Clear Sky Science · pl
Modelowanie taksonomiczne i klasyfikacja w raportowaniu awarii sprzętu kosmicznego
Odnajdywanie wzorców w zakłóceniach lotów kosmicznych
Każda misja kosmiczna polega na prawidłowym działaniu niezliczonych elementów sprzętu — od śrub i kabli po systemy podtrzymywania życia. Gdy coś idzie nie tak, inżynierowie sporządzają szczegółowe raporty o niezgodnościach, ale NASA ma ich teraz ponad 54 000 — zdecydowanie za wiele, by czytać je pojedynczo. Badanie to pokazuje, jak nowoczesne narzędzia językowe i uczenia maszynowego potrafią przekształcić tę górę tekstu w uporządkowaną wiedzę, pomagając inżynierom dostrzegać wzorce awarii, poprawiać konstrukcje i zwiększać bezpieczeństwo załóg.
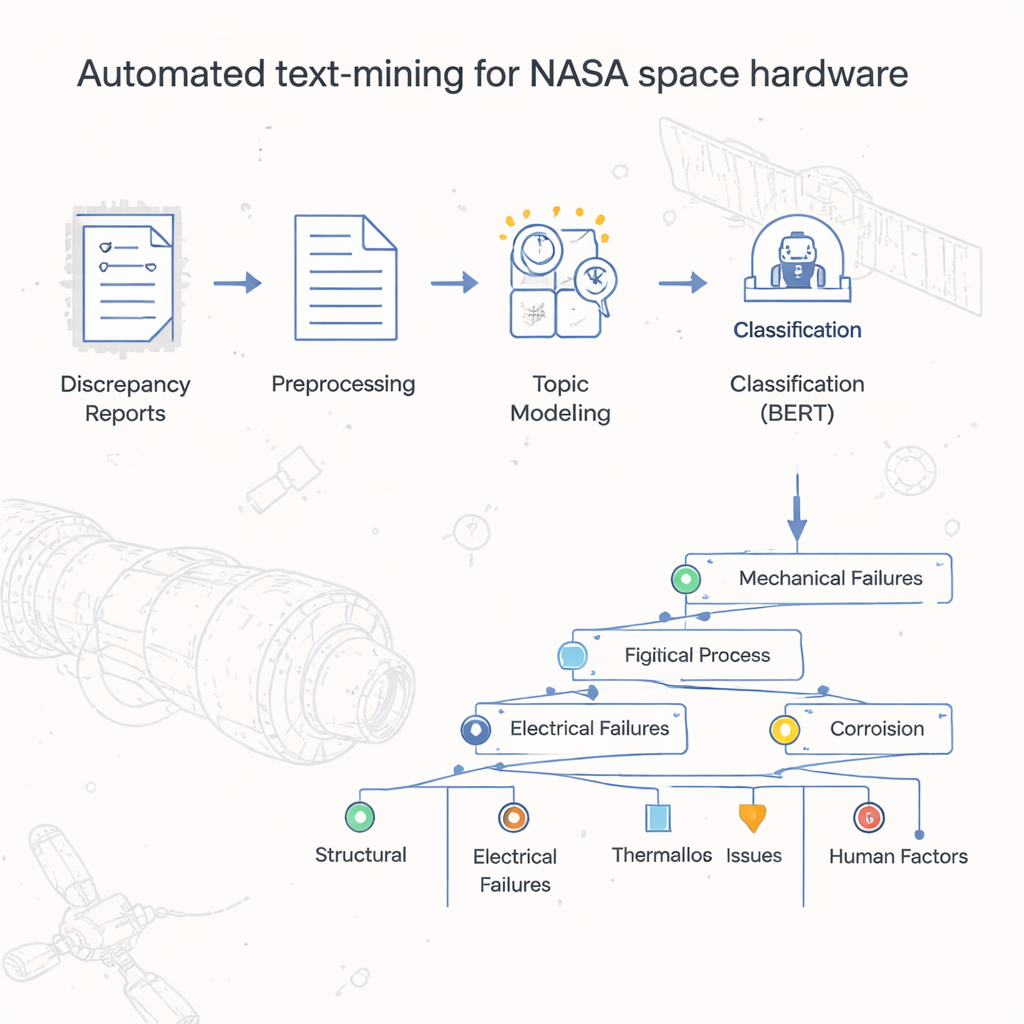
Z hałd raportów do uporządkowanej wiedzy
Przez dziesięciolecia Johnson Space Center NASA przechowywał raporty o awariach sprzętu i niezgodnościach jako dokumenty cyfrowe, często przypominające zdigitalizowane formularze papierowe. Podstawowe zestawienia w arkuszach pokazywały, które oficjalne kody defektów występowały najczęściej, ale prawdziwa historia — konkretne przyczyny, czynności i warunki prowadzące do problemów — była ukryta w polach tekstu swobodnego. Ręczne czytanie i kategoryzowanie ponad 54 000 zapisów byłoby czasowo nieopłacalne. Autorzy postawili sobie za cel zbudowanie zautomatyzowanego sposobu klasyfikacji i grupowania tych raportów, tworząc rodzaj „mapy” lub taksonomii, która odzwierciedla, jak sprzęt kosmiczny faktycznie zawodzi w codziennej praktyce.
Nauczanie komputerów czytania języka inżynieryjnego
Zespół najpierw oczyścił tekst w każdym raporcie, aby komputery mogły efektywnie z nim pracować. Usunęli zbędne symbole i cyfry dodające szum, podzielili zdania na pojedyncze słowa i sprowadzili je do prostszej, podstawowej formy (na przykład zamieniając „leaked” i „leaking” na „leak”). Wyfiltrowano też powszechne słowa niosące niewiele znaczenia, jak „the” czy „and”. Po ustandaryzowaniu tekstu badacze przekształcili go w liczby, z którymi radzą sobie algorytmy uczenia maszynowego, używając ustalonych technik odzwierciedlających częstość występowania słów i ich siłę charakterystyki dokumentu. Ten warsztat przygotowawczy pozwolił zastosować potężne narzędzia pierwotnie opracowane do ogólnych zadań językowych w wyspecjalizowanym świecie raportów o sprzęcie kosmicznym.
Budowanie drzewa typów awarii
W sercu projektu znajduje się dwustopniowy model nazwany przez autorów LDA-BERT. Pierwszy etap, Latent Dirichlet Allocation (LDA), automatycznie wykrywa tematy — zwane też topicami — szukając wzorców słów, które mają tendencję występować razem w tysiącach raportów. Pojedynczy raport może łączyć kilka tematów, co odzwierciedla rzeczywistość, gdzie jeden problem sprzętowy może mieć wiele współistniejących przyczyn. Drugi etap wykorzystuje BERT, nowoczesny model językowy, do weryfikacji i dopracowania, jak dobrze te tematy odseparowują raporty. Traktując tematy LDA jako tymczasowe etykiety i trenując BERT do ich przewidywania, badacze mogli zidentyfikować liczbę i kombinację tematów zapewniających stabilne, dokładne klasyfikacje. Następnie podzielili każdy temat na podtematy, używając klastrowania i kontroli statystycznych, by skonstruować rozgałęziającą się taksonomię organizującą raporty o awariach od szerokich kodów defektów po szczegółowe etykiety na poziomie procesów.
Przekształcanie taksonomii w użyteczne trendy
Gdy taksonomia była gotowa, zespół zwizualizował ją za pomocą pulpitów i interaktywnych narzędzi. Każde rozgałęzienie i podgałąź drzewa można było powiązać z innymi informacjami z raportów: kiedy problem został po raz pierwszy odnotowany, ile czasu zajęło jego zamknięcie, która organizacja była za niego odpowiedzialna i jaka decyzja końcowa zapadła. Wykresy czasowe pokazywały, czy pewne typy problemów — na przykład przeoczenia w inspekcjach lub problemy z danymi tolerancji — stają się w kolejnych latach bardziej lub mniej powszechne. Mapy słów dawały szybkie wyczucie języka używanego w każdej grupie bez konieczności czytania każdego raportu. Takie widoki pomagają menedżerom skoncentrować się na procesowych awariach o wysokim trendzie i dużym wpływie, kierując szkolenia, zmiany procedur lub aktualizacje projektowe tam, gdzie przyniosą największy efekt.
Ograniczenia automatycznego poszukiwania przyczyn źródłowych
Badacze sprawdzili też narzędzia próbujące pójść dalej niż etykietowanie i wykrywanie trendów, aby wywnioskować bezpośrednie związki przyczynowo-skutkowe z tekstu. Testowali systemy takie jak INDRA-Eidos oraz niestandardowe reguły zbudowane z użyciem biblioteki językowej spaCy. Chociaż narzędzia te potrafiły wydobyć niektóre pary przyczyna-skutek i zwizualizować je jako interaktywne sieci, wiele sugerowanych powiązań było zbyt ogólnych lub mylących, by były użyteczne. W praktyce modele miały trudności, ponieważ oryginalne raporty często nie formułowały jasno przyczyn źródłowych; inżynierowie sugerowali je lub odkładali do późniejszych dochodzeń. Badanie konkluduje, że wiarygodne zautomatyzowanie odkrywania przyczyn źródłowych wymagałoby zarówno bogatszego wprowadzania danych — np. jawnych pól na prawdopodobne przyczyny — jak i kosztowniejszego, silnie dopasowanego treningu modeli, co nie jest uzasadnione dla tej jednorazowej analizy.
Dlaczego ma to znaczenie dla przyszłych misji
Przekształcając duże, nieustrukturyzowane archiwum raportów o awariach w czytelną, warstwową taksonomię, praca ta daje NASA praktyczny sposób monitorowania, jak i dlaczego problemy sprzętowe pojawiają się w czasie. Chociaż metody te nie zastąpią jeszcze ludzkiego osądu w głębokiej analizie przyczyn źródłowych, doskonale nadają się do przeskanowania ogromnej ilości tekstu, aby wyeksponować miejsca koncentracji problemów i rodzaje procesów, które zwykle są zaangażowane. Taka wczesna sygnalizacja i uporządkowany wgląd mogą pomóc zespołom inżynieryjnym ukierunkować uwagę, udoskonalić procedury i projektować bardziej odporne systemy — konkretne kroki w stronę bezpieczniejszych, bardziej niezawodnych misji na Księżyc, Marsa i dalej.
Cytowanie: Palacios, D., Hill, T.R. Taxonomical modeling and classification in space hardware failure reporting. Sci Rep 16, 5868 (2026). https://doi.org/10.1038/s41598-026-36813-7
Słowa kluczowe: awarie sprzętu kosmicznego, przetwarzanie języka naturalnego, modelowanie tematów, analiza ryzyka inżynieryjnego, raporty niezgodności NASA