Clear Sky Science · pl
Analiza porównawcza modeli nadzorowanych i zespołowych z eksploracją nienadzorowaną w przewidywaniu choroby Alzheimera
Dlaczego wczesne ostrzeganie ma znaczenie
Choroba Alzheimera stopniowo pozbawia ludzi pamięci i samodzielności, często na długo przed postawieniem pewnej diagnozy. Rodziny, lekarze i systemy opieki zdrowotnej odnoszą korzyści, gdy sygnały ostrzegawcze są wykrywane wcześnie, ponieważ wtedy leczenie, planowanie i wsparcie mogą przynieść największy efekt. W tym badaniu zadano praktyczne pytanie: czy starannie zaprojektowane programy komputerowe, uczone na rutynowych informacji klinicznej i obrazach mózgu, potrafią wykrywać demencję bardziej niezawodnie niż obecne standardowe narzędzia — a jednocześnie ujawnić ukryte wzorce rozwoju choroby?
Przekształcanie zapisów pacjentów w użyteczne sygnały
Badacze sięgnęli do dobrze znanej bazy danych OASIS-2, która śledzi 150 osób starszych w wieku 60–96 lat przez kilka lat. Dla każdej wizyty zestaw danych zawiera podstawowe informacje, takie jak wiek, lata edukacji i status społeczno-ekonomiczny, a także wyniki testów poznawczych oraz miary pochodzące z rezonansu magnetycznego mózgu, jak ogólna objętość mózgu. Zanim można było przeprowadzić prognozy, zespół oczyścił dane, usunął identyfikatory i przypadki niejednoznaczne, uzupełnił niewielką liczbę brakujących wartości i ujednolicił wszystkie pomiary numeryczne. Zajął się też kluczowym problemem rzeczywistym: w zbiorze znalazło się dużo więcej osób zdrowych niż chorych na demencję. Aby zapobiec sytuacji, w której modele po prostu przewidują „brak demencji” najczęściej, badacze zastosowali schematy ważenia, które sprawiają, że błędy popełnione na mniejszej grupie chorych mają większą wagę podczas uczenia.
Porównanie klasycznych narzędzi z zespołami modeli
Z przygotowanym zbiorem autorzy porównali znane narzędzia uczenia maszynowego z bardziej zaawansowanymi „zespołami” (ensembles), które łączą kilka modeli w jeden silniejszy predyktor. Grupa klasyczna obejmowała regresję logistyczną, drzewa decyzyjne, maszyny wektorów nośnych oraz lasy losowe. W grupie zespołowej znalazły się AdaBoost, XGBoost oraz model głosowania większościowego, łączący trzy dostrojone klasyfikatory. Wszystkie modele trenowano na części danych i testowano na wyodrębnionych przypadkach, a wydajność oceniano za pomocą dokładności, zdolności do prawidłowego wykrywania osób z demencją (recall) oraz pola pod krzywą ROC, podsumowującej, jak dobrze model rozdziela przypadki zdrowe od chorych. 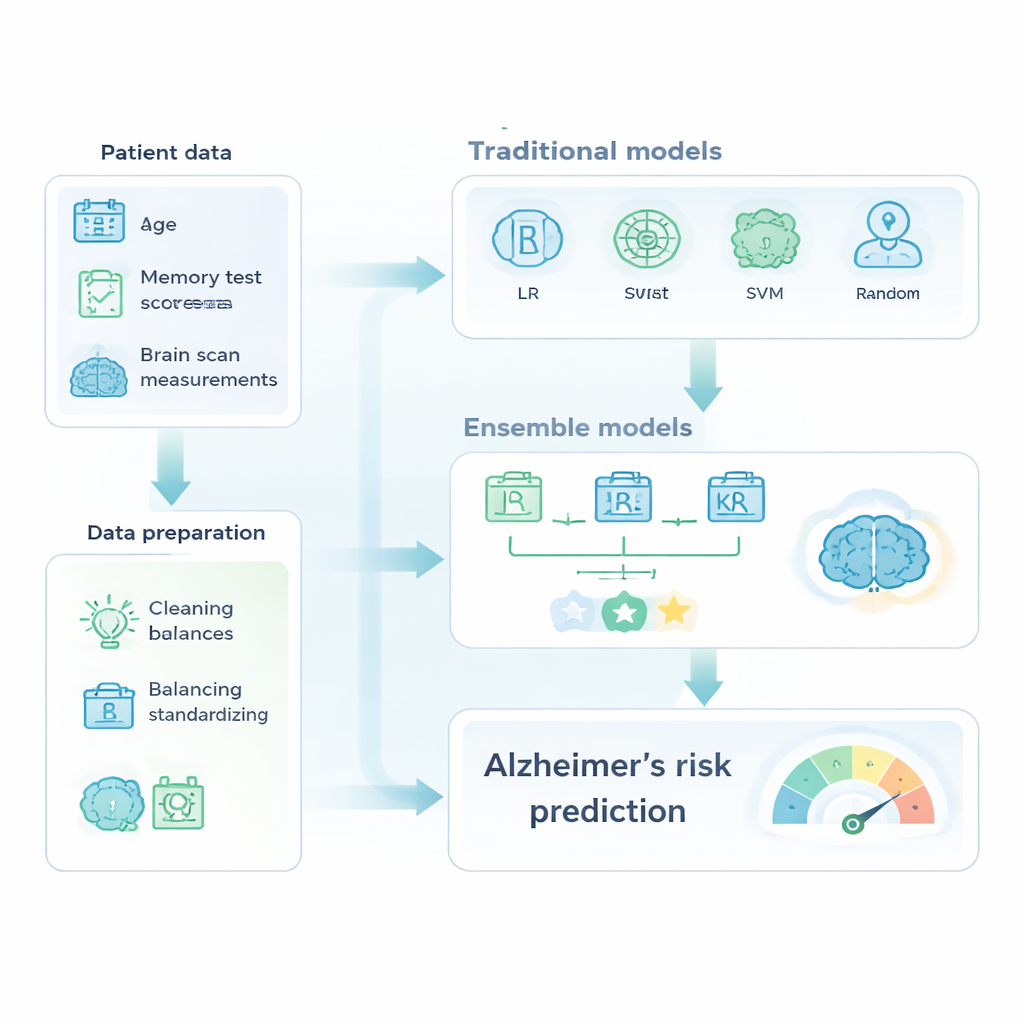
Kiedy wiele umysłów przewyższa jeden
Wyniki bezpośredniego porównania były jednoznaczne. Choć najlepsze metody tradycyjne działały rozsądnie, osiągały pułap zbliżony do wyników wcześniejszych badań, z dokładnością testów w przedziale niskich do średnich 80 procent. W przeciwieństwie do tego, model głosowania większościowego osiągnął około 95% dokładności i podobnie wysoką wartość ROC, przekraczając często cytowany próg 92%. AdaBoost i inne modele zespołowe również radziły sobie lepiej niż którykolwiek pojedynczy model tradycyjny. Przewaga ta wynika z faktu, że różne algorytmy wychwytują różne aspekty danych; pozwalając im „głosować”, zespół wygładza indywidualne dziwactwa i przeuczenie, co prowadzi do stabilniejszych prognoz. Ceną tej poprawy jest mniejsza przejrzystość: trudniej zrozumieć na pierwszy rzut oka, dlaczego zespół podjął konkretną decyzję w porównaniu z prostą regresją czy pojedynczym drzewem. 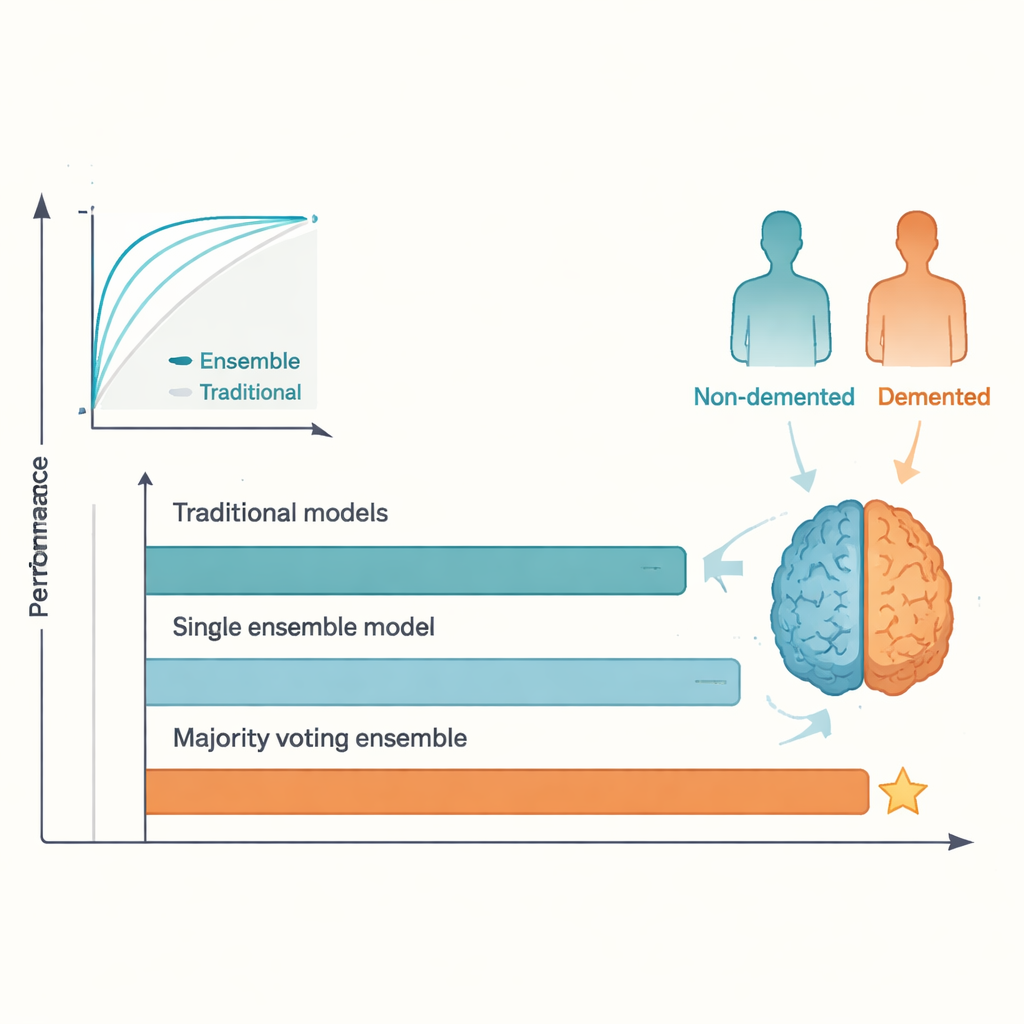
Poszukiwanie naturalnych grup w danych
Ponadto badacze zapytali nie tylko kto ma demencję, ale też jak pacjenci grupują się naturalnie, niezależnie od etykiet diagnostycznych. W tym celu przekształcili wszystkie zmienne ciągłe w uporządkowane kategorie — na przykład przedziały wieku czy objętości mózgu — i zastosowali technikę zwaną wielokorrespondencyjną analizą (MCA), aby skompresować tę bogatą informację do kilku głównych wymiarów. Następnie użyli k-średnich (k-means) do podziału tych punktów na niewielką liczbę spójnych grup. Niektóre klastry były zdominowane przez osoby o zachowanej objętości mózgu i normalnych wynikach poznawczych, inne zawierały osoby z małą objętością mózgu, słabymi wynikami testów i bardziej zaawansowanymi ocenami demencji. Fakt, że te nienadzorowane klastry dobrze pokrywały się ze statusem klinicznym, sugeruje, że dane niosą silny, spójny sygnał dotyczący ryzyka choroby i jej postępu.
Co to oznacza dla pacjentów i klinicystów
Dla laika przesłanie jest proste: przy starannym projekcie zespoły modeli uczenia maszynowego potrafią wykrywać demencję związaną z chorobą Alzheimera w ustrukturyzowanych danych klinicznych dokładniej niż starsze metody, i mogą to robić korzystając z informacji, które wiele klinik już zbiera. Równocześnie techniki eksploracyjne pokazują, że ludzie układają się w wyraźne profile zdrowia mózgu i funkcji poznawczych, co sugeruje różne ścieżki rozwoju choroby. Choć badanie ogranicza niewielka liczebność próby oraz złożoność interpretacji modeli zespołowych, pokazuje, że łączenie silnej predykcji z uważną analizą eksploracyjną może zarówno poprawić wczesne wykrywanie, jak i pogłębić zrozumienie mechanizmów, dzięki którym choroba Alzheimera postępuje.
Cytowanie: Amr, Y., Gad, W., Leiva, V. et al. Comparative analysis of supervised and ensemble models with unsupervised exploration for alzheimer’s disease prediction. Sci Rep 16, 7322 (2026). https://doi.org/10.1038/s41598-026-37122-9
Słowa kluczowe: choroba Alzheimera, prognozowanie demencji, uczenie maszynowe, modele zespołowe, obrazowanie mózgu