Clear Sky Science · pl
Określanie stanu funkcjonalnego mobilności w elektronicznej dokumentacji medycznej przy użyciu dużych modeli językowych
Dlaczego zdolność chodzenia to silny wskaźnik stanu zdrowia
W miarę jak ludzie żyją dłużej, lekarze zwracają coraz większą uwagę nie tylko na długość życia, lecz także na to, jak dobrze potrafimy się poruszać, chodzić i dbać o siebie. Trudności z wstawaniem z krzesła, wchodzeniem po schodach czy poruszaniem się po mieście często ujawniają się na długo przed nagłym pogorszeniem stanu zdrowia. Najszczegółowsze opisy codziennych umiejętności pacjenta zwykle jednak ukryte są w notatkach lekarskich i terapeutycznych zapisanych w formie tekstu wolnego w elektronicznej dokumentacji medycznej, gdzie komputery mają do nich utrudniony dostęp. W tym badaniu sprawdzono, czy współczesne duże modele językowe — ten sam rodzaj sztucznej inteligencji, który napędza wiele chatbotów — potrafią wiarygodnie czytać takie notatki i przekształcać opisy ruchu w ustrukturyzowane, przeszukiwalne informacje.
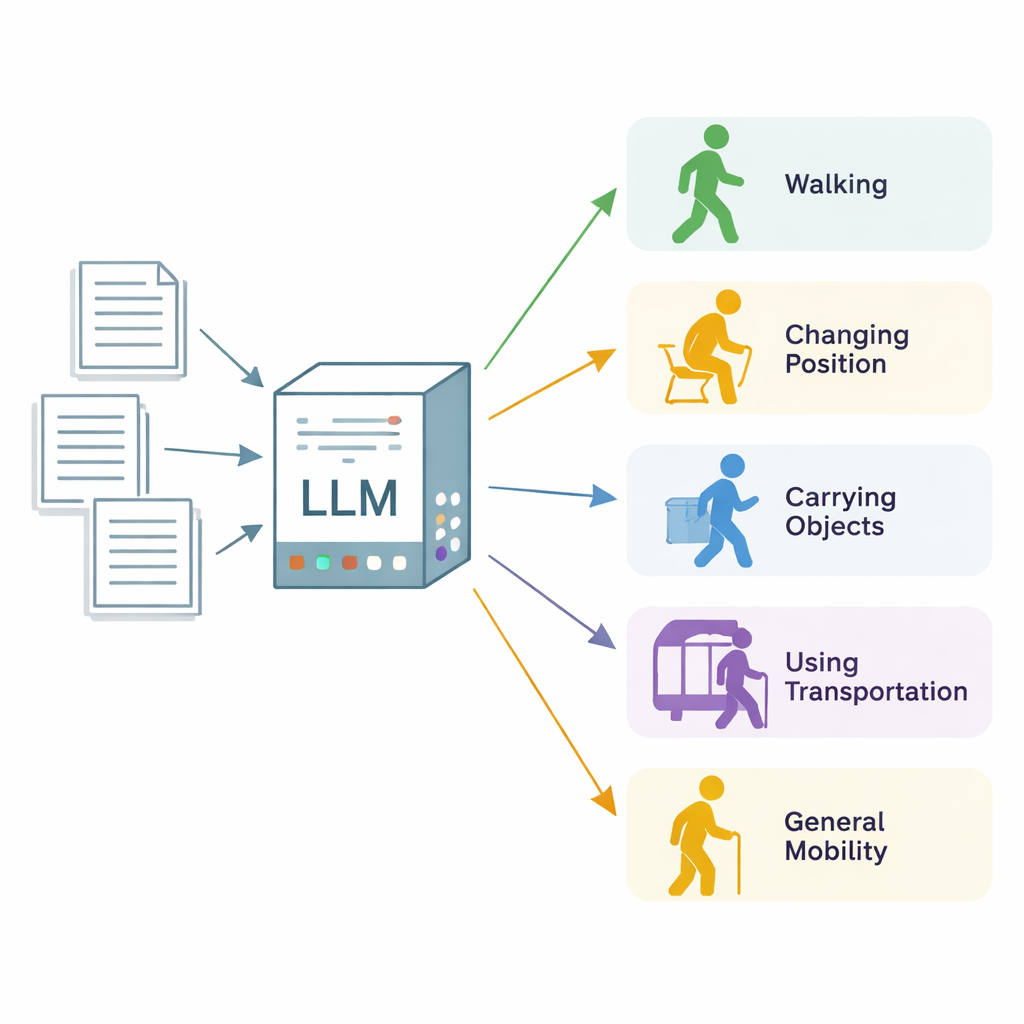
Przekształcanie nieuporządkowanych notatek w użyteczne dane o mobilności
Badacze skupili się na „stanie funkcjonalnym mobilności”, szerokim pojęciu obejmującym, jak dobrze osoba zmienia pozycję ciała, chodzi, przenosi i obsługuje przedmioty, korzysta z transportu i porusza się w codziennym życiu. Wykorzystali 600 rzeczywistych not klinicznych z trzech placówek medycznych w Minnesocie i Wisconsin, głównie z wizyt fizjoterapeutycznych i terapii zajęciowej, oraz zestaw bardziej ogólnych notatek z przychodni. Eksperci‑anotatorzy przejrzeli każdą notatkę sekcja po sekcji i oznaczyli każdy fragment opisujący jedną z pięciu kategorii mobilności, zaznaczając, czy pacjent był wyraźnie ograniczony („upośledzony”), czy funkcjonował normalnie („nieupośledzony”). Te eksperckie oznaczenia posłużyły jako złoty standard do oceny systemu AI.
Jak model AI został nauczony czytać jak klinicysta
Zespół użył Llama 3, otwartoźródłowego dużego modelu językowego, uruchomionego na bezpiecznych serwerach lokalnych, tak aby dane pacjentów nigdy nie opuszczały systemu ochrony zdrowia. Zamiast trenować model od zera, opracowali starannie sformułowane prompt‑y — zestawy pisemnych instrukcji i definicji — które uczyły model, na co zwracać uwagę. Wypróbowali podejście „zero‑shot”, zawierające jedynie instrukcje, oraz „few‑shot”, które dodatkowo zawiera kilka przykładowych notatek. Następnie przeanalizowali błędy modelu i przygotowali prompt „oparty na błędach”, który precyzował, co uwzględniać, czego nie brać pod uwagę (np. plany leczenia na przyszłość) oraz jak radzić sobie z trudnymi przypadkami, takimi jak upadki, zawroty głowy czy używanie wózka inwalidzkiego. AI proszono, by dla każdej sekcji notatki i każdej kategorii mobilności odpowiadała, czy mobilność w ogóle jest wspomniana, a jeśli tak — czy pacjent jest upośledzony.
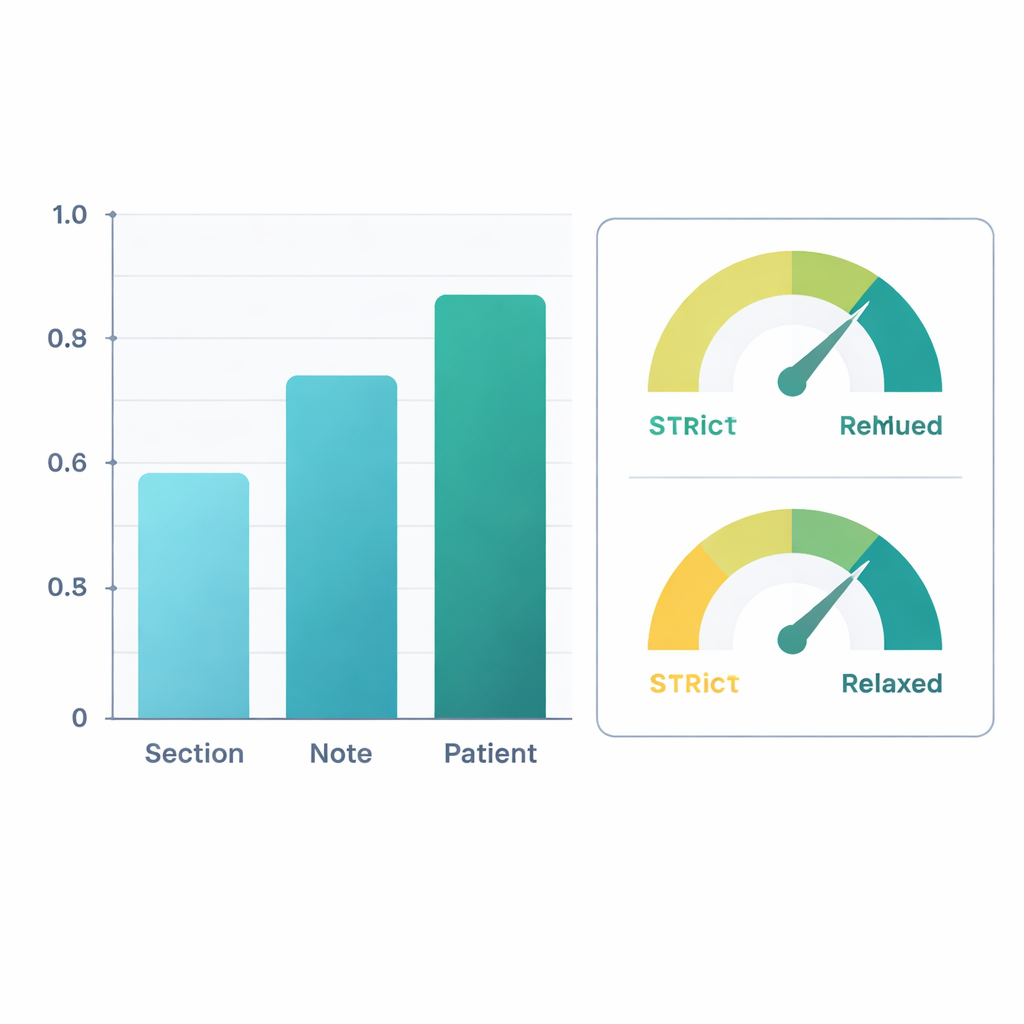
Mocne wyniki poprawiają się na poziomie pacjenta
W porównaniu z oznaczeniami ekspertów, udoskonalony system radził sobie dobrze. Na poziomie całych pacjentów — łącząc informacje ze wszystkich ich notatek — AI osiągnęła miarę F1 (powszechnie stosowany wskaźnik dokładności) około 0,88 w wykrywaniu informacji o mobilności i 0,90 w ocenie, czy osoba była upośledzona. Oznacza to, że jej oceny były zbliżone do ocen ludzkich recenzentów. Nieco słabiej wypadała przy analizie pojedynczych sekcji notatek, gdzie sformułowania bywają skąpe lub niejednoznaczne, ale dokładność rosła w miarę łączenia informacji na poziomie całych notatek, a następnie wszystkich notatek danego pacjenta. W drugiej analizie badacze uznali za poprawne także „klinicznie uzasadnione wnioski” — na przykład przyjęcie, że silny ból kolana przy chodzeniu prawdopodobnie ogranicza chodzenie, nawet jeśli nie jest to wyrażone wprost. W tym, bardziej przychylnym ujęciu, F1‑score na poziomie pacjenta wzrósł powyżej 0,96 dla ekstrakcji i 0,95 dla klasyfikacji upośledzenia.
Co AI zrobiła źle — i dlaczego to nadal ma znaczenie
Większość błędów wynikała z tego, że model czytał między wierszami. Często wyciągał wnioski o problemach z mobilnością na podstawie bólu, zawrotów głowy czy planów terapii na przyszłość, nawet gdy notatka nie stwierdzała wyraźnie ograniczeń pacjenta. Inne błędy odzwierciedlały obszary niejasne w definicjach, na przykład czy nawracające upadki traktować jako problem z chodzeniem, czy jako problem z równowagą przy zmianie pozycji. Klasa nazwana „mobilność, nieokreślona” — mająca uchwycić aktywności codzienne i ćwiczenia — była szczególnie trudna do jednoznacznego określenia. Pomimo tych trudności, popełniane błędy były zwykle sensowne z klinicznego punktu widzenia, a nie losowe czy dziwaczne. Uruchamiając model deterministycznie (bez wbudowanego losowego zachowania) na zabezpieczonych lokalnych serwerach, zespół zapewnił też, że wyniki są powtarzalne, a prywatność pacjentów zachowana.
Jak to może zmienić opiekę nad osobami starszymi
Dla laika wniosek jest taki, że system AI potrafi już wystarczająco dobrze czytać rutynowe notatki lekarskie i terapeutyczne, by podsumować, jak dobrze pacjenci się poruszają i z jakimi trudnościami się borykają. Oznacza to, że systemy ochrony zdrowia mogłyby śledzić zmiany w chodzeniu, równowadze i codziennych czynnościach w czasie bez konieczności wprowadzania nowych ankiet czy badań, identyfikować osoby o wysokim ryzyku upadków lub hospitalizacji oraz wskazywać tych, którzy mogliby skorzystać na fizjoterapii lub ocenie bezpieczeństwa w domu. Przekształcając miliony notatek w formie tekstu wolnego w ustrukturyzowane dane o mobilności, podejście to pomaga lekarzom zobaczyć szerszy obraz wpływu starzenia się i chorób na codzienne życie — przybliżając opiekę zdrowotną do naprawdę spersonalizowanej medycyny skoncentrowanej na funkcjonowaniu.
Cytowanie: Liu, X., Garg, M., Jia, H. et al. Mobility functional status ascertainment in electronic health records using large language models. Sci Rep 16, 6045 (2026). https://doi.org/10.1038/s41598-026-37025-9
Słowa kluczowe: mobilność, elektroniczna dokumentacja medyczna, duże modele językowe, stan funkcjonalny, AI kliniczna