Clear Sky Science · pl
Benchmark do oceny efektywności zadawania pytań diagnostycznych przez LLM w rozmowach z pacjentami
Dlaczego inteligentniejsze pytania medyczne mają znaczenie
Kiedy idziesz do lekarza, pierwsza diagnoza rzadko opiera się na jednym objawie, który wymienisz. Zamiast tego lekarze zadają serię pytań uzupełniających — o czas wystąpienia, nasilenie, powiązane problemy — aby stopniowo zawęzić możliwości. Mimo dużych możliwości współczesnych systemów AI, większość z nich nadal jest testowana tak, jakby zdawały testy wielokrotnego wyboru, a nie rozmawiały z prawdziwymi ludźmi. W artykule wprowadzono Q4Dx, nowy sposób oceny, jak dobrze duże modele językowe (LLM) potrafią pełnić rolę „dociekliwego lekarza”: wybierać właściwe pytania, we właściwej kolejności, by efektywnie dojść do właściwej diagnozy.
Od pytań egzaminacyjnych do prawdziwych rozmów
Większość istniejących testów AI w medycynie dostarcza modelom uporządkowane, w pełni określone przypadki — jak zadanie z podręcznika — i prosi o wybór diagnozy. To pokazuje, co system „wie”, ale nie jak zachowa się w nieporządnej, rzeczywistej rozmowie z pacjentem, który zapomina szczegółów lub opisuje objawy potocznym językiem. Autorzy argumentują, że to poważna luka. W klinice informacje wypływają powoli i często nieprecyzyjnie; umiejętność dobrego klinicysty polega zarówno na tym, co potrafi, jak i na tym, co i jak pyta. Q4Dx został zaprojektowany, by zmniejszyć tę przepaść, przesuwając uwagę z tworzenia odpowiedzi na statyczne pytania na strategię zadawania pytań w czasie.
Tworzenie realistycznych historii pacjentów
Aby zbudować to nowe środowisko testowe, badacze zaczynają od starannie dobranego źródła medycznego łączącego konkretne choroby z typowymi zestawami objawów. Losowo wybierają 100 takich par choroba–objaw i następnie używają modelu AI, aby przekształcić sterylne listy objawów w naturalnie brzmiące opisy pacjenta — historie, jakie ktoś mógłby rzeczywiście opowiedzieć w gabinecie. Z każdego pełnego przypadku generują krótsze wersje, w których wymienionych jest tylko około 80% lub 50% kluczowych objawów. To kontrolowane „ukrywanie” informacji pozwala badać, jak różne modele adaptują się, gdy ważne wskazówki są brakujące lub tylko zasugerowane. Kontrole nakładania się objawów potwierdzają, że krótsze wersje naprawdę zawierają mniej użytecznych informacji, a nie tylko mniej słów.
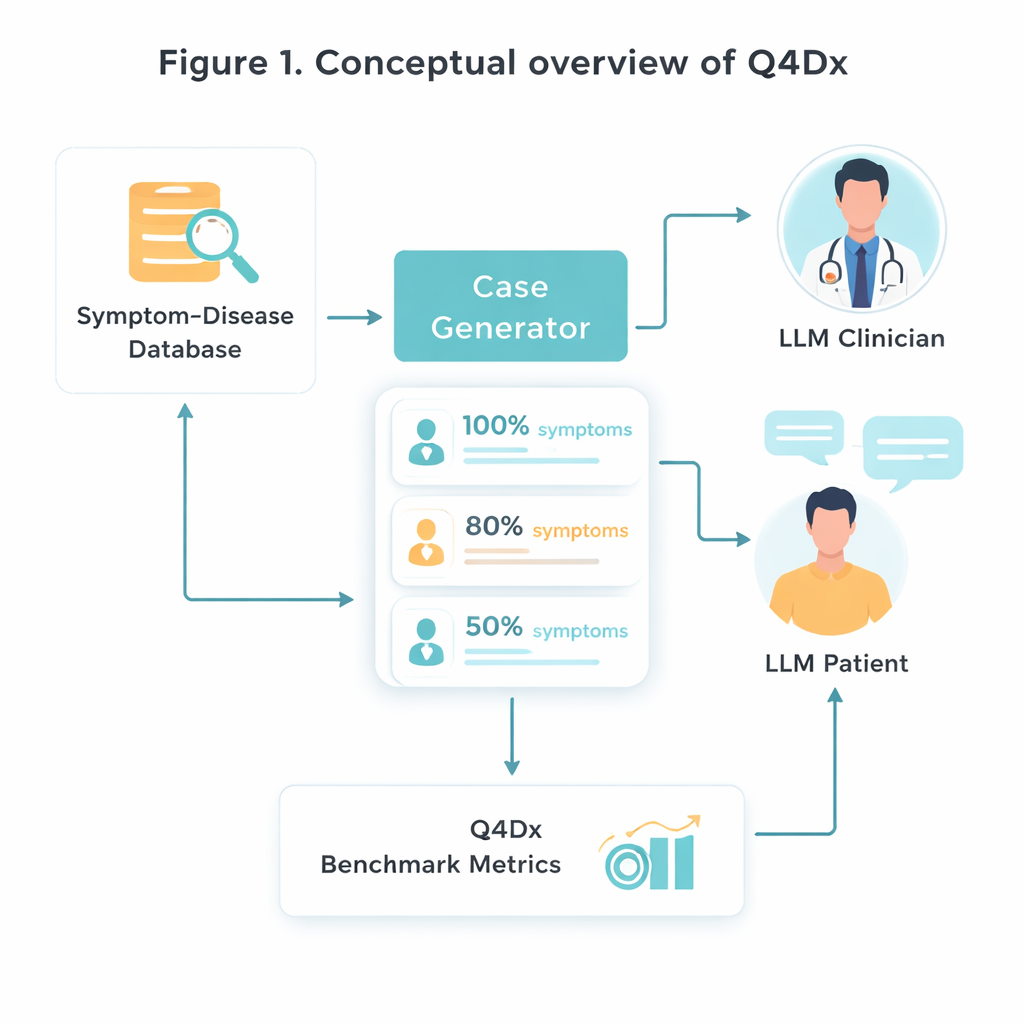
Symulowane dialogi lekarz–pacjent
Rdzeniem Q4Dx jest duża kolekcja symulowanych rozmów między dwoma agentami AI. Jeden odgrywa rolę pacjenta, mając pełny dostęp do podstawowej choroby i pełnego zestawu objawów. Drugi działa jako lekarz: na początku widzi tylko częściowy, mogący być niejasnym opis przypadku i musi zdecydować, o co zapytać dalej. Po każdej odpowiedzi pacjenta agent‑lekarz formułuje diagnozę wstępną, tworząc krok po kroku ślad ewolucji swojego rozumowania. Rejestrując wszystkie pytania, odpowiedzi i pośrednie przypuszczenia, benchmark uchwyca nie tylko to, czy model ma rację, ale jak do tego dochodzi. Sekwencje pytań generowane przez AI są używane jako strategie odniesienia — nie jako perfekcyjna prawda medyczna, lecz jako spójny wzorzec, względem którego można porównywać przyszłe modele, a nawet ludzkich stażystów.
Mierzenie dobrych pytań, nie tylko poprawnych odpowiedzi
Aby ocenić wydajność, autorzy zaprojektowali trzy proste, lecz komplementarne miary. Zero‑Shot Diagnostic Accuracy (ZDA) pyta: jeśli dasz modelowi cały przypadek od razu, czy potrafi natychmiast nazwać właściwą chorobę? Mean Questions to Correct Diagnosis (MQD) odzwierciedla efektywność: średnio ile pytań do pacjenta model potrzebuje, zanim po raz pierwszy trafi na poprawną diagnozę, przy limicie pięciu pytań? Wreszcie Interrogation Sequence Efficiency (ISE) ocenia jakość samej sekwencji pytań — jak bardzo znaczeniowo pytania wybrane przez model są zbliżone do sekwencji referencyjnej. Używając tych metryk, zespół pokazuje, że silny model ogólnego przeznaczenia (GPT‑4.1) diagnozuje poprawnie około połowy przypadków przy pełnych informacjach, ale jego dokładność spada, gdy objawy są ukrywane. Jednocześnie jego interaktywne sesje zwykle kończą się powodzeniem po zaledwie kilku trafnych pytaniach, a zadawane pytania z kolejnych tur coraz bardziej zbliżają się do strategii przypominających ekspertów.

Co to oznacza dla przyszłej AI w medycynie
Dla osób niebędących specjalistami przesłanie tej pracy jest proste: w medycynie zadawanie trafnych pytań jest równie ważne jak posiadanie prawidłowych odpowiedzi, i AI powinno być oceniane pod kątem obu tych aspektów. Q4Dx oferuje wielokrotnego użytku, publicznie dostępne ramy do robienia dokładnie tego. Dostarczając realistyczne historie pacjentów z różnym stopniem brakujących informacji, szczegółowe ślady rozmów i jasne miary zarówno dokładności, jak i efektywności, benchmark pozwala badaczom porównywać różne systemy AI, a nawet konfrontować je z klinicystami w kontrolowanych warunkach. Z czasem narzędzia takie jak Q4Dx mogą pomóc szkolić bezpieczniejszych, bardziej niezawodnych asystentów klinicznych i poprawić sposób, w jaki lekarze i studenci uczą się wywiadu diagnostycznego — ostatecznie wspierając lepszą opiekę nad prawdziwymi pacjentami.
Cytowanie: Werthaim, M., Kimhi, M., Apartsin, A. et al. A benchmark for evaluating diagnostic questioning efficiency of LLMs in patient conversations. Sci Rep 16, 6121 (2026). https://doi.org/10.1038/s41598-026-37022-y
Słowa kluczowe: sztuczna inteligencja medyczna, rozumowanie diagnostyczne, dialog kliniczny, duże modele językowe, strategia zadawania pytań