Clear Sky Science · pl
Dryf interpretacji w wyjaśnialnej SI przy szumie etykiet
Dlaczego wyjaśnienia SI mogą po cichu iść źle
Wielu ludzi polega dziś na sztucznej inteligencji nie tylko w kwestii odpowiedzi, lecz także powodów: dlaczego odmówiono kredytu? Dlaczego system oznaczył pacjenta jako wysokiego ryzyka? Badanie to pokazuje, że nawet gdy dokładność modelu SI wydaje się stabilna, opowieść o tym, dlaczego podjął taką decyzję, może się dramatycznie przesunąć, jeśli dane treningowe zawierają błędy. Ta ukryta zmiana w wyjaśnieniach — którą autorzy nazywają „dryfem interpretacji” — może wprowadzać w błąd profesjonalistów, którzy polegają na SI, by uzasadnić ważne decyzje.
Kiedy czyste dane spotykają nieporządne etykiety
Większość współczesnych systemów SI to „czarne skrzynki”, dające prognozy bez jasnych powodów. Aby zwiększyć przejrzystość, w wielu zastosowaniach sięga się po modele oparte na regułach przypominające ludzkie rozumowanie typu jeśli—to: na przykład „jeśli ciśnienie krwi jest wysokie i wiek > 60, to ryzyko jest wysokie”. Zbiory takich reguł są szczególnie atrakcyjne w obszarach wrażliwych jak opieka zdrowotna, prawo czy finanse, gdzie użytkownicy potrzebują sprawdzić i zaufać logice. Jednak dane z realnego świata rzadko bynajmniej nie są perfekcyjne. Częstym problemem jest szum etykiet — przypadki, w których rzekomo „poprawna odpowiedź” w danych treningowych jest błędna, np. błędnie zapisana diagnoza lub nieprawidłowo oznaczony wynik klienta. Choć wiadomo, że szum etykiet szkodzi jakości predykcji, jego wpływ na stabilność wyjaśnień SI nie był systematycznie badany.
Testowanie, jak wyjaśnienia znoszą szum
Autorzy ocenili, jak odporne są wyjaśnienia oparte na regułach, gdy etykiety są stopniowo psute. Wykorzystali cztery różne zestawy danych z obszaru opieki zdrowotnej, bankowości, chorób wątroby, a nawet teorii liczb, wszystkie przygotowane jako zadania przewidywania tak/nie. Porównano trzy metody uczenia reguł: dwa popularne, szybkie algorytmy (IREP i RIPPER) oraz bardziej kosztowną obliczeniowo metodę nazwaną Human Knowledge Models (HKM), która celowo dąży do tworzenia bardzo prostych, przypominających ludzkie zbiorów reguł. Dla każdej metody badacze wielokrotnie trenowali modele, losowo odwracając rosnący odsetek etykiet treningowych — od niemal idealnie czystych danych aż po bliskie kompletnego nonsensu. Równolegle śledzili dwie rzeczy: jak dobrze modele nadal predykują na czystym zbiorze testowym oraz jak bardzo nauczone reguły zmieniały się w porównaniu z tymi z danych bez szumu.
Dokładność stabilna, logika w ruchu
Na pierwszy rzut oka wyniki mogą uśpić czujność użytkowników. Przy umiarkowanych poziomach szumu, szczególnie dla metody HKM, wydajność predykcyjna wydawała się stosunkowo stabilna mierząc common F1 score. Jednak bliższa analiza zbiorów reguł ukazała inny obraz. Używając miary podobieństwa porównującej kolekcje reguł, autorzy stwierdzili, że nawet niewielkie ilości szumu etykiet szybko osłabiały nakładanie się między oryginalnymi a „zaszumionymi” wyjaśnieniami. Innymi słowy, model mógł nadal prawidłowo przewidywać wiele przypadków, lecz z coraz innych powodów. Bardziej złożone zbiory reguł okazały się szczególnie kruche: wraz ze wzrostem liczby warunków w regule, niewielkie zmiany w danych łatwiej łamały lub zastępowały te reguły, przyspieszając utratę stabilności interpretowalności.
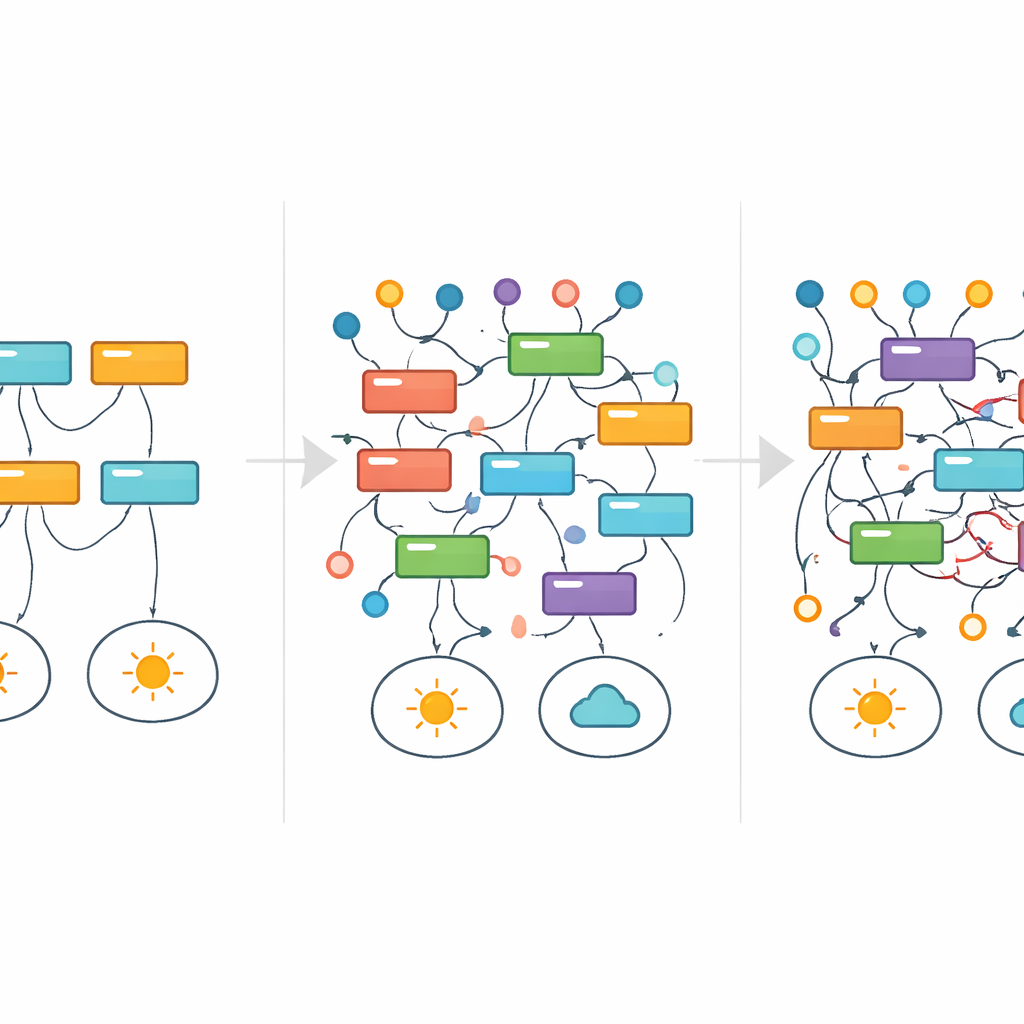
Śledzenie reguł, które pojawiają się i znikają
Aby zwizualizować, jak poszczególne wyjaśnienia przetrwały lub zawiodły wraz ze wzrostem szumu, badacze zapożyczyli narzędzie z medycyny: analizę przeżycia. Zamiast śledzić przeżycie pacjentów w czasie, śledzili, jak długo dana reguła pojawia się wśród najlepszych modeli w miarę wzrostu szumu etykiet. Zamiast stopniowo zanikać, wiele reguł przerywało działanie i pojawiało się ponownie — znak, że całkowicie różne wyjaśnienia mogą dominować przy różnych poziomach szumu, nawet dla tego samego zadania. W prostym zbiorze danych dotyczącym podzielności liczb, na przykład, czyste i matematycznie poprawne reguły były stopniowo zastępowane przez szersze przybliżenia, a ostatecznie przez zawiłe, pozornie arbitralne wzorce, które nadal pasowały do zniszczonych etykiet. Przez znaczną część tego procesu główne metryki wydajności nie sygnalizowały wyraźnie, że coś jest nie tak.
Co to oznacza dla osób polegających na SI
Główne przesłanie jest takie, że „godnej zaufania” SI nie można oceniać wyłącznie po dokładności. Nawet modele prezentujące logikę w formie zrozumiałych dla ludzi reguł mogą po cichu zmieniać swoje rozumowanie, gdy etykiety, z których uczą się, są niedoskonałe — a to właśnie sytuacja w większości baz danych z prawdziwego świata. Autorzy argumentują, że deweloperzy i regulatorzy powinni traktować stabilność wyjaśnień jako wymóg pierwszorzędny, obok dokładności i sprawiedliwości. Nowe metryki mierzące bezpośrednio, jak spójne pozostają wyjaśnienia modelu w obliczu szumu, oraz narzędzia ostrzegające użytkowników o dryfie interpretacji będą niezbędne, jeśli chcemy, by systemy SI opowiadały o świecie historie równie wiarygodne jak ich predykcje.
Cytowanie: Raikovskaia, A., Rakhimzhanov, N. & Pianykh, O.S. Interpretation drift in explainable AI under label noise. Sci Rep 16, 8528 (2026). https://doi.org/10.1038/s41598-026-37070-4
Słowa kluczowe: wyjaśnialna SI, szum etykiet, interpretowalność modelu, modele oparte na regułach, dryf interpretacji