Clear Sky Science · pl
Zmniejszanie luki w wydajności: systematyczna optymalizacja lokalnych modeli LLM do ekstrakcji PHI z japońskich dokumentów medycznych
Dlaczego to ma znaczenie dla prywatności pacjenta
Szpitale dysponują ogromnymi zasobami notatek medycznych, które mogłyby poprawić opiekę i badania, ale te zapisy zawierają wrażliwe informacje, takie jak imiona, adresy i daty. Potężne systemy AI działające w chmurze bardzo dobrze ukrywają takie dane, jednak wiele placówek nie ma zgody na wysyłanie surowych danych pacjentów na zewnętrzne serwery. Niniejsze badanie pokazuje, że przy starannej kalibracji mniejsze modele AI działające w całości w ramach szpitala mogą zaskakująco zbliżyć się do wydajności najlepszych systemów chmurowych — oferując sposób na użycie AI przy jednoczesnym utrzymaniu danych pacjentów na miejscu.
Dylemat: prywatność kontra postęp
Współczesne duże modele językowe potrafią niezawodnie odnajdywać i usuwać chronione informacje zdrowotne (PHI) z tekstów medycznych, często przekraczając 90-procentową dokładność. Jednak wysyłanie nieprzeredagowanych notatek pacjentów do usług w chmurze rodzi problemy prawne i etyczne wynikające z regulacji takich jak HIPAA, RODO czy japońska APPI. Wiele instytucji stawia warunek pełnej „suwerenności danych”, czyli że informacje nigdy nie opuszczają ich własnych systemów. Do tej pory lokalne modele uruchamiane na sprzęcie wewnętrznym zazwyczaj pomijały znacznie więcej identyfikatorów, zmuszając szpitale do wyboru: zaawansowana analiza w chmurze lub silniejsza prywatność przy słabszych narzędziach. Autorzy postawili sobie za cel sprawdzenie, czy tę lukę można zawęzić do poziomu użytecznego w praktyce klinicznej.
Etapowy plan działania dla mądrzejszej lokalnej AI
Zespół opracował pięcioetapowe ramy optymalizacyjne, aby stopniowo poprawiać wydajność lokalnych modeli językowych w usuwaniu PHI z japońskich raportów radiologicznych. Rozpoczęli od 14 różnych modeli o zróżnicowanych rozmiarach, wszystkie uruchomione na izolowanym, pozbawionym dostępu do internetu komputerze, mającym naśladować zabezpieczenia szpitalne. Korzystając z 160 starannie przygotowanych syntetycznych raportów — realistycznych, lecz całkowicie fikcyjnych — oceniali, jak dobrze każdy model wykrywa i wydziela osiem typów identyfikatorów, od imion i numerów identyfikacyjnych po daty i nazwy oddziałów. Po wstępnym teście bazowym stworzyli bardziej użyteczne ogólne prompt’y, następnie dostosowali instrukcje do specyfiki poszczególnych modeli, dodali zautomatyzowaną pętlę „samosprawdź i popraw”, a na końcu przetestowali najlepszych kandydatów na zarezerwowanym zestawie raportów. 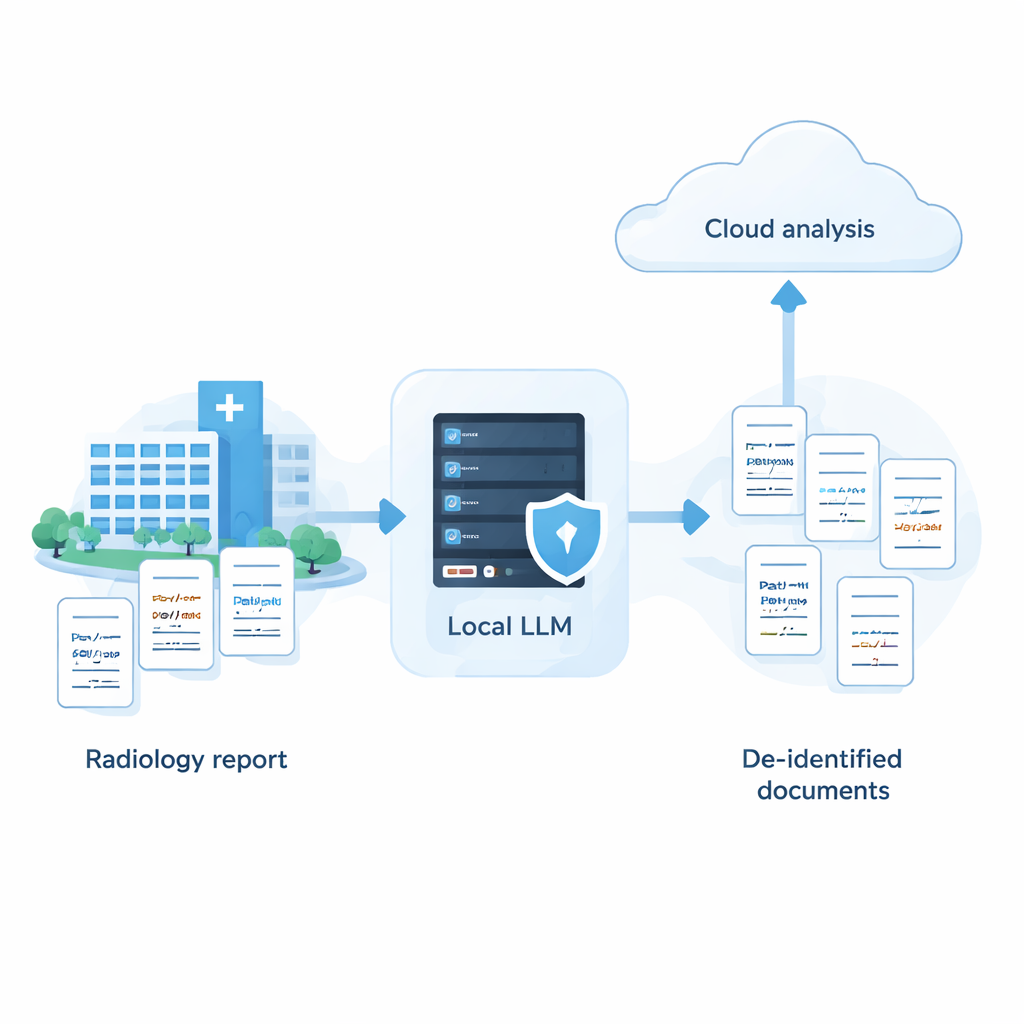
Zbliżanie się do wydajności chmury
W wyniku tego etapowego procesu badacze odkryli, że surowy rozmiar modelu nie był kluczowy; niektóre bardzo duże systemy nadal działały słabo. Zamiast tego najbardziej obiecujące okazały się modele, które dobrze reagowały na starannie zaprojektowane instrukcje i analizę błędów. Jeden model średniej wielkości, Mistral-Small-3.2, stał się wyraźnym zwycięzcą po zastosowaniu spersonalizowanych promptów i kroku samodoskonalenia, podczas którego model przeglądał i selektywnie korygował własne wyjścia. Na końcowych 60 przypadków testowych ta zoptymalizowana lokalna konfiguracja osiągnęła wynik 91,54 na 100 — około 97,8 procent wyniku wiodącego modelu chmurowego, który uzyskał 93,56 punktu — przy jednoczesnym idealnym przestrzeganiu reguł formatowania. W praktycznym ujęciu pozostała różnica została uznana za klinicznie nieistotną. Głównym kosztem była szybkość: przetwarzanie lokalne zajmowało około 25 sekund na typowy raport, w porównaniu z poniżej 2 sekund w chmurze, ale uznano to za akceptowalne do rutynowej, niealarmowej pracy wsadowej. 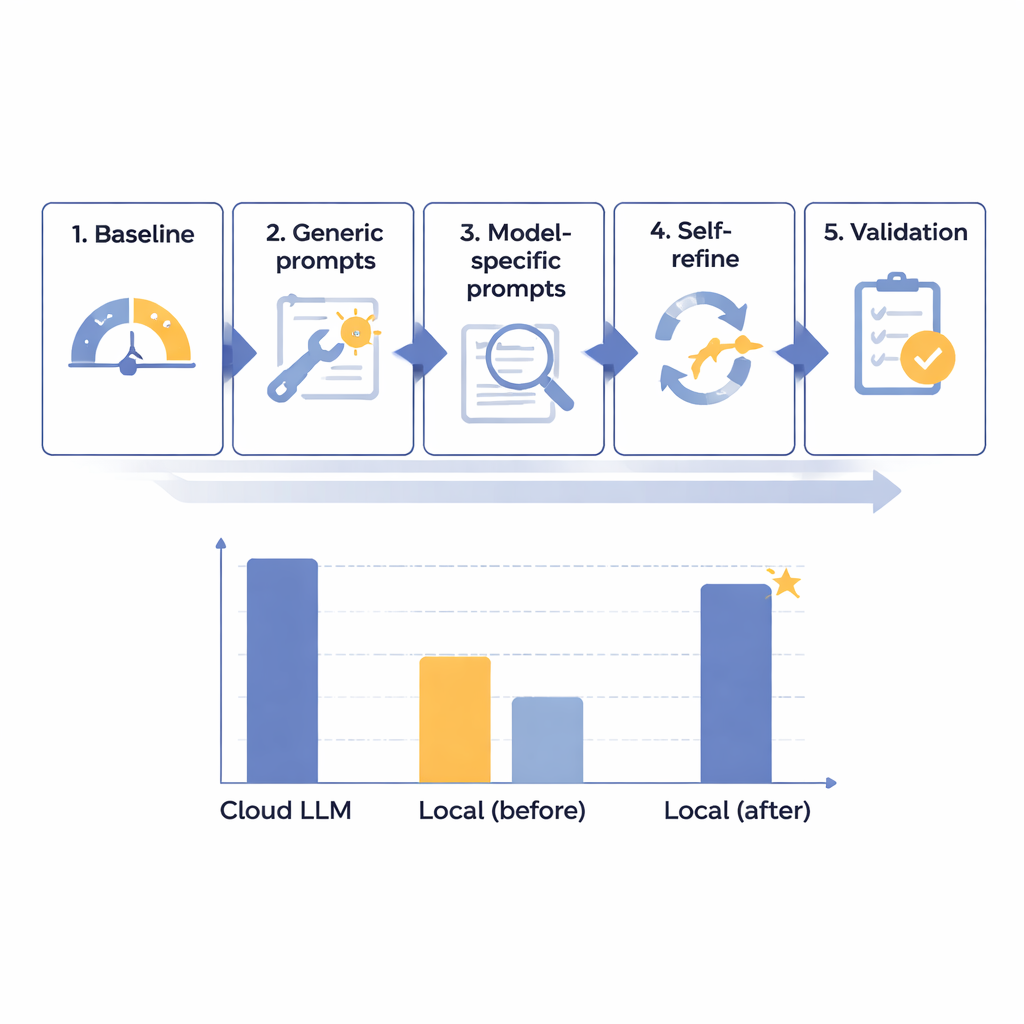
Zaskakujący próg przy samokorygowaniu
Jednym z najbardziej intrygujących ustaleń był rodzaj punktu krytycznego wokół 87–88 punktów na 100-punktowej skali autorów. Modele, które na etapie bazowym uzyskały wynik poniżej tego poziomu — jak Mistral-Small-3.2 — skorzystały znacząco na pętli samodoskonalenia, zyskując prawie siedem punktów dzięki naprawieniu niewielkiej części własnych błędów. Modele, które już zaczynały powyżej tego progu, wykazywały prawie żadną poprawę, a czasem traciły zasoby, próbując „naprawiać” poprawne odpowiedzi. Sugeruje to, że zaawansowane narzędzia optymalizacyjne warto stosować wobec modeli, które są dobre, ale jeszcze nie doskonałe, co pozwala szpitalom skoncentrować moc obliczeniową i czas personelu tam, gdzie przyniesie to największe korzyści. Autorzy zastrzegają, że ten próg oparty jest na zaledwie dwóch modelach i wymaga potwierdzenia, ale stanowi wczesną regułę praktyczną do planowania wdrożeń.
Co to oznacza dla szpitali i pacjentów
Badanie dowodzi, że szpitale nie muszą wybierać między silną prywatnością a zaawansowaną AI. Dzięki systematycznemu podejściu — przeglądowi wielu modeli, dostrajaniu promptów do ich mocnych i słabych stron oraz dodaniu inteligentnego kroku samorecenzji — możliwe jest, aby w pełni lokalny system zbliżył się dokładnością do najlepszych usług chmurowych w usuwaniu wrażliwych informacji z tekstu medycznego. W praktyce otwiera to drogę do strategii hybrydowej: PHI jest usuwane bezpiecznie na maszynach należących do szpitala, a tylko zanonimizowane raporty, z usuniętymi imionami i innymi identyfikatorami, wysyłane są do chmury w celu bardziej zaawansowanej analizy. Choć prace dotychczas opierały się na syntetycznych japońskich raportach radiologicznych i muszą być przetestowane na danych rzeczywistych oraz w innych językach, oferują wykonalną mapę drogową dla instytucji, które chcą wykorzystywać AI, zachowując jednocześnie zaufanie i prywatność pacjentów jako priorytet.
Cytowanie: Wada, A., Nishizawa, M., Yamamoto, A. et al. Bridging the performance gap: systematic optimization of local LLMs for Japanese medical PHI extraction. Sci Rep 16, 5910 (2026). https://doi.org/10.1038/s41598-026-36904-5
Słowa kluczowe: anulowanie identyfikowalności medycznej, prywatność pacjenta, lokalne modele językowe, Sztuczna inteligencja w opiece zdrowotnej, raporty radiologiczne