Clear Sky Science · pl
Jednolity wielomodalny framework transformera do przewidywania nawrotu raka piersi i analizy przeżycia
Dlaczego przewidywanie nawrotu nowotworu ma znaczenie
Dla wielu kobiet zakończenie leczenia raka piersi przynosi ulgę, ale pozostawia też uporczywe pytanie: czy choroba wróci, a jeśli tak, to kiedy i jak ciężko? Obecne plany kontroli po leczeniu często opierają się na uogólnionych średnich, a nie na unikalnym zestawie czynników charakteryzujących każdą pacjentkę. W tym badaniu przedstawiono nowy system sztucznej inteligencji, którego celem jest dostarczenie lekarzom wyraźniejszego, bardziej spersonalizowanego obrazu zarówno ryzyka nawrotu raka piersi, jak i oczekiwanego czasu pozostawania pacjentki wolnej od choroby.
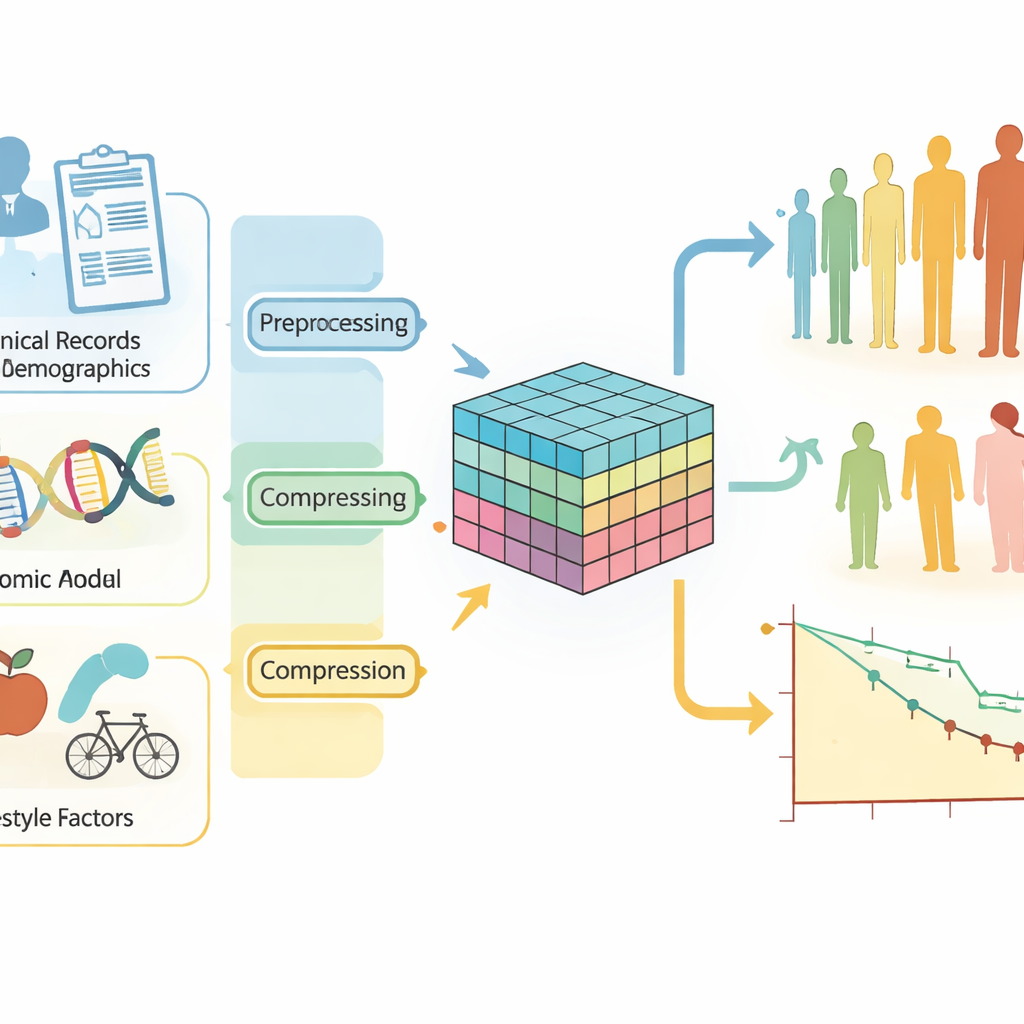
Łączenie wielu rodzajów danych pacjenta
Nawroty raka piersi nie są jednym, jednolitym wynikiem. Mogą pojawić się jako nowy guz w tej samej piersi, przerzuty do pobliskich węzłów chłonnych lub odległe przerzuty w narządach, takich jak płuca czy kości. Każdy z tych wzorców niesie inne implikacje dla leczenia i przeżycia. Jednocześnie ryzyko kształtowane jest przez wiele powiązanych wpływów: cechy guza, aktywność genów, wiek, status menopauzalny, masę ciała, palenie i inne. Tradycyjne narzędzia statystyczne mają trudności w obliczeniach dla takiego miksu danych klinicznych, genetycznych i związanych ze stylem życia. Zazwyczaj zakładają proste, liniowe relacje i często opierają się na ręcznie skonstruowanych skalach ryzyka, które nie oddają rzeczywistej złożoności nowoczesnych danych onkologicznych.
Jednolity inteligentny model zamiast oddzielnych narzędzi
Naukowcy zaprojektowali jedną ramę uczenia głębokiego, która realizuje jednocześnie dwa zadania: przewiduje, który z czterech typów nawrotu pacjentka najprawdopodobniej doświadczy, oraz szacuje czas wystąpienia tego zdarzenia za pomocą analizy przeżycia. Zamiast tworzyć oddzielne modele dla pytań „czy nastąpi nawrot?” i „kiedy nastąpi nawrot?”, system uczy się obu odpowiedzi wspólnie. Pod maską wykorzystuje architekturę transformera — tę samą rodzinę modeli, która napędza wiele nowoczesnych narzędzi językowych — aby odkrywać subtelne wzorce i dalekosiężne interakcje w danych. To zunifikowane podejście ma odzwierciedlać sposób myślenia onkologów, którzy rozważają wiele wskazówek jednocześnie, zamiast wykonywać izolowane kalkulacje.
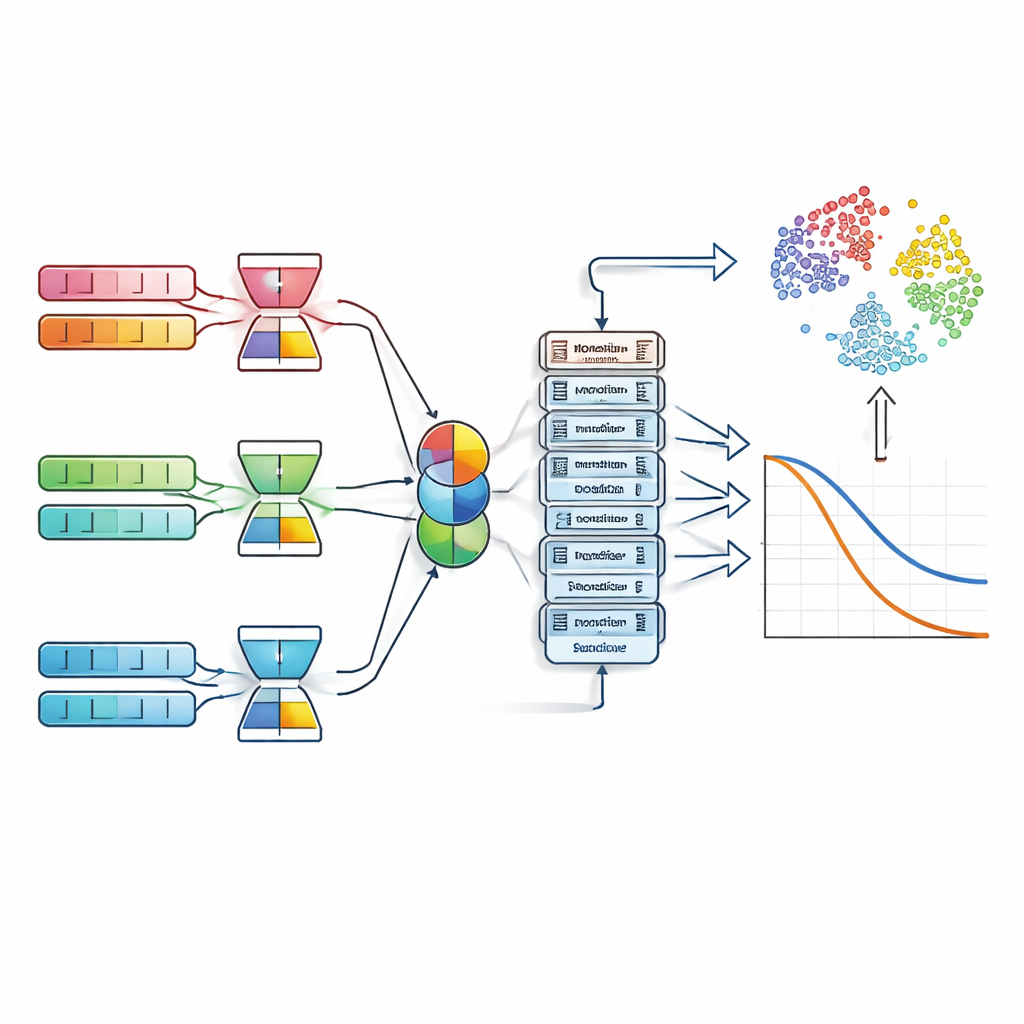
Jak system rozpoznaje wzorce w danych zdrowotnych
Aby zasilić model, zespół zebrał dużą, wieloośrodkową kolekcję danych o raku piersi z pięciu dobrze znanych źródeł. Zaliczały się do niej tysiące pacjentek z szczegółowymi pomiarami klinicznymi, profilami ekspresji genów, informacjami demograficznymi i wskaźnikami stylu życia. Ponieważ takie dane mogą być szumne i wysokowymiarowe — zwłaszcza dziesiątki tysięcy pomiarów aktywności genów — system najpierw przepuszcza każdy typ danych przez „autoenkoder odszumiający”. Ten etap kompresuje każdą modalność do czystszej, zwartej reprezentacji, która zachowuje ważne sygnały biologiczne, jednocześnie filtrując przypadkowość.
Nauka, co jest najważniejsze dla każdej pacjentki
Po kompresji model nie łączy po prostu wszystkich cech w jedną masę. Zamiast tego stosuje mechanizm uwagi zależnej od modalności, który uczy się, jaką wagę przypisać informacjom klinicznym, genetycznym lub związanym ze stylem życia dla każdej osoby. U niektórych pacjentek dominować mogą rozmiar guza i status receptorów hormonalnych; u innych bardziej istotny może być konkretny wzorzec genowy lub historia palenia. Te ważone sygnały są scalane w pojedynczy profil pacjentki i przetwarzane przez nałożone warstwy transformera, które za pomocą mechanizmu self-attention modelują, jak różne czynniki ryzyka współdziałają. Z tej wspólnej reprezentacji jedna gałąź przewiduje typ nawrotu, podczas gdy druga estymuje ciągły wskaźnik ryzyka, który można przekształcić w krzywe przeżycia na pięć i dziesięć lat.
Wydajność, walidacja i interpretowalność
W testach na pięciu zbiorach danych jednolity system konsekwentnie przewyższał standardowe metody, takie jak regresja logistyczna, maszyny wektorów nośnych, lasy losowe, klasyczne modele przeżycia Coxa i prostsze sieci neuronowe. Osiągał około 98–99% dokładności w klasyfikacji typu nawrotu oraz wysoki wskaźnik zgodności (concordance index) — ustalony miernik, jak dobrze przewidywany porządek przeżycia odpowiada rzeczywistości. Eksperymenty międzyzbiorowe, w których model trenowano na jednej kohorcie i testowano na innej, wykazały, że generalizuje on lepiej niż konkurencyjne podejścia. Aby uniknąć stania się tajemniczą „czarną skrzynką”, autorzy użyli także narzędzi wyjaśniających, które uwypuklają, które cechy najsilniej wpłynęły na daną prognozę. Wielkość guza, status HER2, palenie, status menopauzalny, wiek w momencie rozpoznania oraz mutacje BRCA1 okazały się szczególnie ważne, co dobrze koresponduje z aktualnym rozumieniem medycznym.
Co to oznacza dla pacjentek i lekarzy
Główne przesłanie badania jest takie, że jeden, starannie zaprojektowany system sztucznej inteligencji może integrować wiele strumieni informacji, by dostarczyć bogatszy, bardziej wiarygodny obraz ryzyka nawrotu raka piersi i przeżycia. Choć nadal wymaga prospektywnego przetestowania w realnych warunkach klinicznych, ta rama mogłaby pewnego dnia pomóc lekarzom dopasować harmonogramy nadzoru, wybierać terapie i udzielać pacjentkom porad z większą pewnością. Dla pacjentek może to oznaczać plany kontroli lepiej odpowiadające ich rzeczywistemu poziomowi ryzyka — zmniejszając niepotrzebny niepokój i badania u niektórych, a jednocześnie identyfikując inne, które mogą skorzystać na bliższym nadzorze lub bardziej agresywnym leczeniu.
Cytowanie: Malik, S., Patro, S.G.K., Al-Nussairi, A.K.J. et al. A unified multi modal transformer framework for breast cancer recurrence prediction and survival analysis. Sci Rep 16, 8334 (2026). https://doi.org/10.1038/s41598-026-37046-4
Słowa kluczowe: nawrot raka piersi, predykcja przeżycia, wielomodalne uczenie głębokie, model transformera, spersonalizowana onkologia