Clear Sky Science · pl
Zastosowanie uczenia maszynowego w przewidywaniu wyników leczenia raka jelita grubego
Dlaczego przewidywanie wyników raka jelita grubego ma znaczenie
Rak jelita grubego jest jednym z najczęstszych nowotworów na świecie, a wielu pacjentów i ich bliskich chce znać prostą, pilną informację: „Jakie mam szanse i co można zrobić, by je poprawić?” Badanie przeprowadzone w Iranie analizuje, jak nowoczesne techniki komputerowe, znane jako uczenie maszynowe, mogą przesiać szczegółowe zapisy medyczne, aby lepiej przewidzieć, którzy pacjenci są bardziej narażeni po operacji. Dzięki ostrzejszym prognozom lekarze mogą precyzyjniej dopasować leczenie i opiekę pooperacyjną, dając pacjentom wrażliwym lepsze szanse na długoterminowe przeżycie.
Przekształcanie zapisów szpitalnych w użyteczne wzorce
Naukowcy wykorzystali dane z 10 lat obejmujące 764 osoby, które przeszły operację z powodu raka jelita grubego w dużym ośrodku w Shiraz w Iranie. Dla każdego pacjenta zebrano 44 informacje, w tym wiek, badania krwi, rozmiar guza, stadium choroby, objawy oraz szczegóły zabiegu i terapii, takich jak chemioterapia. Zbiory danych zostały uporządkowane i dokładnie sprawdzone: niemożliwe wartości laboratoryjne skorygowano, pacjentów, których nie dało się śledzić, usunięto, a brakujące odpowiedzi uzupełniono rozsądnymi oszacowaniami. Zespół podzielił dane tak, by większość służyła do uczenia modeli komputerowych, podczas gdy oddzielna część została zachowana do testowania, jak dobrze modele potrafią przewidzieć, kto żyje, a kto nie w czasie obserwacji.
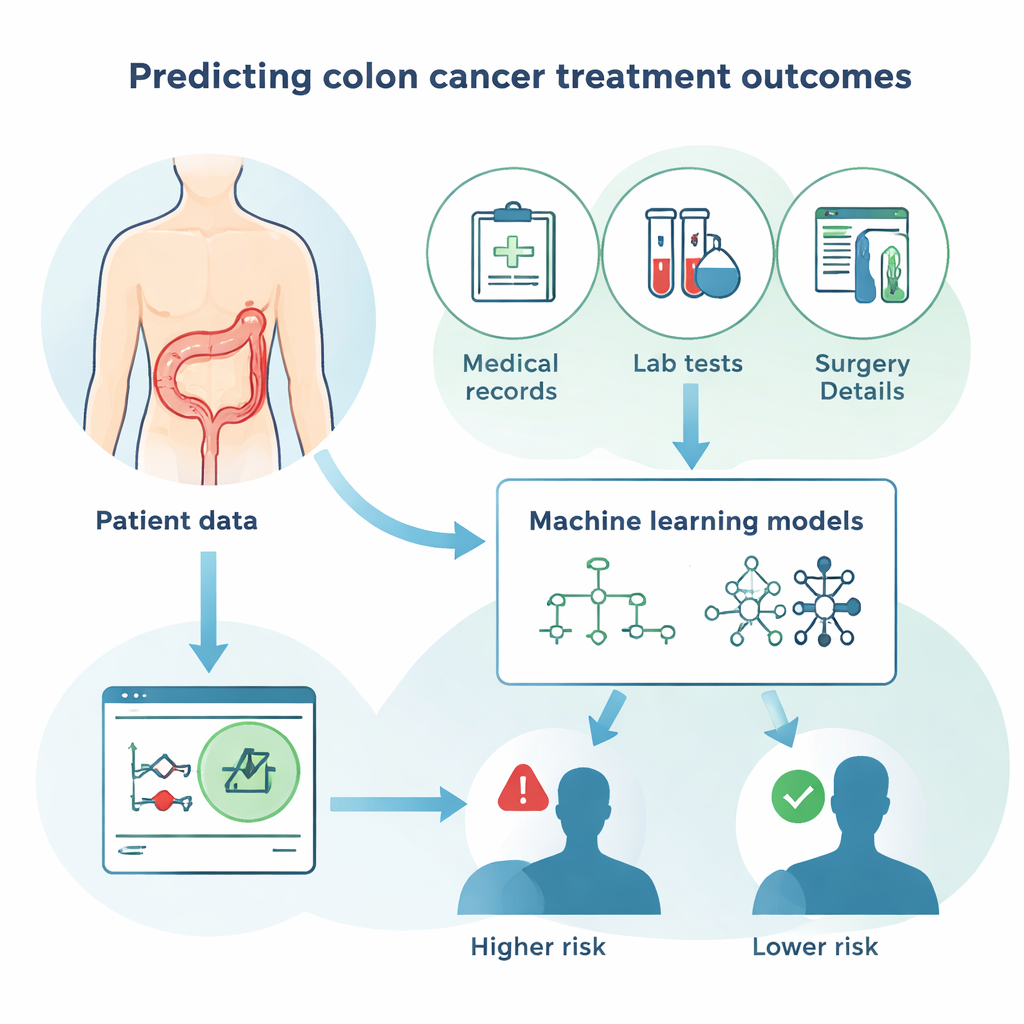
Jak inteligentne algorytmy uczą się od pacjentów
Zamiast polegać wyłącznie na tradycyjnej statystyce, badanie porównało kilka nowoczesnych podejść komputerowych obok siebie. Wśród nich znalazły się różne metody „lasów” i „boostingu”, które łączą wiele prostych reguł decyzyjnych, oraz sieci neuronowe, które luźno naśladują sposób łączenia się komórek mózgowych. Cel każdej metody był taki sam: wykorzystać informacje o pacjentach, by zgadnąć, czy dana osoba przeżyje, a następnie porównać te przewidywania z rzeczywistymi wynikami. Modele oceniano pod kątem ogólnej trafności, zdolności wychwytywania pacjentów, którzy zmarli, oraz unikania fałszywych alarmów dla tych, którzy przeżyli. Najlepiej działające metody osiągnęły około 80% ogólnej trafności, co jest mocnym wynikiem biorąc pod uwagę złożoność wyników w chorobie nowotworowej.
Które modele i czynniki miały największe znaczenie
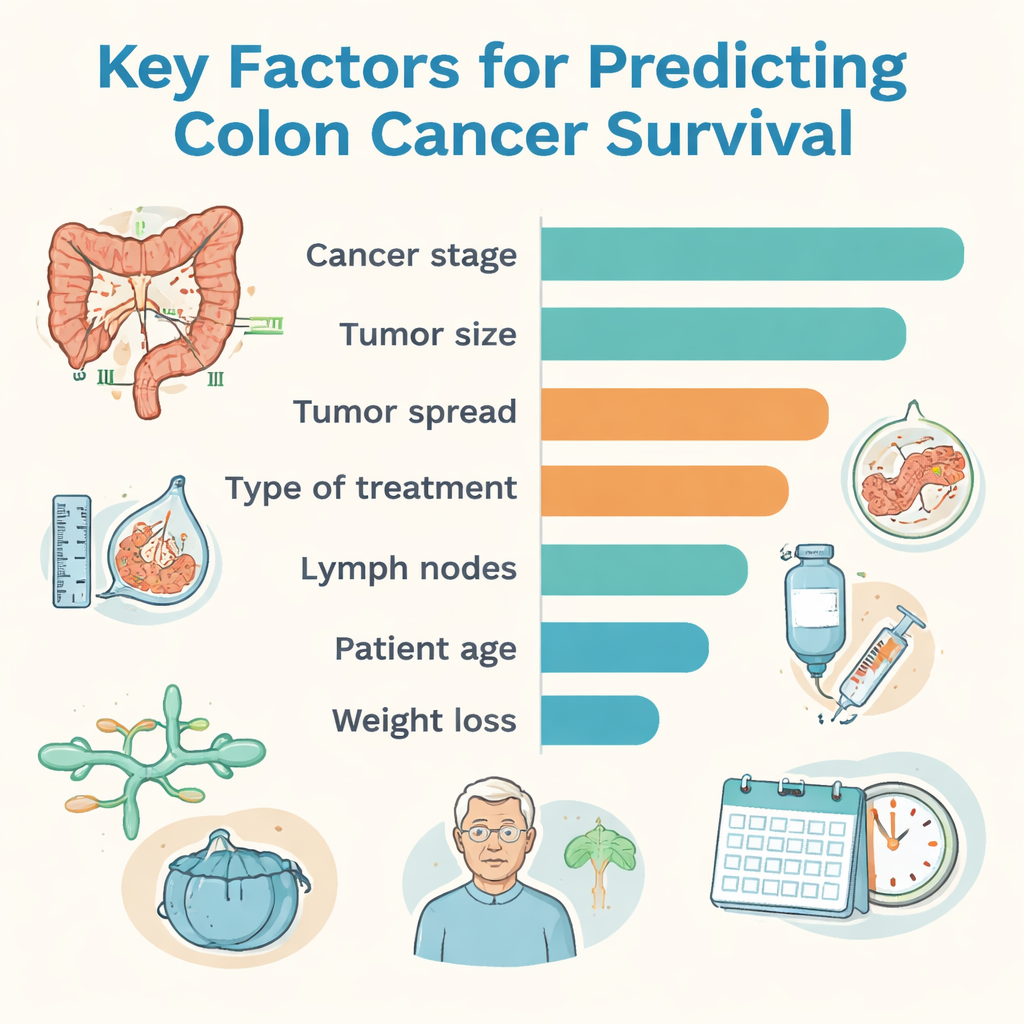
Wśród wszystkich podejść metoda o nazwie CatBoost osiągnęła najwyższą ogólną trafność, natomiast model lasu losowego (random forest) wykazał najlepszą równowagę między prawidłowym wykrywaniem pacjentów wysokiego ryzyka a unikaniem nadmiernego zgłaszania ryzyka u tych, którzy mieli dobre wyniki. Aby wyniki były bardziej zrozumiałe dla lekarzy, zespół zastosował narzędzie wyjaśniające, które porządkuje informacje według wpływu na decyzje komputera. Stadium nowotworu — podsumowanie wielkości guza, zajęcia węzłów chłonnych i ewentualnego rozsiewu — było najsilniejszym pojedynczym czynnikiem. Ważne role w prognozach przeżycia odegrały też: rozmiar guza, głębokość nacieku ściany jelita, obecność przerzutów do innych narządów, rodzaj leczenia, stopień złośliwości guza (jak bardzo komórki były nieprawidłowe), zajęcie naczyń chłonnych i krwionośnych, wiek pacjenta oraz utrata masy ciała.
Od liczb do decyzji przy łóżku pacjenta
Wyniki te sugerują, że starannie wytrenowany model komputerowy, zasilany rutynowymi informacjami klinicznymi, może pomóc lekarzom wychwycić pacjentów cicho znajdujących się w wysokim ryzyku po operacji raka jelita grubego. W codziennej praktyce takie narzędzie mogłoby działać w systemie elektronicznej dokumentacji medycznej, natychmiast łącząc szczegóły dotyczące guza i ogólnego stanu zdrowia pacjenta w prosty szacunek ryzyka. Liczba ta nie zastąpiłaby oceny lekarza, ale mogłaby kierować decyzjami, takimi jak częstotliwość kontroli, czy dodatkowe terapie są warte skutków ubocznych, lub kiedy warto zasięgnąć opinii drugiego specjalisty. Ponieważ najważniejsze czynniki wskazane przez komputer zgadzają się z tym, co specjaliści onkologiczni już uznają za krytyczne, system jest łatwiejszy do zaufania i wytłumaczenia pacjentom.
Co to oznacza dla pacjentów i przyszłości
Dla pacjentów i ich rodzin kluczowy przekaz jest taki, że komputery potrafią teraz wykorzystywać zwykłe dane medyczne, by wspierać bardziej spersonalizowaną opiekę w raku jelita grubego. Chociaż badanie przeprowadzono w jednym ośrodku w Iranie i wciąż wymaga przetestowania w innych szpitalach oraz z bogatszymi danymi, takimi jak informacje genetyczne i obrazowe, pokazuje, że uczenie maszynowe może wskazać, kto potrzebuje dodatkowej uwagi i dlaczego. Z czasem, gdy dodawane będą kolejne dane i modele będą udoskonalane, narzędzia te mogą pomóc lekarzom na całym świecie dostarczać leczenie oparte na dowodach, a jednocześnie precyzyjnie dopasowane do konkretnego nowotworu i sytuacji każdej osoby.
Cytowanie: Ghasemi, H., Hosseini, S.V., Rezaianzadeh, A. et al. Machine learning application in colon cancer treatment outcome prediction. Sci Rep 16, 6159 (2026). https://doi.org/10.1038/s41598-026-36917-0
Słowa kluczowe: rak jelita grubego, uczenie maszynowe, wyniki leczenia, prognozowanie ryzyka, dane kliniczne