Clear Sky Science · pl
Model językowy oparty na wiedzy do generowania spersonalizowanych planów treningowych
Inteligentniejsze plany treningowe dla zwykłych ludzi
Większość aplikacji fitness obiecuje personalizację, ale wiele z nich wciąż polega na uniwersalnych szablonach, które ignorują rzeczywisty stan twojego ciała. W artykule zaprezentowano LLM-SPTRec — nowy system, który wykorzystuje duże modele językowe stosowane w nowoczesnych chatbotach, połączone ze sprawdzoną wiedzą z nauk o sporcie i danymi z urządzeń noszonych, aby tworzyć bezpieczniejsze i skuteczniejsze plany treningowe. Dla każdego, kto zastanawiał się, dlaczego aplikacja wciąż proponuje niewłaściwe ćwiczenia — albo obawiał się, czy porady zdrowotne generowane przez AI są bezpieczne — praca ta pokazuje, jak uczynić cyfrowe prowadzenie bardziej osobistym i bardziej naukowym.
Dlaczego tradycyjne aplikacje fitness zawodzą
Konwencjonalne systemy rekomendacyjne, takie jak te sugerujące filmy czy produkty, mają trudności w zastosowaniu do ćwiczeń. Często kopiują i powielają standardowe szablony, mają problemy z niewielką ilością danych dla nowych użytkowników i rzadko uwzględniają, jak twoje ciało zmienia się z dnia na dzień. Co gorsza, nie są zaprojektowane do podejmowania decyzji o wysokiej wadze, gdzie bezpieczeństwo ma znaczenie. Ogólnego przeznaczenia modele językowe dobrze radzą sobie z opisywaniem treningów, ale ponieważ są trenowane na szerokim tekscie z internetu, mogą „halucynować” ryzykowne porady lub pomijać ważne dni odpoczynku. Autorzy argumentują, że w planowaniu ćwiczeń — gdzie błędne wskazówki mogą prowadzić do kontuzji lub przetrenowania — AI musi być ugruntowane w weryfikowanej wiedzy sportowej i musi śledzić zmieniający się stan osoby w czasie.
Tworzenie pełnego obrazu osoby
W rdzeniu LLM-SPTRec znajduje się moduł tworzący szczegółowy snapshot każdego użytkownika. Zamiast przechowywać tylko wiek, płeć czy poziom doświadczenia, system łączy trzy rodzaje informacji: cechy statyczne (takie jak historia treningów), sygnały dynamiczne (np. tętno, zmienność rytmu serca, ocena snu i wcześniejsze treningi z urządzeń noszonych i dzienników) oraz cele opisane przez użytkownika w formie swobodnego tekstu. Model oparty na transformatorze — powiązany z technologią stojącą za nowoczesnymi modelami językowymi — uczy się wzorców w tych szeregach czasowych, np. jak ciężki trening wczoraj może wpłynąć na gotowość dziś. Mechanizm uwagi ocenia następnie, które sygnały są w danym momencie najważniejsze, łącząc je w jedną numeryczną reprezentację aktualnego stanu użytkownika.
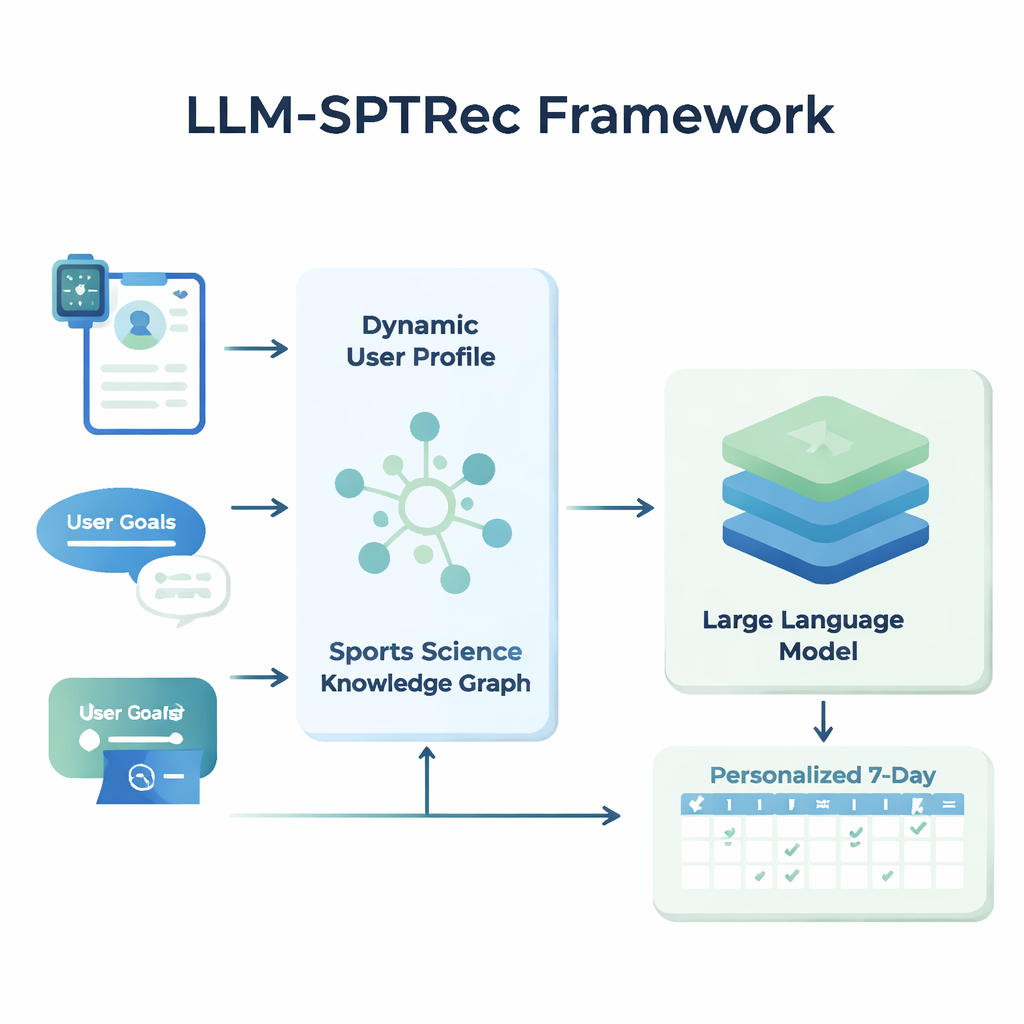
Nauczanie AI prawdziwej wiedzy z zakresu nauk o sporcie
Aby zapobiec niebezpiecznym lub pseudonaukowym rekomendacjom, badacze zbudowali Sports Science Knowledge Graph — w praktyce ustrukturyzowaną mapę zatwierdzonych przez ekspertów faktów. Zawiera ona tysiące wpisów łączących ćwiczenia z mięśniami, rodzajami ruchu, sprzętem, typowymi urazami oraz zasadami treningu, takimi jak progresywne przeciążenie czy specyficzność. Dla każdego użytkownika system wydobywa najbardziej istotne fragmenty tego grafu — na przykład które mięśnie angażuje wyciskanie na ławce i które ruchy są nieodpowiednie przy problemach z barkiem — i przekształca je w czytelny tekst, który jest podawany modelowi językowemu razem z profilem użytkownika. Model językowy otrzymuje następnie starannie zaprojektowany prompt, aby wygenerować wielodniowy plan treningowy w ustrukturyzowanym formacie, przestrzegając zasad takich jak rotacja grup mięśniowych między dniami czy unikanie znanych przeciwwskazań.
Utrzymywanie planów w strukturze, bezpieczeństwo i poprawa w czasie
LLM-SPTRec robi więcej niż tylko generuje tekst. Moduł walidacji sprawdza każdy plan względem twardych reguł, takich jak unikanie przeciążania tych samych głównych grup mięśniowych w kolejnych dniach, i wykrywa konflikty z ryzykami urazów zapisanymi w grafie wiedzy. Jeśli plan nie przejdzie tych kontroli, system ponownie wywołuje model, wyraźnie wskazując, co poszło nie tak, aż do wygenerowania bezpiecznego planu. Trening systemu odbywa się też w dwóch etapach. Najpierw uczy się na dużej kolekcji planów zaprojektowanych przez ekspertów. Następnie jest dopracowywany przy użyciu informacji zwrotnej, gdzie symulowane lub rzeczywiste oceny użytkowników nagradzają plany spójne, zgodne z celami i satysfakcjonujące do wykonywania, a surowo karzą niebezpieczne sugestie. Ta pętla informacji zwrotnej przesuwa model w kierunku rekomendacji lepiej działających w praktyce.
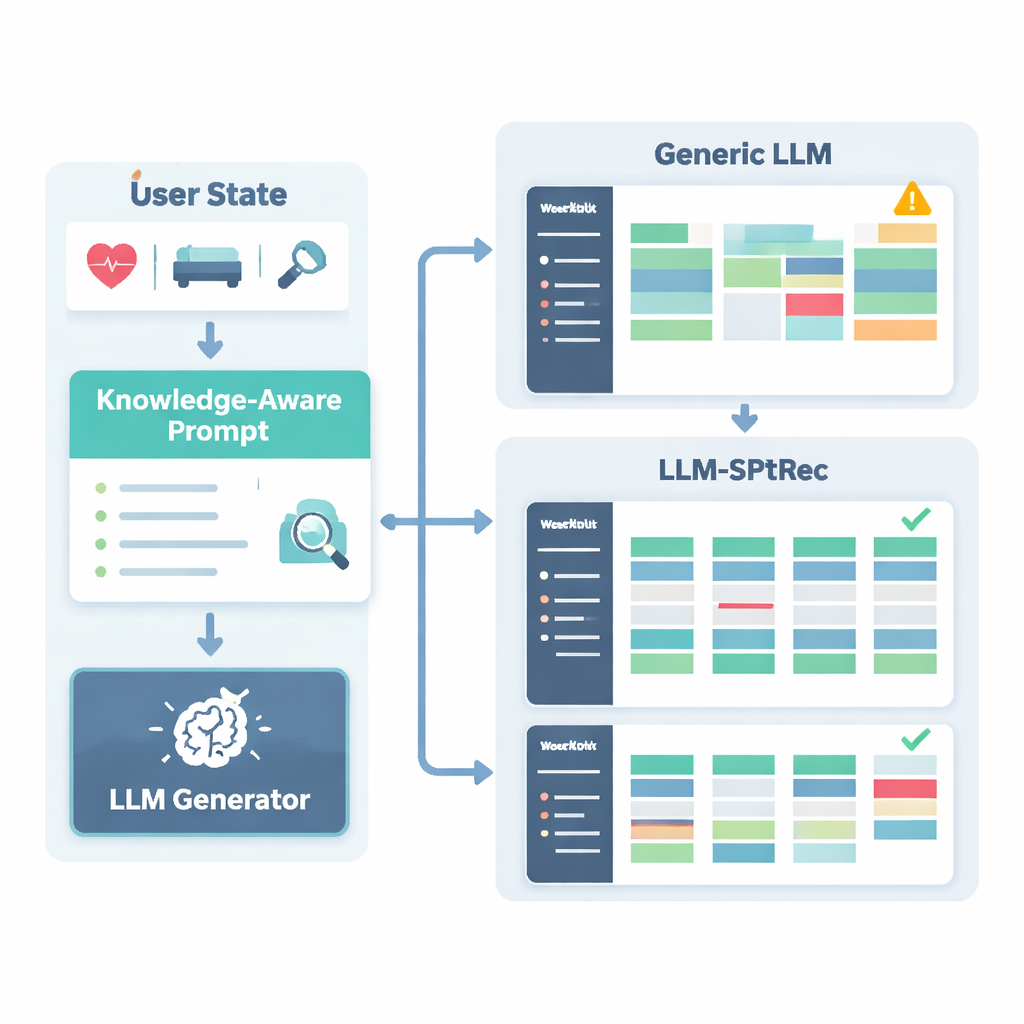
Jak system sprawdza się w praktyce
Autorzy przetestowali LLM-SPTRec na dużym, rzeczywistym zbiorze danych o nazwie SportFit-1M, który łączy zanonimizowane dane z aplikacji fitness i urządzeń noszonych, obejmując dziesiątki tysięcy użytkowników oraz miliony logów treningowych i zapisów fizjologicznych. Porównali swój system z silnymi punktami odniesienia: klasycznym filtrowaniem kolaboratywnym, modelem sekwencyjnym patrzącym jedynie na wcześniejsze wybory, nowoczesnym rekomendatorem opartym na grafie wiedzy oraz ramą opartą na ogólnego przeznaczenia modelu językowego. LLM-SPTRec pokonał wszystkie te metody nie tylko w doborze odpowiednich ćwiczeń, ale — co ważniejsze — w tworzeniu kompletnych planów, które eksperci ocenili jako bardziej spójne i bardziej zgodne z celami użytkowników. Przewidywane oceny satysfakcji użytkowników były wyższe, a małe badanie z udziałem certyfikowanych trenerów oceniło jego bezpieczeństwo jako znacznie lepsze niż w przypadku ogólnego modelu językowego bez sportowego ugruntowania.
Co to oznacza dla przyszłego cyfrowego coachingu
Dla laika wniosek jest taki, że inteligentne i bezpieczniejsze prowadzenie przez AI jest możliwe, gdy zbiegną się trzy składniki: bogate dane z twoich urządzeń, ekspercka wiedza sportowa zakodowana jako strukturalna wiedza oraz potężne modele językowe, których kreatywność jest starannie ukierunkowana i weryfikowana. LLM-SPTRec pokazuje, że takie połączenie może generować adaptacyjne, codzienne plany treningowe, które respektują zmieniający się stan twojego ciała i twoje osobiste cele, jednocześnie zmniejszając ryzyko szkodliwych lub bezsensownych porad. Patrząc w przyszłość, ta sama recepta może wykraczać poza treningi — do żywienia, rehabilitacji urazów czy nawet dobrego stanu psychicznego — wskazując na przyszłość, w której asystenci AI działają mniej jak ogólne chatboty, a bardziej jak kompetentni, dbający o bezpieczeństwo cyfrowi trenerzy.
Cytowanie: He, Z., Wang, J., Zhang, B. et al. Knowledge-grounded large language model for personalized sports training plan generation. Sci Rep 16, 6793 (2026). https://doi.org/10.1038/s41598-026-37075-z
Słowa kluczowe: spersonalizowany trening, AI w naukach o sporcie, polecenia fitness, dane z urządzeń noszonych, graf wiedzy