Clear Sky Science · pl
Ewolucja wykrywania obiektów: od CNN-ów do transformatorów i fuzji multimodalnej
Nauka komputerów widzenia codziennych przedmiotów
Za każdym razem, gdy telefon oznacza znajomych na zdjęciu, samochód dostrzega pieszego, albo narzędzie medyczne uwydatnia guz na skanie, działa cicha, ale potężna technologia: wykrywanie obiektów. Ten przegląd wyjaśnia, jak wykrywanie obiektów szybko ewoluowało w ciągu ostatniej dekady — od wczesnych trików przetwarzania obrazów po dzisiejsze systemy oparte na transformatorach i wielu czujnikach — oraz dlaczego postęp ten ma znaczenie dla bezpieczniejszych ulic, inteligentniejszych robotów i dokładniejszych diagnoz medycznych.
Od pikseli do rozpoznawalnych rzeczy
Wykrywanie obiektów polega na znajdowaniu i oznaczaniu konkretnych elementów na zdjęciach lub wideo — samochodów, rowerzystów, zwierząt, struktur medycznych i innych. Artykuł zaczyna od zobrazowania, jak szeroko stosowana jest ta umiejętność: w autonomicznej jeździe, nadzorze, obrazowaniu medycznym i robotyce. Wczesne systemy opierały się na ręcznie zaprojektowanych regułach rozróżniania kształtów i tekstur, ale współczesne podejścia uczą się bezpośrednio z danych, wykorzystując uczenie głębokie. Obecnie dominują dwie duże rodziny: splotowe sieci neuronowe (CNN), które świetnie wykrywają lokalne wzorce, takie jak krawędzie i narożniki, oraz transformatory, które doskonale rozumieją szerszą scenę i relacje między odległymi obiektami. Razem definiują sposób, w jaki współczesne maszyny „widzą” świat.
Jak działają klasyczne silniki widzenia
Metody oparte na CNN wciąż napędzają wiele aplikacji czasu rzeczywistego. Przesuwają obrazy za pomocą małych filtrów, budując coraz bogatsze mapy cech, które następnie trafiają do modułów detekcji rysujących ramki ograniczające i przypisujących etykiety. Przegląd opisuje dwie główne strategie. Systemy dwustopniowe, takie jak Faster R-CNN, najpierw proponują prawdopodobne regiony obiektów, a potem je dopracowują — często osiągając wysoką dokładność kosztem obliczeń. Systemy jednokrokowe, jak rodzina YOLO, pomijają etap proponowania i przewidują ramki oraz etykiety w jednym przebiegu, wymieniając nieco dokładności na szybkość. Najnowsze wersje YOLOv5 i YOLOv8 zostały intensywnie dopracowane — z dodatkiem inteligentniejszych piramid cech dla małych obiektów, lekkich bloków konstrukcyjnych dla urządzeń brzegowych oraz usprawnionych funkcji straty — aby osiągać setki klatek na sekundę, pozostając konkurencyjnymi na trudnych benchmarkach.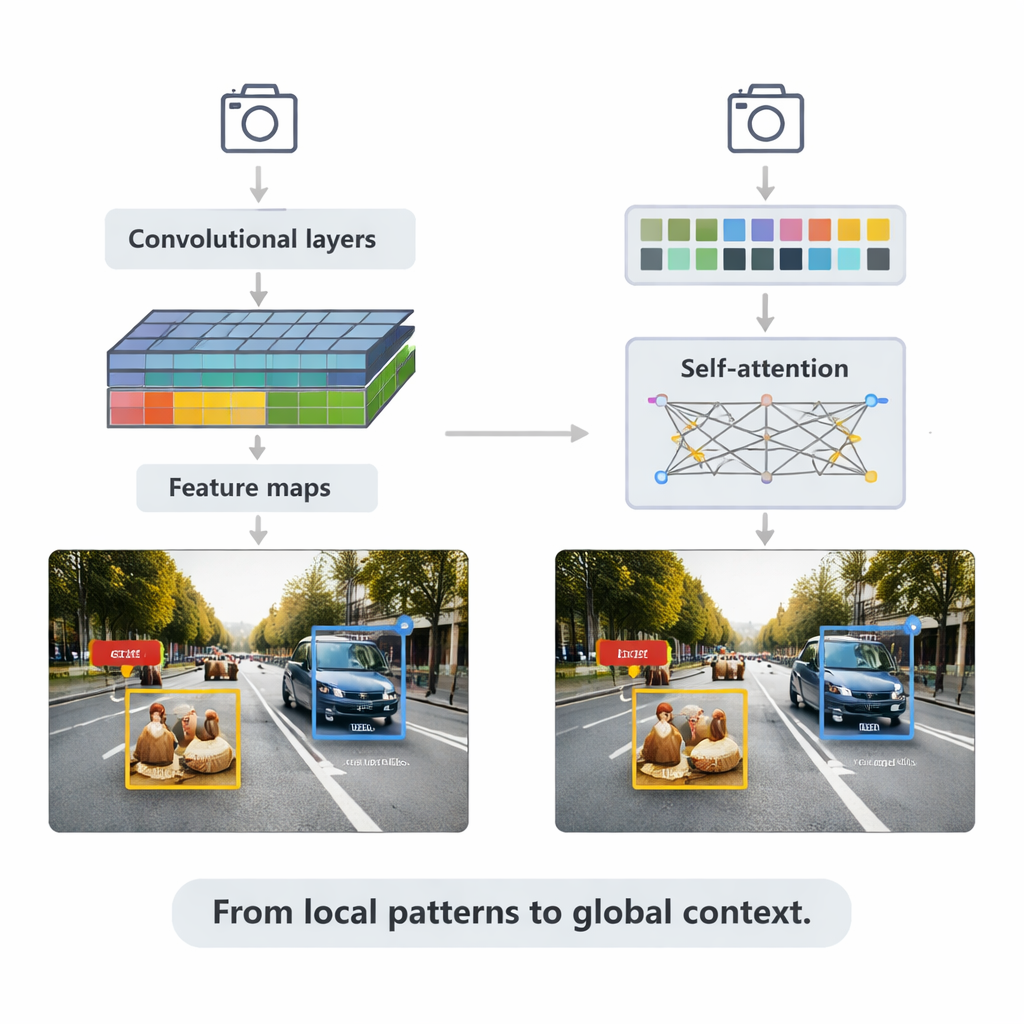
Transformatory i siła kontekstu
Artykuł przechodzi następnie do transformatorów — nowszej architektury zapożyczonej z modeli językowych. Zamiast skupiać się wyłącznie na lokalnych sąsiedztwach, transformatory używają „self-attention”, aby porównać każdy fragment obrazu z każdym innym fragmentem, ucząc się, które regiony są najistotniejsze dla konkretnej decyzji. Detection Transformer (DETR) i jego następcy eliminują wiele ręcznie projektowanych trików, dążąc do czystszych, end-to-end’owych potoków. Warianty takie jak Deformable DETR i RT-DETR zmniejszają koszt obliczeniowy i przyspieszają trening, pozwalając transformatorom działać w czasie rzeczywistym i osiągać jedne z najwyższych wyników w powszechnie używanym benchmarku COCO. Modele te szczególnie błyszczą w złożonych scenach z nakładającymi się obiektami i mylącymi tłami, gdzie kontekst globalny pomaga odróżnić na przykład pieszego częściowo ukrytego za samochodem.
Mieszanie kamer, laserów i języka
Warunki rzeczywiste — mgła, ciemność, odblaski, bałagan — często pokonują systemy z jednym czujnikiem. Istotną częścią przeglądu jest fuzja multimodalna: łączenie danych z klasycznych kamer (RGB), czujników głębokości, takich jak LiDAR, kamer termicznych, a nawet opisów tekstowych. Autorzy przedstawiają przejrzystą taksonomię sposobów łączenia: fuzja wczesna miesza surowe dane na wejściu, fuzja środkowa scala wyuczone cechy wewnątrz sieci, a fuzja późna łączy wyjścia oddzielnych detektorów na końcu. Nowoczesne „fusion transformers” wykorzystują mechanizmy uwagi do wyrównywania tych strumieni, tak że precyzyjne pomiary odległości z LiDAR, bogaty wygląd z obrazów RGB i semantyczne wskazówki z języka wzajemnie się wzmacniają. Podejście to poprawia wykrywanie w autonomicznej jeździe, obrazowaniu medycznym, analizie wideo oraz scenach bogatych w tekst.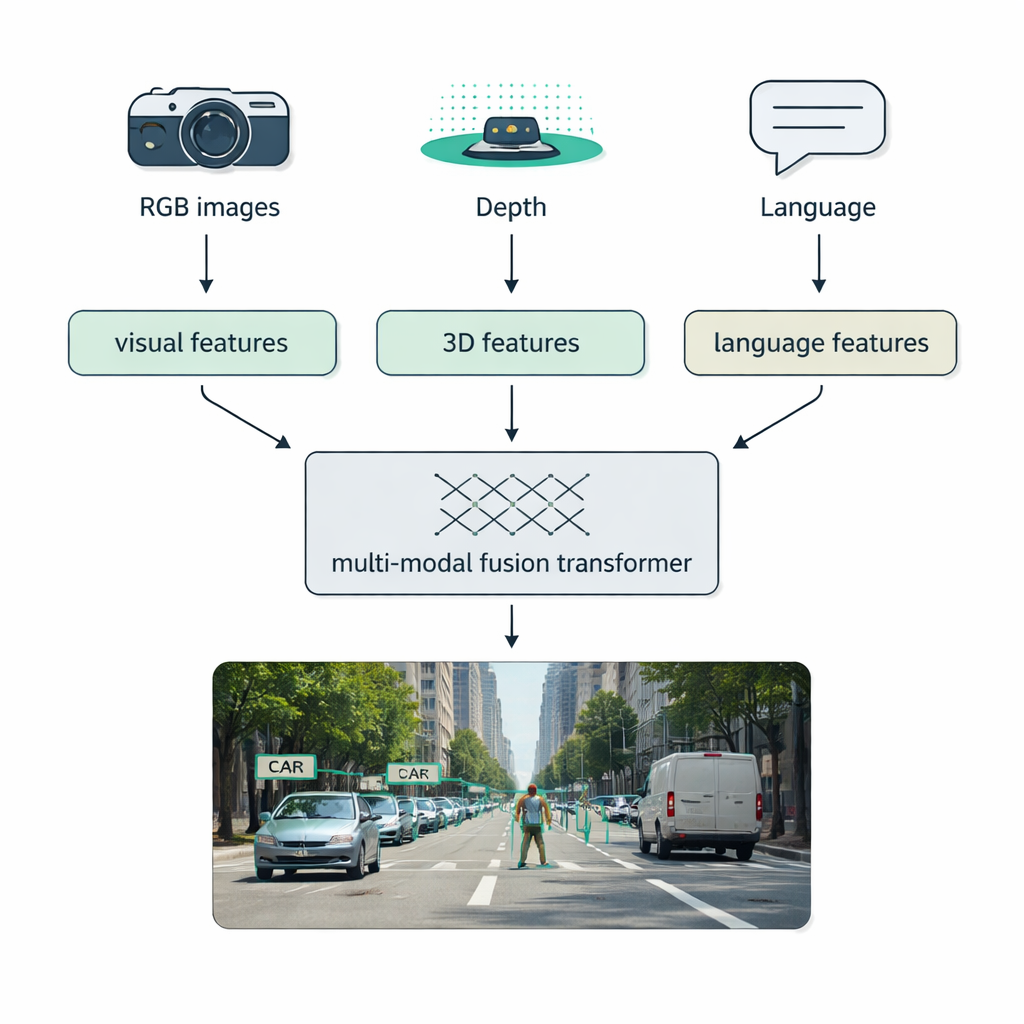
Benchmarki, ograniczenia i co dalej
W testach standardowych, takich jak MS COCO, przegląd porównuje detektory oparte na CNN i transformatorach pod względem zarówno dokładności, jak i szybkości. Klasyczne dwustopniowe CNN-y pozostają silne, lecz wolniejsze; modele w stylu YOLO dominują na lekkim sprzęcie; a systemy oparte na transformatorach prowadzą pod względem dokładności, jednocześnie zmniejszając dystans w szybkości. Specjalistyczne metody na podczerwień osiągają bardzo wysokie wyniki w warunkach ograniczonej widoczności. Mimo to pozostają trudne problemy: bardzo małe lub ekstremalnie duże obiekty, silne zasłonięcia, zmienne warunki pogodowe i oświetleniowe oraz konieczność niezawodnej pracy na maleńkich urządzeniach. Patrząc w przyszłość, autorzy wskazują trendy w kierunku zunifikowanych modeli percepcyjnych obsługujących wykrywanie, segmentację i tworzenie opisów razem, oraz „modeli fundamentowych”, które łączą widzenie i język, by rozpoznawać obiekty opisane zwykłym tekstem, nawet jeśli nie były oznaczone w danych treningowych.
Dlaczego to ma znaczenie w życiu codziennym
Dla osób niebędących specjalistami kluczowy przekaz jest taki, że wykrywanie obiektów przechodzi od wąskich, ręcznie dostrajanych systemów do elastycznych, ogólnego przeznaczenia silników widzenia, które potrafią dostosować się do nowych zadań, środowisk i czujników. CNN-y dostarczają szybkie, efektywne rozpoznawanie wzorców; transformatory dokładają bardziej globalne, świadome kontekstu rozumienie; a fuzja multimodalna łączy dodatkowe wskazówki z głębokości, temperatury i języka. Razem te postępy obiecują samochody lepiej przewidujące zagrożenia, narzędzia pewniej wspierające lekarzy oraz urządzenia domowe bezpieczniej i inteligentniej wchodzące w interakcje z otoczeniem — przybliżając percepcję maszyn do bogactwa ludzkiego widzenia.
Cytowanie: Wang, Z., Chen, Y., Gu, Y. et al. The evolution of object detection from CNNs to transformers and multi-modal fusion. Sci Rep 16, 7517 (2026). https://doi.org/10.1038/s41598-026-37052-6
Słowa kluczowe: wykrywanie obiektów, widzenie komputerowe, uczenie głębokie, modele transformerowe, fuzja multimodalna