnie dzieli się na części treningowe i testowe. W badaniu postawiono pozornie proste, lecz kluczowe pytanie: ile części — jak duże powinno być k — i w jaki sposób ten wybór po cichu kształtuje wiarygodność raportowanej wydajności modelu?
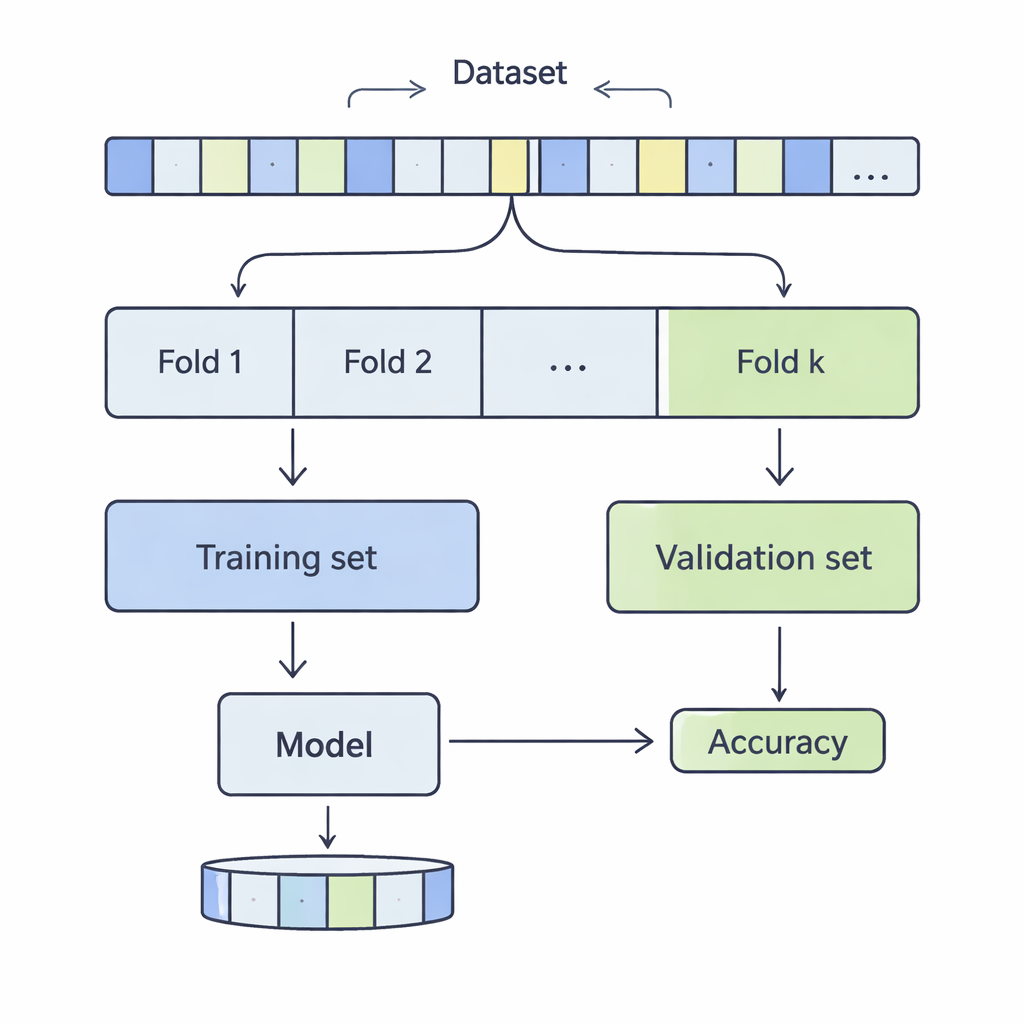
Jak dane są krojone, by sprawdzić rzeczywistość
W k‑krotnej walidacji krzyżowej zbiór danych jest tasowany i dzielony na k równych części, czyli foldów. Model trenuje się na k‑1 foldach i ocenia na pozostałym; ten proces powtarza się, aż każdy fold raz posłuży za część testową. Autorzy zbadali wartości k od 3 do 20, na 12 rzeczywistych zbiorach danych obejmujących od kilku tysięcy do ponad pół miliona rekordów, z dziedzin takich jak prognozowanie dochodów, wyniki medyczne, ataki cybernetyczne, gry czy jakość wina. Zastosowali cztery powszechne metody klasyfikacji — maszyny wektorów nośnych (SVM), drzewa decyzyjne, regresję logistyczną i k‑najbliższych sąsiadów — i starannie zmierzyli, jak wybór k wpływa na dwa kluczowe aspekty wydajności: błąd systematyczny (bias) i wariancję.
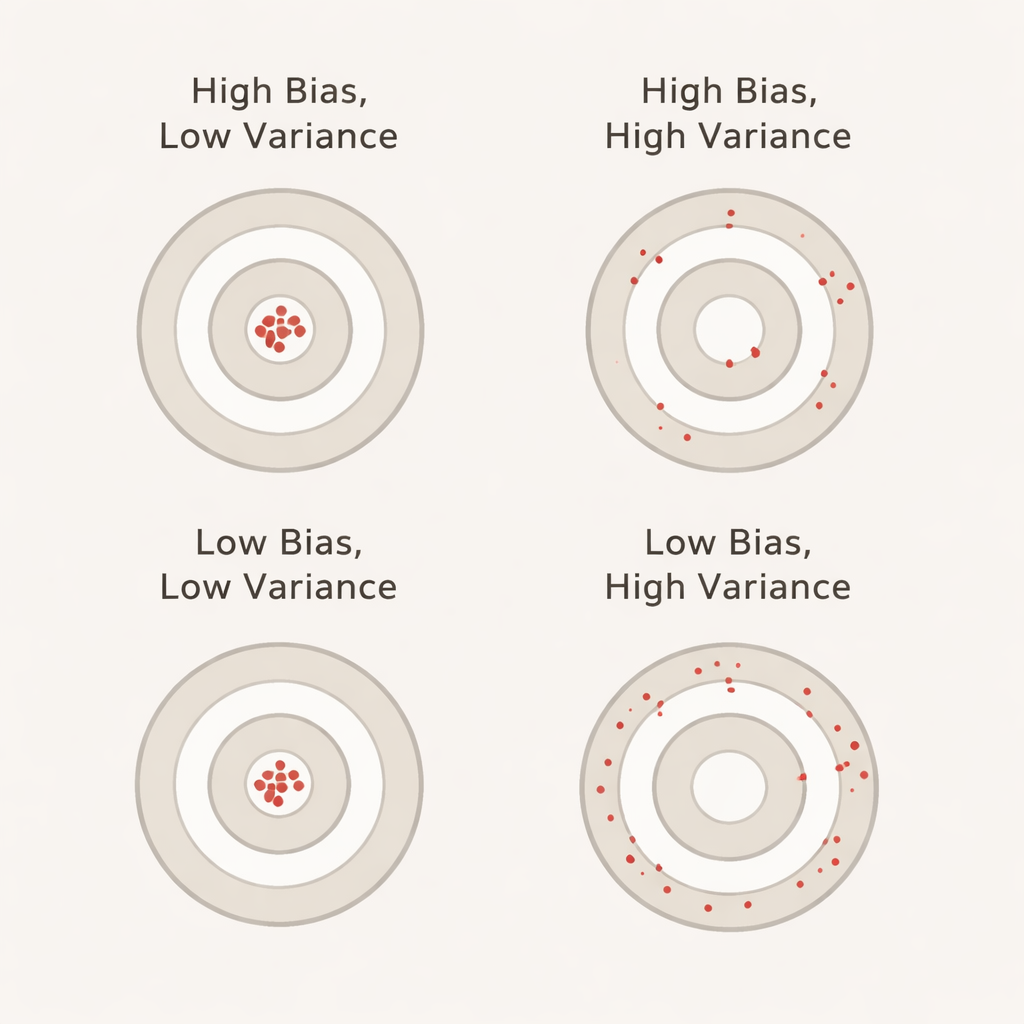
Co bias i wariancja znaczą po ludzku
W tym kontekście bias oddaje, o ile lepiej model wydaje się wypadać podczas walidacji krzyżowej niż faktycznie na osobnym, nietkniętym zbiorze testowym. Duży dodatni bias oznacza, że model wygląda zbyt optymistycznie podczas walidacji — podobnie jak uczeń, który świetnie radzi sobie na testach treningowych, a na egzaminie zawodowym zawodzi. Wariancja odzwierciedla, jak bardzo wyniki modelu skaczą między foldami: niska wariancja oznacza stabilne oceny przy różnych pocięciach danych, wysoka — duże wahania. Idealnie chcemy, aby oba — bias i wariancja — były niskie, tak by raportowana dokładność była jednocześnie realistyczna i stabilna.
Co się dzieje, gdy zwiększamy liczbę foldów
We wszystkich dwunastu zbiorach danych i dla wszystkich czterech algorytmów wyraźnie rysował się jeden wzorzec: wraz ze wzrostem k wariancja niemal zawsze rosła. Innymi słowy, użycie większej liczby foldów sprawiało, że podawana dokładność była mniej stabilna z foldu na fold. To przeczy powszechnemu przekonaniu, że więcej foldów automatycznie daje lepsze, bardziej wiarygodne estymaty. Wyjaśnienie jest takie, że przy dużym k każdy fragment walidacyjny staje się bardzo mały i mniej reprezentatywny, więc wyniki stają się bardziej wrażliwe na przypadkowe niuanse danych. Jednocześnie bias zachowywał się mniej jednolicie. Dla k‑najbliższych sąsiadów i SVM bias miał tendencję do wzrostu wraz z k, co oznacza, że te modele często wydawały się bardziej dokładne w walidacji krzyżowej niż na trzymanym na boku zbiorze testowym. Drzewa decyzyjne wykazywały mniej więcej zrównoważone wzorce, a regresja logistyczna znalazła się pośrodku, z mieszanymi, ale umiarkowanymi zmianami biasu.
Dlaczego „ustawienia standardowe" mogą wprowadzać w błąd
Większość praktycznych przewodników po prostu sugeruje użycie pięciu lub dziesięciu foldów, niezależnie od zbioru danych czy algorytmu uczenia. Analiza autorów pokazuje, że taka uniwersalna rada może być myląca. W niektórych zbiorach danych i dla niektórych modeli większe wartości k potęgowały zbyt optymistyczne wrażenie wydajności; we wszystkich przypadkach więcej foldów zwiększało zmienność estymat. To jest szczególnie niepokojące w obszarach o wysokiej stawce, takich jak opieka zdrowotna, finanse czy infrastruktura, gdzie fałszywe zaufanie do dokładności modelu może mieć realne konsekwencje. Badanie argumentuje, że efekty wyboru k zależą zarówno od natury danych (małe vs. duże, zaszumione vs. czystsze), jak i od tego, jak konkretny algorytm uczy się na wielokrotnie bardzo podobnych zestawach treningowych.
Wniosek dla każdego korzystającego z uczenia maszynowego
Główna lekcja jest taka, że liczba foldów w walidacji krzyżowej to nie błahy szczegół techniczny — bezpośrednio kształtuje, na ile wiarygodne są twoje liczby dokładności. W tych eksperymentach większa liczba foldów konsekwentnie czyniła wyniki bardziej chwiejne i często sprawiała, że niektóre modele wydawały się lepsze, niż faktycznie były. Zamiast ślepo wybierać k=5 lub k=10, autorzy zalecają traktować k jako pokrętło do strojenia: sprawdź, jak wyniki zmieniają się w niewielkim zakresie wartości k i, jeśli to możliwe, obserwuj więcej niż jedną miarę wydajności. Dla praktyków i zainteresowanych czytelników przesłanie jest jasne: przy ocenie modeli uczenia maszynowego sposób, w jaki kroisz dane, może mieć niemal takie samo znaczenie jak sam model.
Cytowanie: Abedin, T., Xu, H. & Uddin, S. The impact of K selection in K‑fold cross-validation on bias and variance in supervised learning models. Sci Rep 16, 6084 (2026). https://doi.org/10.1038/s41598-026-37247-x
Słowa kluczowe: k-krotna walidacja krzyżowa, kompromis bias‑wariancja, ocena modelu, walidacja w uczeniu maszynowym, klasyfikacja nadzorowana