Clear Sky Science · pl
Badanie porównawcze nad przewidywaniem odległych przerzutów pooperacyjnych raka płuca w oparciu o modele uczenia maszynowego
Dlaczego przewidywanie rozsiewu nowotworu ma znaczenie
Rak płuca wciąż należy do najbardziej śmiertelnych nowotworów, nawet po usunięciu wszystkich widocznych guzów przez chirurga. Wielu pacjentów później rozwija utajone ogniska choroby, które pojawiają się w mózgu, kościach, wątrobie lub innych narządach. Lekarze chcieliby jak najszybciej po operacji wiedzieć, u których pacjentów istnieje większe ryzyko takiego odległego rozsiewu, by móc lepiej dostosować wizyty kontrolne i terapie. W tym badaniu sprawdzono, czy nowoczesne programy komputerowe, zwane modelami uczenia maszynowego, mogą pomóc przewidzieć, kto jest bardziej narażony, wykorzystując dane, które szpitale już gromadzą w rutynowej opiece.
Szczegółowa analiza dużej grupy pacjentów
Naukowcy przeanalizowali dokumentację 3 120 osób z rakiem płuca w stadiach I–III, które przeszły resekcję guza w jednym ośrodku onkologicznym w Chinach. Wszyscy mieli co najmniej dwuletnią obserwację. Dla każdego pacjenta zebrano 52 rodzaje informacji, obejmujące wiek, płeć, masę ciała, historię palenia, wyniki badań obrazowych, szczegóły operacji, badania laboratoryjne oraz to, czy otrzymali leczenie uzupełniające, takie jak chemioterapia czy radioterapia po zabiegu. W trakcie obserwacji 596 pacjentów rozwinęło odległe przerzuty, a 2 524 nie. Taki rzeczywisty przekrój pozwolił autorom sprawdzić, które cechy wiążą się z późniejszym rozsiewem.
Nauczanie komputerów rozpoznawania wzorców ryzyka
Zamiast opierać się na jednej formule, badacze porównali dziewięć różnych metod uczenia maszynowego, od prostych drzew decyzyjnych po zaawansowane techniki łączące wiele słabszych modeli. Najpierw zastosowali matematyczny filtr, który zredukował pierwotne 52 czynniki do mniejszego, bardziej informatywnego zbioru. Następnie w powtarzanych rundach trenowali każdy model na części danych i testowali go na pacjentach, których model wcześniej „nie widział”. Ponieważ tylko około jeden na pięciu pacjentów rozwinął przerzuty, dopasowali proces uczenia tak, by komputer nie przewidywał po prostu „niskiego ryzyka” dla wszystkich. Wyniki oceniano za pomocą kilku miar, w tym tego, jak dobrze modele rozdzielały pacjentów na grupy wysokiego i niskiego ryzyka oraz jak bliskie rzeczywistości były prognozowane prawdopodobieństwa.
Wybór najbardziej wiarygodnego modelu
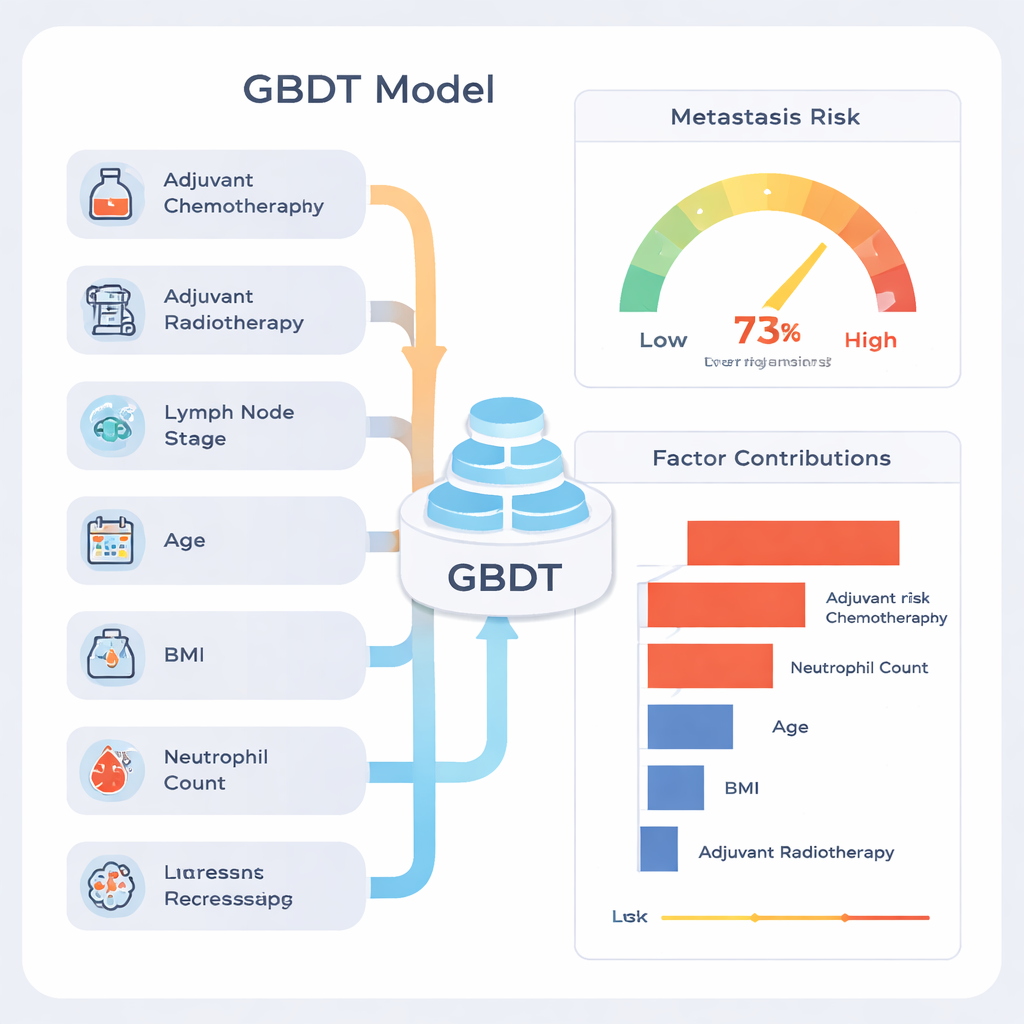
Spośród dziewięciu podejść wyróżnił się model Gradient Boosting Decision Tree (GBDT). Na danych testowych poprawnie uszeregował pacjentów z ogólną skutecznością około 77%, a jego podsumowujący wskaźnik dyskryminacji (pole pod krzywą ROC) wyniósł 0,81, co w kontekście narzędzi medycznych uznawane jest za silny wynik. Model szczególnie dobrze identyfikował pacjentów, którzy pozostali bez przerzutów (wysoka „wartość predykcyjna ujemna”), co oznacza, że wynik wskazujący niskie ryzyko zwykle był uspokajający. Gdy zespół badał zachowanie modelu przy wielu różnych losowych podziałach danych, jego wydajność pozostała stabilna, co sugeruje, że nie zapamiętywał jedynie specyficznych cech jednego podzbioru.
Co napędza decyzje modelu
Częstą krytyką uczenia maszynowego jest to, że może tworzyć „czarne skrzynki”. Aby temu zaradzić, autorzy zastosowali metodę wyjaśniania zwaną SHAP, która przypisuje każdemu czynnikowi wkład w końcową ocenę ryzyka dla każdego pacjenta. Analiza wykazała, że najsilniejsze sygnały pochodziły od informacji o otrzymanej chemioterapii lub radioterapii po operacji, liczbie zajętych węzłów chłonnych, wieku, wskaźniku masy ciała (BMI) oraz przedoperacyjnym poziomie neutrofili, rodzaju białych krwinek. Pacjenci z bardziej zaawansowanym zajęciem węzłów chłonnych i oznakami ogólnoustrojowego zapalenia mieli tendencję do wyższych przewidywanych ryzyk. Autorzy podkreślają, że wysoki wkład informacji o chemioterapii i radioterapii nie oznacza, że te terapie powodują przerzuty; raczej są markerami, że lekarze ocenili chorobę jako bardziej agresywną, więc ci pacjenci zaczynali z wyższym ryzykiem.
Jak to może pomóc pacjentom w praktyce
Ponieważ model wykorzystuje dane, które większość ośrodków onkologicznych już rejestruje, po dalszych testach mógłby zostać wbudowany w systemy informatyczne szpitali. Dla nowego pacjenta tuż po operacji system mógłby pobrać jego dane i wygenerować spersonalizowane prawdopodobieństwo wystąpienia odległych przerzutów wraz z prostym wyjaśnieniem czynników wpływających na podwyższenie lub obniżenie ryzyka. Lekarze mogliby wtedy zdecydować, kto wymaga częstszej kontroli obrazowej, dodatkowego wsparcia lub włączenia do badań klinicznych, a kto może bezpiecznie uniknąć intensywnego nadzoru. Badanie przeprowadzono w jednym szpitalu, więc narzędzie wymaga jeszcze weryfikacji i dopracowania w innych regionach i systemach opieki zdrowotnej. Mimo to stanowi obiecujący wzorzec łączenia rutynowych danych klinicznych z przejrzystym uczeniem maszynowym w celu poprawy długoterminowej opieki nad osobami z rakiem płuca.
Cytowanie: Guo, X., Xu, T., Luo, Y. et al. Comparative study on predicting postoperative distant metastasis of lung cancer based on machine learning models. Sci Rep 16, 6468 (2026). https://doi.org/10.1038/s41598-026-37113-w
Słowa kluczowe: rak płuca, odległe przerzuty, uczenie maszynowe, prognozowanie ryzyka, opieka pooperacyjna