Clear Sky Science · pl
MQADet: plug-and-play — sposób na ulepszenie detekcji obiektów o otwartym słownictwie poprzez multimodalne odpowiadanie na pytania
Dlaczego inteligentniejsze wyszukiwarki obiektów mają znaczenie
Telefony, samochody, domowe roboty i wyszukiwarki coraz częściej polegają na oprogramowaniu potrafiącym odnaleźć obiekty na zdjęciach: dziecko przechodzące przez ulicę, zgubione klucze na stole czy konkretny produkt na półce. Jednak większość współczesnych systemów rozumie jedynie krótkie, proste etykiety typu „pies” czy „samochód”. Gdy poprosisz o „małego psa z czerwonym obrożą leżącego za poduszką na sofie”, często się gubią. W artykule tym przedstawiono MQADet — sposób na ulepszenie istniejących systemów wyszukiwania obiektów tak, aby rozumiały bogate, szczegółowe opisy bez konieczności ponownego trenowania podstawowych modeli.
Od stałych list do otwartego rozumienia
Tradycyjne detektory obiektów są trenowane na stałych listach kategorii, na przykład 80 codziennych przedmiotów z popularnego zbioru COCO. Działają dobrze, o ile obiekt należy do jednej z tych kategorii, a żądanie jest krótkie i jasne. Rzeczywistość jest jednak bardziej złożona. Ludzie opisują przedmioty długimi frazami, subtelnymi cechami i relacjami, jak „mężczyzna w żółtej kamizelce stojący za ciężarówką”. Nowsze detektory „o otwartym słownictwie” próbują zerwać z ograniczeniem stałych list, łącząc obrazy z tekstem, ale wciąż mają problem z złożonym sformułowaniem i rzadkimi, „długimi ogonami” kategorii, które występują rzadko w danych treningowych. Poprawa tych systemów wymaga też dużych zasobów obliczeniowych i danych.
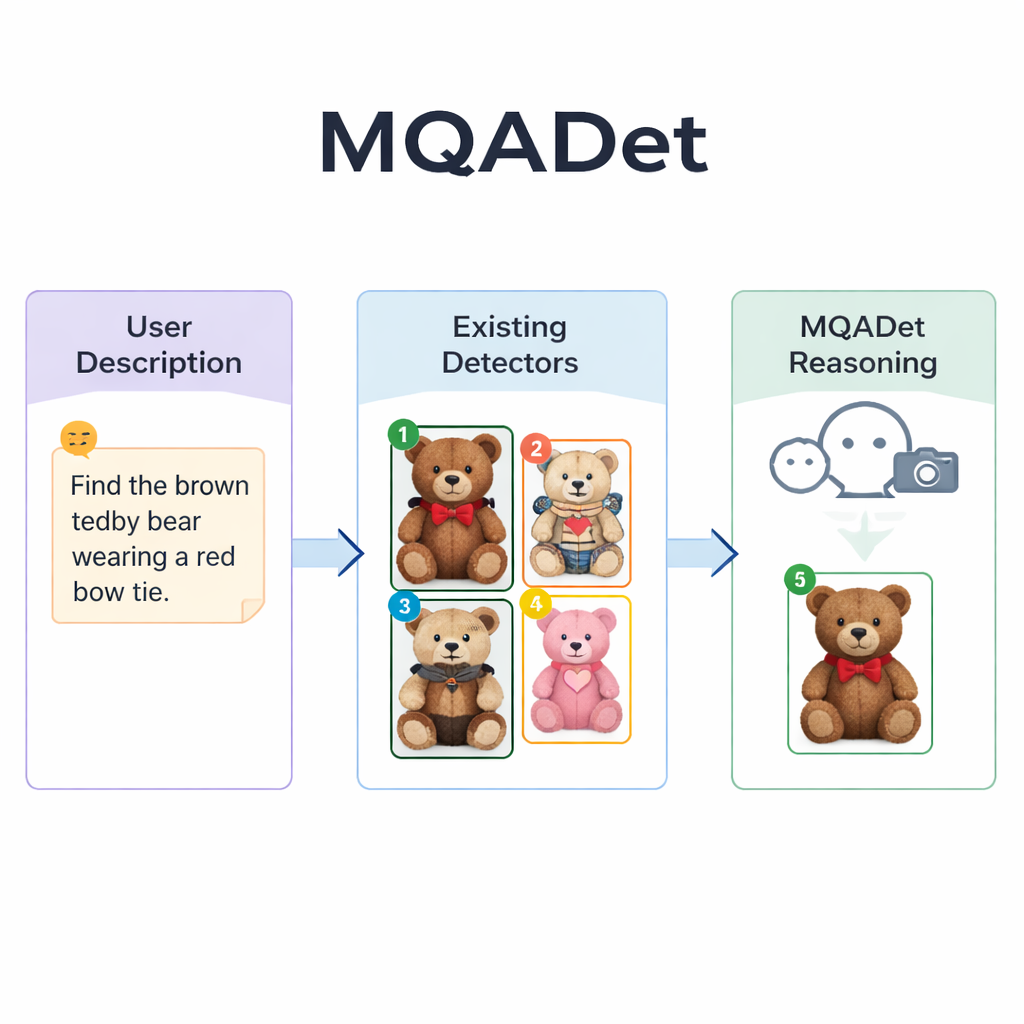
Pozwolenie modelom językowym kierować wyszukiwaniem
MQADet rozwiązuje te problemy, umieszczając multimodalny duży model językowy — system, który potrafi oglądać obrazy i czytać tekst — nad istniejącymi detektorami w trzyetapowym procesie pytanie‑odpowiedź. Najpierw etap zwany Ekstrakcją Podmiotów Świadomą Tekstu czyta całe zdanie użytkownika i wyodrębnia właściwe cele, takie jak „parasol” czy „pieszy” z długiego opisu. To przypomina to, jak człowiek mógłby najpierw szybko wskazać główne rzeczowniki w zdaniu, zanim przeskanuje scenę. Kluczowe jest to, że etap ten wykorzystuje mocne rozumienie języka naturalnego przez model, dzięki czemu radzi sobie z długimi, opisowymi frazami, a nie tylko pojedynczymi słowami.
Oznaczanie kandydatów na obiekty na obrazie
W drugim etapie, Sterowany Tekstem Wielomodalny Lokator Obiektów, MQADet przekazuje wyodrębnione podmioty oraz obraz istniejącemu detektorowi o otwartym słownictwie — na przykład Grounding DINO, YOLO‑World lub OmDet‑Turbo. Detektor proponuje kilka możliwych lokalizacji na obrazie, gdzie każdy podmiot może się znajdować, rysując prostokąt wokół każdego kandydata i umieszczając w nim prosty numer. Wynikiem jest „oznaczony obraz” pokazujący wszystkie prawdopodobne opcje. Co ważne, MQADet nie ponownie trenuje tych detektorów; używa ich w stanie niezmienionym. Sprawia to, że podejście jest typu plug‑and‑play: gdy pojawi się lepszy detektor, można go włączyć do potoku bez dodatkowych danych czy dostrajania.

Wnioskowanie prowadzące do najlepszego dopasowania
Trzeci etap, nazwany Sterowaniem Wyborem Optymalnego Obiektu przez MLLM, zamienia ostateczny wybór w pytanie wielokrotnego wyboru dla modelu językowego: biorąc pod uwagę oryginalny opis i oznaczony obraz z ponumerowanymi polami, który numer najlepiej odpowiada tekstowi? Ponieważ model widzi zarówno szczegółowe sformułowanie, jak i układ wizualny, może ocenić drobne wskazówki — wzory, kolory, relacje przestrzenne typu „po lewej” oraz wzajemne interakcje obiektów. Autorzy pokazują, że usunięcie tego etapu wnioskowania znacząco obniża dokładność, co podkreśla jego wagę. Dzięki temu trzyetapowemu projektowi MQADet poprawił dokładność na czterech wymagających benchmarkach z długimi, naturalnymi zdaniami, często zwiększając wydajność istniejących detektorów o 10–40 punktów procentowych bez zmiany ich wewnętrznych wag.
Co to oznacza dla codziennej technologii
Dla laika kluczowy przekaz jest taki, że nie trzeba już budować detektorów obiektów od zera, by uczynić je mądrzejszymi. MQADet działa jak inteligentny asystent nad obecnymi systemami, pomagając im interpretować bogate ludzkie opisy i wybierać właściwy obiekt w złożonych scenach. To może uczynić wyszukiwanie wizualne, narzędzia asystujące i maszyny autonomiczne bardziej niezawodnymi w obsłudze sposobu, w jaki ludzie naturalnie mówią — pełnego szczegółów, niuansów i kontekstu — torując drogę do bardziej intuicyjnej, sterowanej językiem interakcji ze światem wizualnym.
Cytowanie: Li, C., Zhao, X., Zhang, J. et al. MQADet: a plug-and-play paradigm for enhancing open-vocabulary object detection via multimodal question answering. Sci Rep 16, 6286 (2026). https://doi.org/10.1038/s41598-026-36936-x
Słowa kluczowe: detekcja obiektów o otwartym słownictwie, multimodalne duże modele językowe, wizualne odpowiadanie na pytania, widzenie komputerowe, rozumienie obrazów