Clear Sky Science · pl
Estymacja wariancji oparta na uczeniu maszynowym przy próbkowaniu dwuetapowym z wykorzystaniem danych z sektora zdrowia i edukacji
Dlaczego mądrzejsze średnie mają znaczenie dla decyzji w świecie rzeczywistym
Kiedy lekarze badają ciśnienie krwi albo nauczyciele śledzą oceny uczniów, istotne jest nie tylko to, jaka jest średnia — trzeba też wiedzieć, jak bardzo osoby różnią się wokół tej średniej. To rozrzucenie, zwane zmiennością, decyduje o tym, ile pacjentów zrekrutować do badania, jak duży powinien być program korepetycji albo jak pewne mogą być decyzje polityczne. Artykuł streszczony tutaj wprowadza nowe, statystycznie uzasadnione podejście do mierzenia tej zmienności dokładniej, łącząc klasyczne pomysły z próbkowania z nowoczesnym uczeniem maszynowym, przetestowane na danych z sektora zdrowia i edukacji.
Pomiary rozrzutu przy niepełnej informacji
W idealnym świecie badacze znali by dodatkowe szczegóły o każdej osobie w populacji przed przeprowadzeniem sondażu: wiek, nawyki nauki, historię medyczną i więcej. W praktyce te informacje są często fragmentaryczne lub kosztowne do zebrania. Autorzy pracują w ramach projektu zwanego próbkowaniem dwuetapowym, aby sobie z tym poradzić. W pierwszej fazie biorą dużą, relatywnie tanią próbę i rejestrują proste informacje tła, takie jak wiek czy dostęp do internetu. W drugiej fazie losują mniejszą próbkę i mierzą bardziej kosztowny lub czasochłonny wynik, na przykład skurczowe ciśnienie krwi lub końcowe oceny z egzaminu. Wyzwanie polega na tym, by wykorzystać te dwie warstwy informacji do oszacowania, jak bardzo wynik rzeczywiście zmienia się w całej populacji.
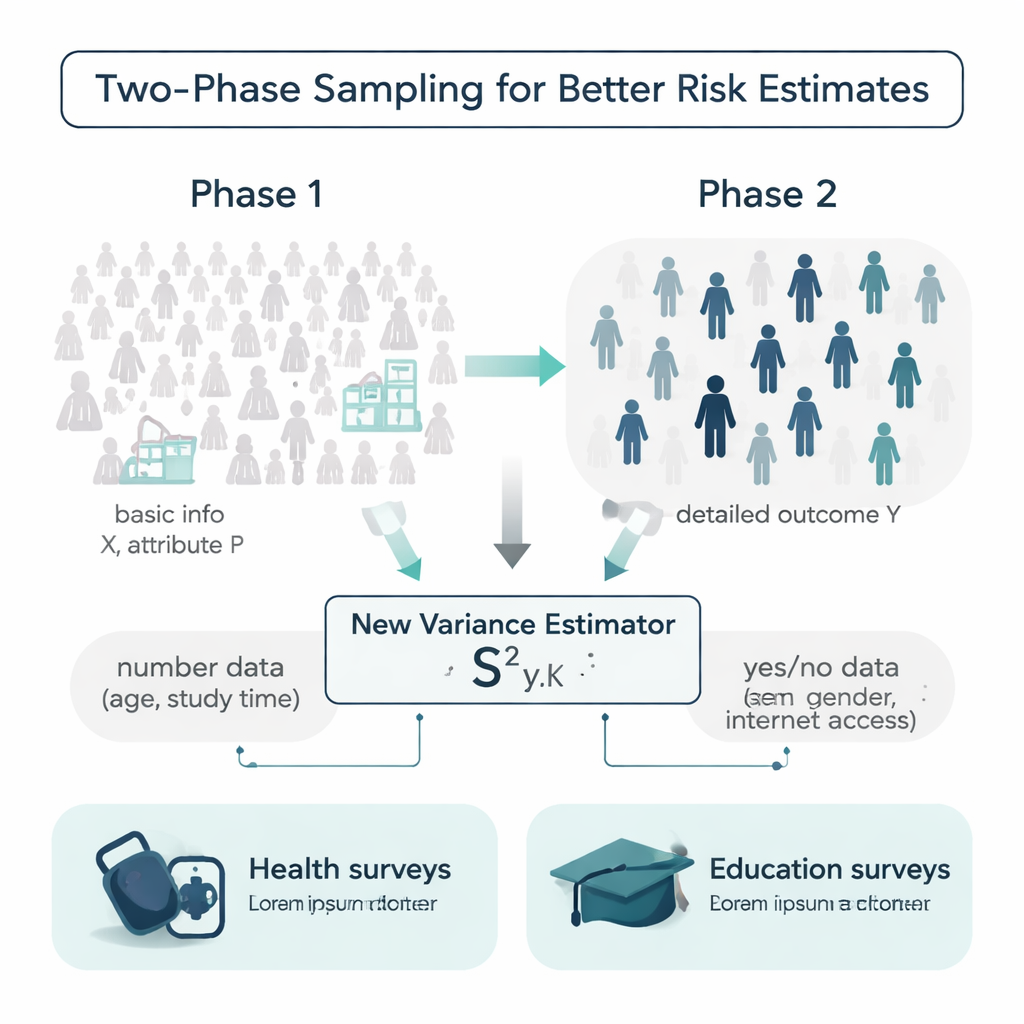
Nowy estymator wykorzystujący zarówno zmienne numeryczne, jak i cechy binarne
Większość tradycyjnych narzędzi do mierzenia zmienności opiera się tylko na samym wyniku lub na jednej zmiennej pomocniczej i często zakłada wygodne, dzwonowate rozkłady danych. Autorzy proponują nowy estymator wariancji, który jednocześnie wykorzystuje dwa rodzaje dodatkowych informacji: zmienną numeryczną (na przykład wiek lub tygodniowy czas nauki) oraz cechę binarną (taką jak płeć czy dostęp do internetu). Pokazują matematycznie, jak zachowuje się ten złożony „mieszany” estymator, wyprowadzając wzory na jego uprzedzenie i średni błąd kwadratowy — dwa kluczowe miary dokładności. Przy rozsądnych założeniach estymator jest praktycznie nieobciążony, a jego oczekiwany błąd jest mniejszy niż w przypadku szeroko stosowanych konkurencyjnych formuł, co oznacza, że z tej samej ilości danych powinien dostarczyć ostrzejszych oszacowań niepewności.
Testy wydajności w wielu scenariuszach danych
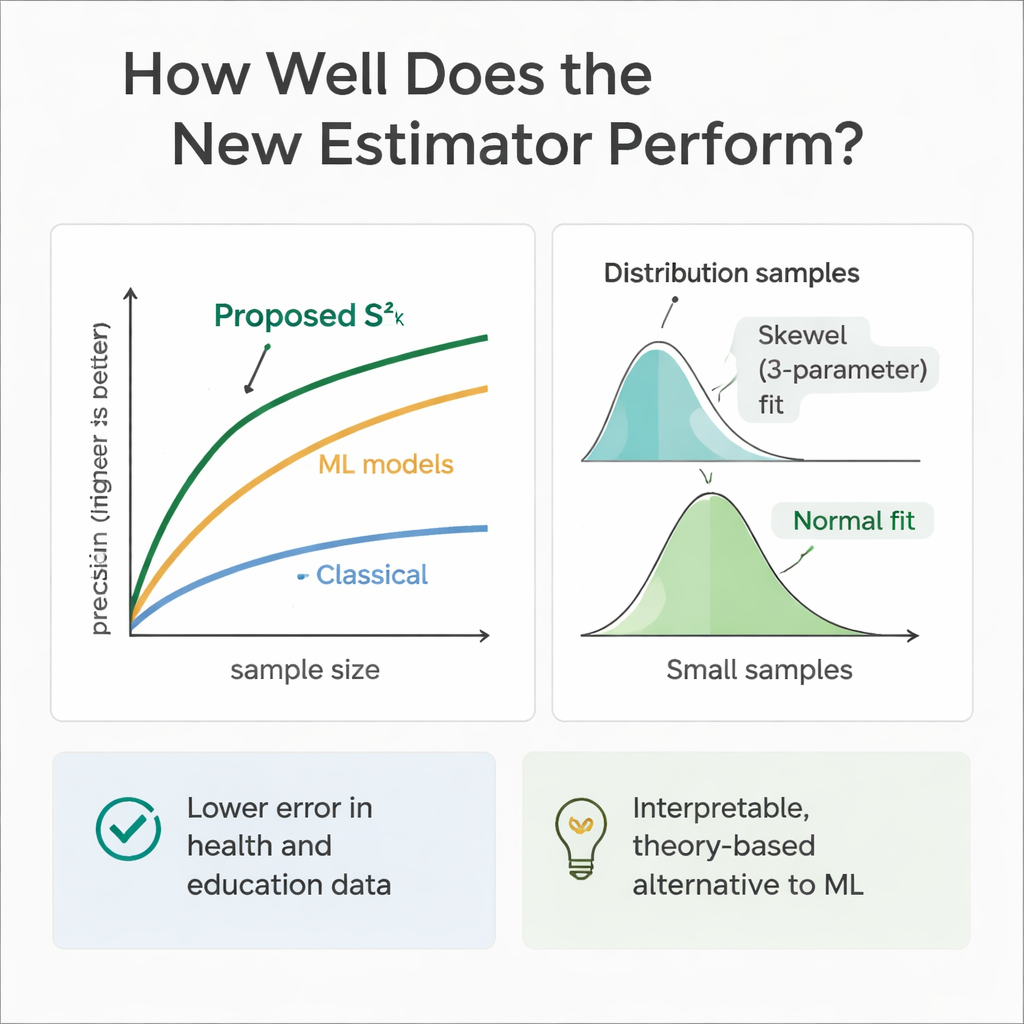
Aby sprawdzić, czy teoria zgadza się z praktyką, zespół przeprowadził obszerne eksperymenty komputerowe. Symulowali populacje, w których zmienne pomocnicze i wynik miały różne rozkłady — od symetrycznych (normalny i jednostajny) po skośne (gamma i Weibulla). Przy powtarzanym próbkowaniu porównywali błąd nowego estymatora z kilkoma ustalonymi metodami dla różnych rozmiarów prób. W niemal każdej konfiguracji, a zwłaszcza wraz ze wzrostem wielkości próby, nowe podejście wykazywało znacznie wyższą względną efektywność — często zmniejszając błąd o 30–70 procent w porównaniu z klasycznym estymatorem wariancji. Autorzy zbadali też, jak rozkłada się sam estymator przy próbkowaniu, odkrywając, że dla umiarkowanych prób najlepiej opisuje go elastyczna krzywa Weibulla z trzema parametrami, podczas gdy wraz ze wzrostem wielkości próby dąży on do kształtu normalnego.
Rzeczywiste dane z klinik i klas
Metodę zastosowano następnie w dwóch rzeczywistych studiach przypadków. W zestawie danych zdrowotnych wynikiem było skurczowe ciśnienie krwi, zmienną numeryczną był wiek, a cechą binarną — płeć. W zestawie edukacyjnym wynikiem była końcowa ocena z kursu, zmienną pomocniczą — tygodniowy czas nauki, a cechą binarną — posiadanie dostępu do internetu. W obu przypadkach proponowany estymator osiągnął najmniejszy średni błąd kwadratowy spośród wszystkich testowanych konkurentów statystycznych, istotnie zawężając oszacowaną zmienność wokół średniego ciśnienia krwi i średnich wyników studentów. Ta poprawa przekłada się na dokładniejsze przedziały ufności i bardziej wiarygodne porównania między grupami lub interwencjami.
Jak to wypada na tle uczenia maszynowego
Ponieważ modele uczenia maszynowego świetnie sprawdzają się w predykcji, autorzy trenowali też drzewa regresyjne, lasy losowe i regresję wektorów nośnych w tych samych symulowanych scenariuszach zdrowotnych i edukacyjnych. Modele te, zasilone tymi samymi zmiennymi pomocniczymi, często dorównywały lub nieco przewyższały nowy estymator pod względem czystej dokładności predykcyjnej. Jednak działają one jak czarne skrzynki: trudno dokładnie prześledzić, jak łączą informacje, i brakuje im przejrzystych wzorów potrzebnych do tradycyjnej inferencji sondażowej. Proponowany estymator jest natomiast przejrzysty i osadzony w teorii próbkowania, co ułatwia jego uzasadnienie w regulacyjnych, klinicznych czy politycznych zastosowaniach, gdzie wyjaśnialność jest równie ważna jak surowa wydajność.
Co to oznacza dla praktyki badań sondażowych
Mówiąc prosto, praca ta pokazuje, że badacze mogą uzyskać bardziej wiarygodne miary rozrzutu bez dramatycznego zwiększania wielkości prób, po prostu dyscyplinowanie wykorzystując nawet minimalne dodatkowe informacje, które już zbierają. Łącząc czynnik numeryczny (jak wiek lub czas nauki) z prostą cechą binarną (jak płeć czy dostęp do internetu) w dwuetapowym planie próbkowania, nowy estymator daje ostrzejsze, bardziej stabilne oszacowania wariancji niż długo stosowane metody. Choć zaawansowane narzędzia uczenia maszynowego pozostają przydatnym punktem odniesienia, podejście to oferuje praktyczny i interpretowalny kompromis, pomagając analitykom z obszarów zdrowia i edukacji wyciągać silniejsze wnioski z ograniczonych danych.
Cytowanie: Al-Marzouki, S., Nafisah, I.A., Dalam, M.E.E. et al. Machine learning based variance estimation under two phase sampling using health and education sector data. Sci Rep 16, 7760 (2026). https://doi.org/10.1038/s41598-026-36844-0
Słowa kluczowe: próbkowanie sondażowe, estymacja wariancji, uczenie maszynowe, dane zdrowotne, badania edukacyjne