Clear Sky Science · pl
Estymacja kierunku przybycia wektorowych akustycznych sygnałów pod wodą w hybrydowych warunkach szumowych oparta na mechanizmie sparsowanej bramkowanej mieszanki ekspertów
Słuchając ukrytych sygnałów pod wodą
Statki, okręty podwodne, roboty podwodne, a nawet biolodzy morscy polegają na nasłuchiwaniu słabych dźwięków w oceanie, by określić, skąd one pochodzą. Jednak morze to hałaśliwe środowisko: silniki, fale, zwierzęta i same instrumenty dodają zakłóceń. W pracy tej przedstawiono nowy sposób wyznaczania kierunku dźwięków pod wodą, nawet gdy szum jest złożony i nieprzewidywalny, wykorzystujący nowoczesną formę sztucznej inteligencji, która uczy się radzić sobie z różnymi rodzajami szumu, zamiast zakładać, że wszystko jest proste i jednorodne.

Dlaczego określenie kierunku jest tak trudne w oceanie
Aby zlokalizować źródło dźwięku, inżynierowie używają szeregu hydrofonów ułożonych w linii. Porównując niewielkie różnice w czasie, w jakim dźwięk dociera do każdego czujnika, można oszacować kierunek, z którego przybył — zadanie znane jako estymacja kierunku przybycia (DOA). Klasyczne metody zakładają, że tło szumowe przypomina delikatny, równomierny szum — matematycznie „biały szum Gaussa”. Rzeczywiste oceany rzadko zachowują się tak ładnie. Szum może być impulsowy, jak nagłe trzaski; kolorowy, z większą energią w niektórych częstotliwościach; lub nieregularny pomiędzy czujnikami. Ta mieszanka zachowań, zwana szumem hybrydowym, łamie założenia starszych algorytmów, powodując spadek dokładności właśnie wtedy, gdy warunki są najtrudniejsze.
Sprytniejsza linia czujników
Naukowcy oparli swoje rozwiązanie na prostym, lecz efektywnym układzie czujników: prostej linii tzw. wektorowych hydrofonów, które mierzą zarówno ciśnienie, jak i ruch cząstek w wodzie. Gdy dalekie źródła dźwięku emitują fale, te fale docierają do każdego czujnika w nieco innym czasie i z nieco inną fazą, w zależności od kąta napływu. Z tych pomiarów system buduje macierz kowariancji — zwarty opis tego, jak sygnały na różnych czujnikach są ze sobą powiązane w czasie. Macierz ta zawiera geometryczne wskazówki potrzebne do wnioskowania o kierunku, ale jest spleciona z całym złożonym szumem obecnym w środowisku.
Przekształcanie zaszumionych danych w wzorce możliwe do nauczenia
Sieci neuronowe zwykle operują na liczbach rzeczywistych, a macierz kowariancji ma wartości zespolone. Zespół dzieli więc macierz na dwie rzeczywiste macierze reprezentujące część rzeczywistą i urojoną i podaje je jako dwukanałowy „obraz” do konwolucyjnej sieci neuronowej (CNN). Ta CNN skanuje macierz w poszukiwaniu wzorców przestrzennych, które odróżniają prawdziwą strukturę sygnału od szumu. Zamiast polegać na ręcznie zaprojektowanych formułach, CNN uczy się tych cech bezpośrednio z danych, stopniowo budując od prostych lokalnych zależności do wyższych poziomów reprezentacji, użytecznych przy lokalizowaniu źródeł dźwięku.
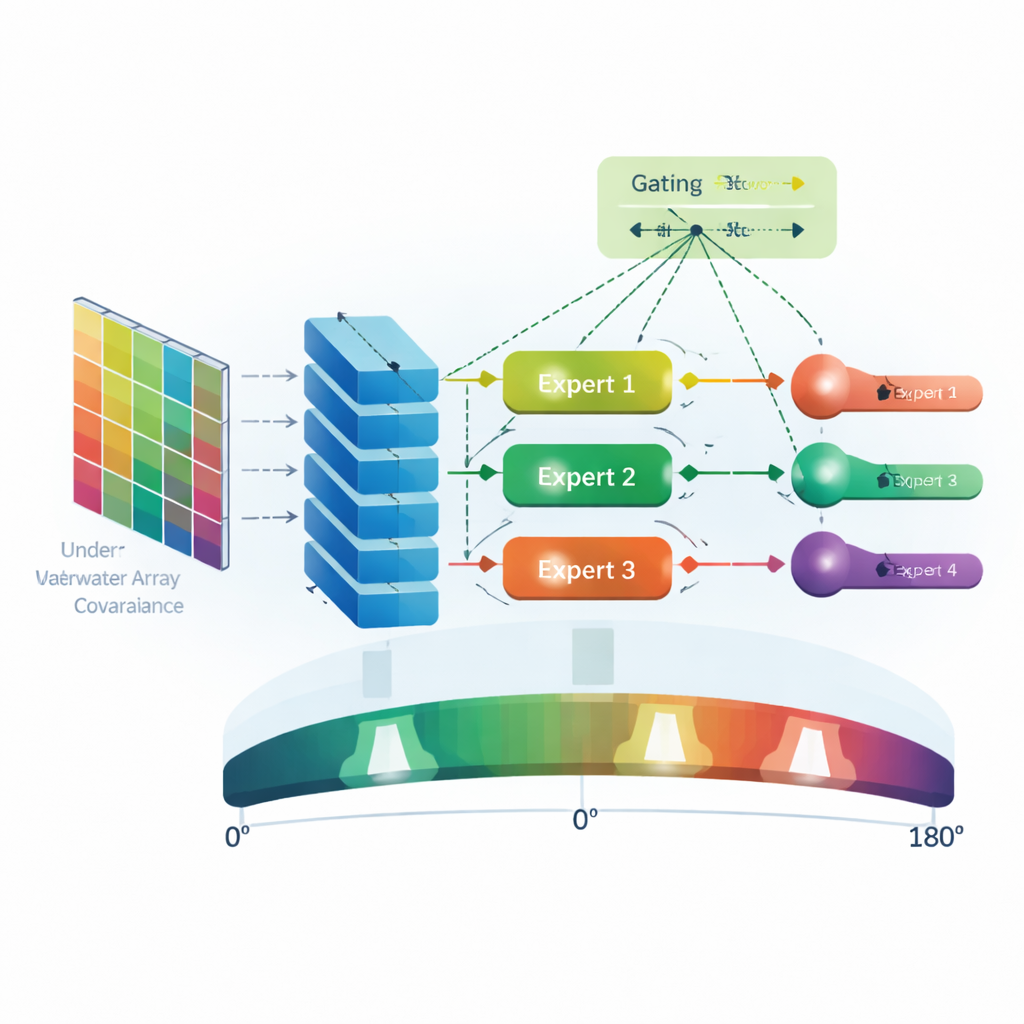
Wielu specjalistów i jeden sprytny koordynator
Kluczową innowacją jest to, co dzieje się po CNN: sparsowanie bramkowanej sieci mieszanki ekspertów (SMoE). Zamiast jednej dużej, monolitycznej sieci próbującej obsłużyć każdą sytuację, system zawiera kilka mniejszych sieci ekspertów, z których każda jest wyspecjalizowana w radzeniu sobie z konkretnym typem szumu, takim jak biały, różowy, czerwony, niebieski, fioletowy lub szum impulsowy. Osobna sieć bramkująca analizuje cechy wyekstrahowane przez CNN i dla każdego przykładu decyduje, które z ekspertów są najbardziej istotne. Aktywowane są tylko te najlepsze eksperci, a ich wyniki są łączone, by wygenerować końcowe oszacowanie prawdopodobieństwa obecności źródła dźwięku dla kątów od 0° do 180°. Taka konstrukcja sprawia, że model jest adaptacyjny — ponieważ zmienia, których ekspertów „słucha” w zależności od warunków szumowych — oraz wydajny, ponieważ unika uruchamiania wszystkich ekspertów za każdym razem.
Testowanie w trudnych, realistycznych warunkach
Aby wytrenować system, autorzy najpierw wygenerowali dane, w których każdy ekspert widzi tylko jeden typ szumu, co pozwoliło mu się wyspecjalizować. Następnie trenowali sieć bramkującą na mieszankach wszystkich sześciu szumów, naśladując rzeczywiste hybrydowe środowiska. Ocenili też model na dużym, realistycznym zbiorze testowym zawierającym zarówno symulowany szum, jak i rzeczywiste nagrania podwodne, przy szerokim zakresie stosunków sygnału do szumu i długości próbek. W porównaniu z dobrze znanymi klasycznymi technikami i innymi podejściami głębokiego uczenia, model SMoE konsekwentnie wykazywał mniejsze błędy i wyższe wskaźniki sukcesu, zwłaszcza gdy szum był silny lub gdy dostępnych było tylko niewiele danych. Przy stosunku sygnału do szumu 0 dB — gdzie moc sygnału i szumu są równe — model osiągnął średni błąd kątowy poniżej jednego stopnia, podczas gdy konkurencyjne metody mogły się mylić o wiele stopni.
Co to oznacza dla przyszłego monitorowania podwodnego
Mówiąc wprost, praca ta pokazuje, że pozwalając wielu wyspecjalizowanym „słuchaczom” AI dzielić zadanie i wybierając ich dynamicznie, można znacząco poprawić naszą zdolność określania, skąd pochodzą dźwięki pod wodą w chaotycznych, hałaśliwych warunkach. Podejście to można dostosować do innych układów czujników poza prostymi liniowymi tablicami, a ta sama idea — mieszanka ekspertów ze sprytną bramką — może pomóc w radarze, robotyce i innych dziedzinach, gdzie sygnały trzeba lokalizować w obecności złożonych zakłóceń. Dla zastosowań zależnych od niezawodnego nasłuchu podwodnego, od nawigacji po monitoring środowiskowy, metoda ta oferuje bardziej elastyczny i odporny sposób przecierania przez szum.
Cytowanie: Xu, W., Yi, S., Gu, H. et al. Underwater acoustic vector DOA estimation in hybrid noise environments based on sparsely-gated mixture-of-experts mechanism. Sci Rep 16, 6192 (2026). https://doi.org/10.1038/s41598-026-37217-3
Słowa kluczowe: akustyka podwodna, kierunek przybycia, szum hybrydowy, uczenie głębokie, mieszanka ekspertów