Clear Sky Science · pl
Uogólnialność i przenoszalność modeli uczenia maszynowego wykorzystujących hiperspektralne dane odbicia dla cech kukurydzy
Dlaczego skanowanie liści roślin ma znaczenie dla naszej przyszłej żywności
Karmienie rosnącej populacji w warunkach zmieniającego się klimatu wymaga upraw, które poradzą sobie z upałem, suszą i innymi stresami. Hodowcy chcą wiedzieć, które rośliny mają właściwe połączenie struktury liścia, składu chemicznego i wydajności fotosyntetycznej — ale bezpośrednie mierzenie tych cech dla tysięcy roślin jest powolne i destrukcyjne. Badanie to analizuje, czy proste skanowanie liści kukurydzy za pomocą sensora hiperspektralnego i zastosowanie metod uczenia maszynowego może wiarygodnie zastąpić czasochłonne pomiary laboratoryjne, nawet gdy rośliny rosną w różnych latach i w zmieniających się warunkach polowych.
Świetlne odciski liści kukurydzy
Każdy liść odbija światło w wzorze zależnym od barwników, zawartości wody i wewnętrznej struktury. Sensory hiperspektralne rejestrują ten wzór w setkach długości fali od światła widzialnego po krótkofalową podczerwień, tworząc szczegółowy „odcisk palca” każdego liścia. Naukowcy zebrali takie odciski z różnorodnej populacji kukurydzy uprawianej przez trzy kolejne sezony polowe, wraz z 25 cechami opisującymi anatomię liścia (na przykład powierzchnię właściwą liścia i równowagę węgiel–azot), wymianę gazową (jak liście pobierają CO2 i tracą wodę) oraz fluorescencję chlorofilową (okno na wydajność i regulację fotosyntezy). Ten bogaty zbiór danych pozwolił im sprawdzić, jak dobrze różne modele statystyczne potrafią przekształcić spektra świetlne w oszacowania cech.
Nauczanie maszyn czytania liści
Zespół skoncentrował się na dwóch powszechnie stosowanych, stosunkowo prostych podejściach uczenia maszynowego: regresji metodą najmniejszych kwadratów częściowych (PLSR) oraz liniowej wektorowej regresji wspierającej (SVR). Obie metody kompresują wysoce szczegółowe spektra do mniejszego zestawu informacyjnych cech, zanim powiążą je z mierzonymi cechami. Naukowcy starannie porównali sposoby strojenia modeli, w szczególności, ile składowych powinien używać PLSR i jak unikać nadmiernego dopasowania. Badali też, czy lepiej jest podawać modelom indywidualne pomiary liści, średnie z pojedynczej działki, czy średnie ze wszystkich roślin tego samego genotypu. Do oceny wydajności i niepewności zastosowano rygorystyczne, zagnieżdżone podejście walidacji krzyżowej — w praktyce powtarzane cykle trenowania i testowania.
Jakie cechy są najłatwiejsze do przewidzenia
Niektóre cechy liści okazały się znacznie bardziej „czytelne” ze spektrów świetlnych niż inne. Cechy strukturalne i biochemiczne, takie jak powierzchnia właściwa liścia i zawartość azotu, były przewidywane z wysoką dokładnością, zwłaszcza gdy dane uśredniono na poziomie genotypu, co redukowało szum pomiarowy. Pewne cechy związane z potencjałem fotosyntetycznym oraz niektóre wskaźniki fluorescencji chlorofilowej opisujące zachowanie fotoukładu II pod światłem również wykazywały umiarkowaną przewidywalność. Natomiast cechy związane z szybkimi, krótkotrwałymi procesami — jak tempo uruchamiania lub zaniku ochronnego rozpraszania energii — były słabo uchwytne. W tych przypadkach sygnał spektralny jest albo słaby, albo łatwo przytłaczany przez zmienność środowiskową w momencie pomiaru.
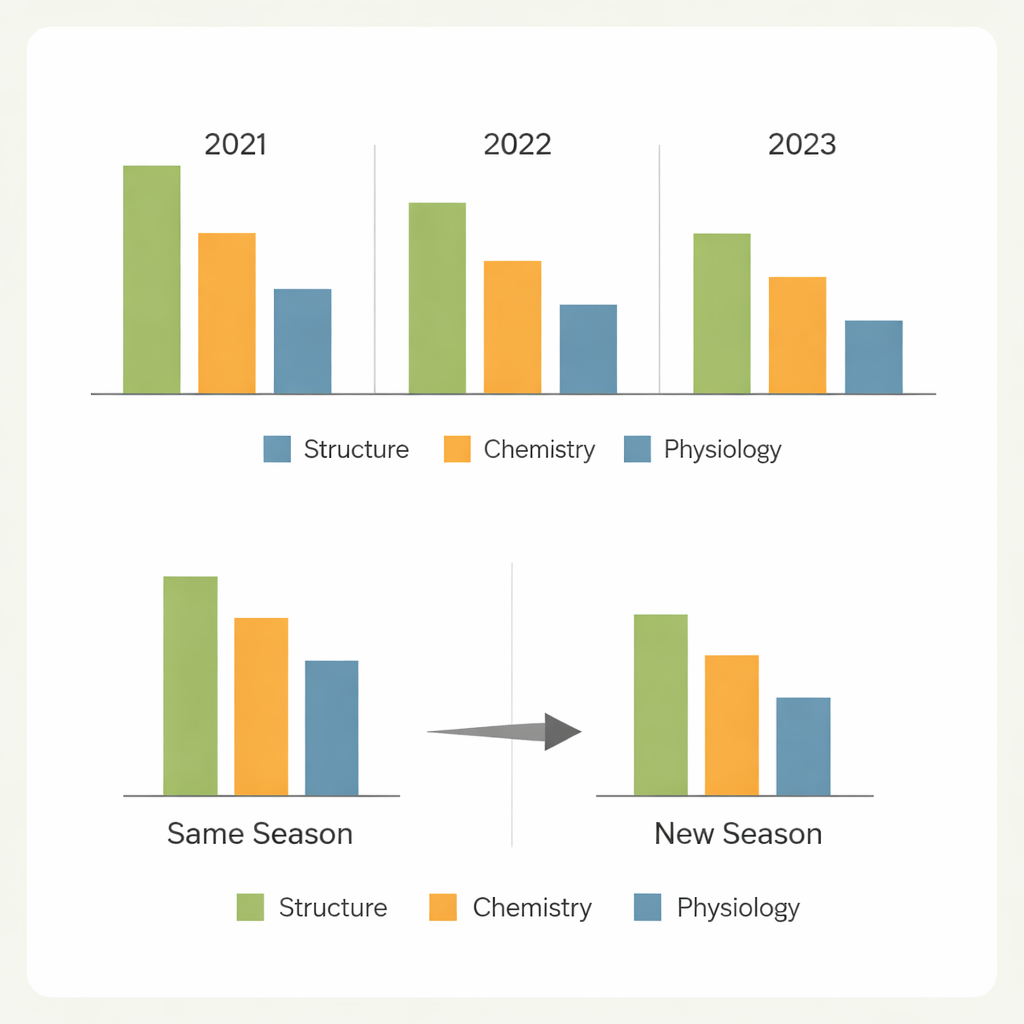
Z sezonu na sezon
Kluczowe pytanie dla praktycznej hodowli brzmi, czy model wytrenowany w jednym zestawie warunków może być zaufany w innym. Gdy modele przewidywały losowe rośliny w tym samym sezonie, wydajność była na ogół silna dla łatwiejszych cech. Przewidywanie całkowicie nowych genotypów uprawianych w tym samym sezonie powodowało tylko umiarkowane spadki dla cech strukturalnych i związanych z azotem, ale znacznie ostrzejsze spadki dla cech wymiany gazowej. Najbardziej surowy test — przewidywanie nowych genotypów w innym roku — ujawnił duże straty dokładności, szczególnie dla cech silnie kształtowanych przez środowisko. Różnice w pogodzie, warunkach pola i składzie genotypów przesunęły wzorce spektralne wystarczająco, by ograniczyć przenoszalność, przy czym jeden sezon wyróżniał się jako szczególnie trudny do przewidzenia na podstawie pozostałych.
Co to oznacza dla hodowli i teledetekcji
Dla hodowców i naukowców pracujących z uprawami badanie niesie zarówno zachętę, jak i ostrzeżenie. Skanowanie hiperspektralne w połączeniu ze stosunkowo prostymi metodami uczenia maszynowego jest już potężnym narzędziem do szybkiego oszacowania stabilnych, integratywnych cech, takich jak struktura liścia i status azotowy, i może uogólniać się między genotypami i latami w rozsądnym zakresie dla tych celów. Jednak to samo podejście jest znacznie mniej wiarygodne dla szybkich, wrażliwych na środowisko cech fizjologicznych, gdy modele stosuje się poza warunkami, na których je trenowano. Autorzy konkludują, że metody hiperspektralne są gotowe wspierać szeroko zakrojone przesiewy niektórych kluczowych cech kukurydzy, lecz przewidywanie dynamicznego zachowania fizjologicznego w różnych środowiskach będzie wymagać bogatszych danych treningowych, bardziej zaawansowanego modelowania i być może dodatkowych rodzajów pomiarów.
Cytowanie: Xu, R., Ferguson, J., Breil-Aubert, M. et al. Generalizability and transferability of machine learning models using hyperspectral reflectance data for maize traits. Sci Rep 16, 5865 (2026). https://doi.org/10.1038/s41598-026-36819-1
Słowa kluczowe: hiperspektralne odbicie, kukurydza, uczenie maszynowe, fenotypowanie roślin, fotosynteza