Clear Sky Science · pl
Wykrywanie obiektów na SoC brzegowych o niskich zasobach obliczeniowych: powtarzalny benchmark i wytyczne wdrożeniowe
Dlaczego małe układy w inteligentnych kamerach mają znaczenie
Wiele „inteligentnych” urządzeń wokół nas — kamer bezpieczeństwa, dronów, czujników przemysłowych i dzwonków do drzwi — musi rozpoznawać ludzi i obiekty w czasie rzeczywistym, lecz opiera się na bardzo małych, energooszczędnych układach zamiast na energochłonnej infrastrukturze centrum danych. Firmy często wybierają popularne modele wykrywania obiektów YOLO, jednak specyfikacje tych układów mówią niewiele o rzeczywistej wydajności w praktyce. Ten artykuł przeprowadza rygorystyczne, eksperymentalne badanie, jak dziewięć współczesnych wariantów YOLO zachowuje się na trzech powszechnie stosowanych, niskokosztowych procesorach Rockchip, ujawniając, co tak naprawdę decyduje o szybkości, zużyciu energii i niezawodności, gdy inteligencja przenosi się na krawędź sieci.
Trzy codzienne układy pod mikroskopem
Autorzy koncentrują się na trzech komercyjnych systemach na chipie (SoC), które dyskretnie zasila wiele systemów wizji wbudowanej: niewielkim RV1106, średnio klasycznym RK3568 oraz bardziej wydajnym RK3588. Każdy łączy standardowe rdzenie procesora z dedykowanym układem przetwarzania neuronowego (NPU) i pamięcią zewnętrzną. Na tych platformach zespół wdraża dziewięć modeli YOLO — trzy generacje (YOLOv5, YOLOv8, YOLO11) w trzech rozmiarach (Nano, Small, Medium) — wszystkie wytrenowane na tym samym zestawie testowym. Modele są starannie konwertowane do wspólnego formatu, kwantyzowane do arytmetyki 8-bitowej, kompilowane za pomocą narzędzi Rockchip i poddawane setkom testów czasowych, by uzyskać stabilne pomiary opóźnienia, poboru mocy i energii na przetworzoną klatkę.
Szybkość nie zawsze odpowiada karcie specyfikacji
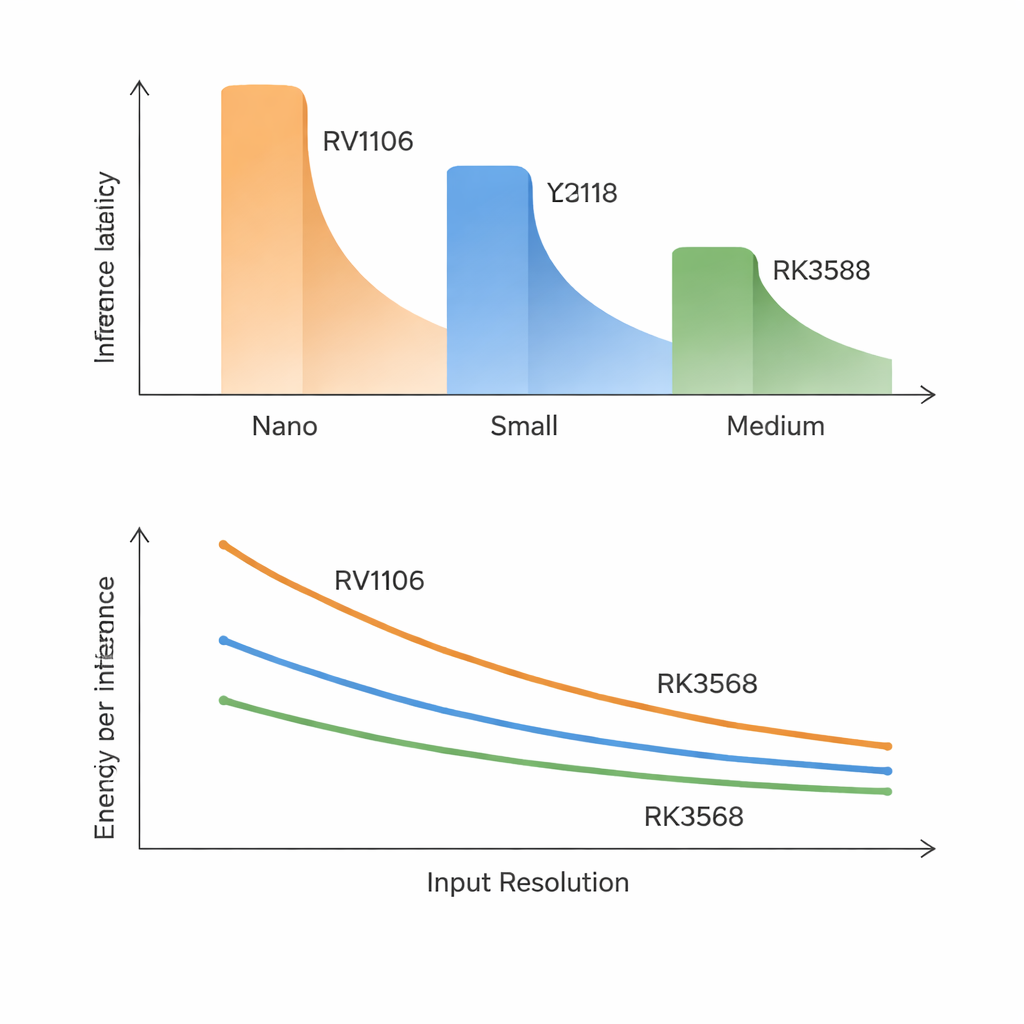
Jedną z najważniejszych lekcji jest to, że tradycyjne liczby w opisach modeli i układów słabo przewidują rzeczywistą prędkość. Na najwolniejszym układzie nawet najmniejsze modele potrzebują około 70–100 milisekund na klatkę, a modele średniej wielkości są zbyt wolne do użycia w czasie rzeczywistym. Najszybszy chip potrafi uruchomić modele Nano i wiele Small w pobliżu progu 30 klatek na sekundę, ale większe modele wciąż nie osiągają bardzo wysokich częstotliwości klatkowych. Co zaskakujące, opóźnienie koreluje bliżej z dokładnością modelu niż z liczbą operacji matematycznych czy liczby parametrów. Nowsze, dokładniejsze konstrukcje YOLO dodają wewnętrzne bloki sprzyjające poprawie dokładności, które jednak są nieporęczne dla wykonania na tych NPU, więc „mądrzejsze” często oznacza „znacząco wolniejsze” na tego typu sprzęcie.
Kiedy większe obrazy i współdzielona pamięć odgrywają się na nas
Badanie pokazuje, że zwiększanie rozmiaru wejściowych obrazów nie oznacza jedynie liniowego wzrostu pracy. Teoretycznie podwojenie szerokości i wysokości powinno zwiększyć koszty czterokrotnie, ale na układach o niskiej przepustowości pamięci wzrost może być jeszcze większy. Wraz ze wzrostem rozdzielczości dane pośrednie przestają swobodnie mieścić się w pamięci wewnętrznej i muszą być wielokrotnie przenoszone do pamięci zewnętrznej. Na najmniejszych i średniej klasy SoC robi się z tego korek: modele średniej wielkości zwalniają znacznie bardziej niż oczekiwano, a intensywne tło pamięciowe z innych zadań może zwiększyć opóźnienia o 50–270%. Dla kontrastu RK3588, z dużo większą przepustowością pamięci, radzi sobie ze wzrostem rozdzielczości elegancko i ledwie reaguje na dodatkowe obciążenie CPU czy pamięci, co podkreśla, że to prędkość pamięci — a nie surowa moc obliczeniowa — często jest prawdziwym wąskim gardłem.
Więcej rdzeni i większa moc nie gwarantują efektywności
Najszybszy chip Rockchip ma trzyrdzeniowe NPU, ale uruchamianie YOLO na wielu rdzeniach daje tylko skromne korzyści. Dla większości modeli rozdzielenie pracy na dwa lub trzy rdzenie skraca opóźnienie o mniej niż 10%, a czasem wydajność nawet się pogarsza. Narzut związany z koordynacją rdzeni i współdzieleniem tej samej puli pamięci niweluje dużą część teoretycznych zysków. Pomiary poboru mocy wprowadzają kolejny zwrot: wszystkie trzy SoC pobierają jedynie kilka watów podczas pracy, jednak ich energia na przetworzoną klatkę może różnić się trzykrotnie. Wyższej klasy RK3588 zużywa więcej mocy w danej chwili, ale kończy zadanie tak szybko, że często okazuje się najbardziej energooszczędnym wyborem, zwłaszcza dla modeli średniej wielkości i wyższych rozdzielczości.
Praktyczne wnioski dla urządzeń w świecie rzeczywistym
Dla osób rozważających inteligentne kamery, roboty czy urządzenia IoT przekaz jest prosty. Na najmniejszych układach praktyczne są jedynie najmniejsze modele YOLO przy umiarkowanych rozmiarach obrazów, i nawet wtedy osiągnięcie wideo w czasie rzeczywistym bywa trudne. Układy średniej klasy bez problemu obsłużą małe modele, a czasem także średnie, jeśli można pogodzić się z niższymi częstotliwościami klatek lub żywotnością baterii. Układ wysokiej klasy RK3588 wreszcie czyni realistycznym uruchamianie dokładniejszych, średniej wielkości wariantów YOLO przy nadal kontrolowanej energii na klatkę. W całym artykule autorzy zalecają, by projektanci wybierali modele z uwzględnieniem konkretnego sprzętu, zwracali szczególną uwagę na przepustowość pamięci i preferowali techniki oszczędzające pamięć zamiast gonienia za coraz większymi sieciami. Ostatecznie nie liczą się reklamowane teraoperacje na sekundę, lecz to, czy cały system potrafi dostarczyć szybkie, stabilne i energooszczędne wykrywanie obiektów w chaotycznych warunkach rzeczywistego świata.
Cytowanie: Kong, C., Li, F., Yan, X. et al. Object detection on low-compute edge SoCs: a reproducible benchmark and deployment guidelines. Sci Rep 16, 5875 (2026). https://doi.org/10.1038/s41598-026-36862-y
Słowa kluczowe: edge AI, wykrywanie obiektów, wizja wbudowana, modele YOLO, niskomocowy SoC