Clear Sky Science · pl
Weryfikacja autentyczności wiadomości w urdu przy użyciu głębokiego uczenia z połączonymi osadzeniami BERT i GloVe
Dlaczego wykrywanie fałszywych wiadomości w urdu ma znaczenie
W Pakistanie i na całym świecie coraz więcej osób otrzymuje wiadomości z witryn internetowych i mediów społecznościowych zamiast z gazet czy telewizji. Ta zmiana ułatwiła szybkie rozpowszechnianie nieprawdziwych informacji, szczególnie w językach narodowych takich jak urdu, gdzie dostępne są ograniczone narzędzia cyfrowe. W badaniu postawiono proste, ale pilne pytanie: czy nowoczesna sztuczna inteligencja potrafi automatycznie odróżnić prawdziwe wiadomości w urdu od fałszywych, pomagając zwykłym czytelnikom, dziennikarzom i platformom w obronie przed wprowadzającymi w błąd informacjami?
Rosnące wyzwanie dezinformacji online
Autorzy zaczynają od przedstawienia, jak sfabrykowane nagłówki i zniekształcone relacje mogą kształtować opinię publiczną, podsycać napięcia polityczne, a nawet szkodzić zdrowiu i finansom ludzi. Podczas gdy wiele serwisów fact-checkingowych i projektów badawczych koncentruje się na języku angielskim, języki regionalne, takie jak urdu, często zostają pominięte. Istniejące zasoby w urdu obejmują zaledwie kilka tysięcy artykułów, wiele przetłumaczonych z angielskiego i skupionych na wąskich tematach, na przykład polityce. Utrudnia to trenowanie niezawodnych systemów komputerowych do rozpoznawania podejrzanych treści w języku, który czyta większość Pakistańczyków.
Budowa obszernego zbioru wiadomości w urdu
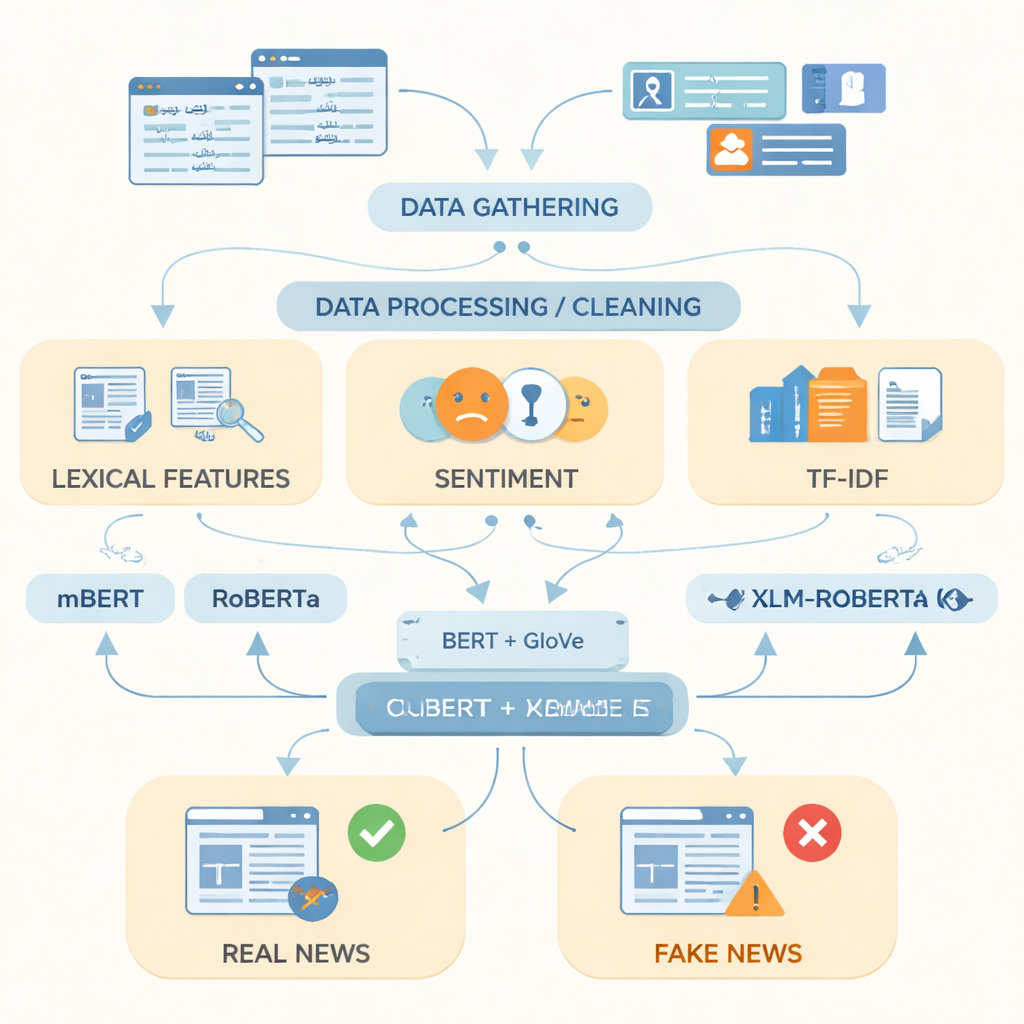
Aby zmniejszyć tę lukę, badacze zebrali to, co opisują jako najbardziej rozbudowany zbiór danych fałszywych wiadomości w urdu do tej pory, zawierający 14 178 artykułów opublikowanych w latach 2017–2023 z renomowanych pakistańskich serwisów informacyjnych i platform online. Materiały obejmują piętnaście obszarów życia codziennego, w tym politykę, zdrowie, edukację, biznes, przestępczość, sport i środowisko. Korzystając ze źródeł fact-checkingowych takich jak PolitiFact, FactCheck oraz wyspecjalizowanych API informacyjnych, każdy wpis został oznaczony jako prawdziwy lub fałszywy; artykuły częściowo prawdziwe pogrupowano razem z prawdziwymi, aby odzwierciedlić bardziej zniuansowane relacjonowanie. Zespół następnie oczyścił tekst, usuwając duplikaty, adresy internetowe i nadmiar interpunkcji, dzieląc zdania na słowa oraz eliminując bardzo częste słowa wypełniające.
Nauczanie komputerów, jak wygląda fałszywa wiadomość
Po przygotowaniu danych autorzy skoncentrowali się na tym, jak najlepiej reprezentować tekst w urdu dla komputera. Połączyli proste wskaźniki, takie jak często używane słowa, emocjonalny ton języka i miary częstości występowania terminów, z dwoma zaawansowanymi technikami reprezentacji słów. Jedna, zwana GloVe, traktuje każde słowo jako stały wektor liczbowy oparty na tym, jak często pojawia się razem z innymi słowami w całym zbiorze. Druga, oparta na modelach w stylu BERT, analizuje każde słowo w kontekście zdania i przypisuje mu znaczenie zależne od kontekstu. Łącząc te dwa sposobu postrzegania języka w jedną, bogatszą reprezentację, system może uchwycić zarówno ogólne wzorce, jak i subtelne zmiany w doborze słownictwa, które często odróżniają fałszywe relacje od prawdziwych.
Testowanie zaawansowanych modeli językowych
Następnie badacze wprowadzili te reprezentacje do trzech nowoczesnych modeli głębokiego uczenia, trenowanych na tekstach w wielu językach: mBERT, RoBERTa i XLM-RoBERTa. Wszystkie trzy zostały dopasowane (fine-tuned) do zbioru danych w urdu, aby przewidywać, czy dany artykuł jest prawdziwy czy fałszywy. Ich wydajność oceniano za pomocą standardowych miar: dokładności (jak często były poprawne), precyzji (jak często oznaczone jako fałszywe faktycznie były fałszywe), czułości/recal (ile ze wszystkich fałszywych artykułów wykryły) oraz miary F1, która równoważy precyzję i recall. Choć każdy model osiągnął dobre wyniki, najlepszy okazał się XLM-RoBERTa w połączeniu z połączoną reprezentacją BERT i GloVe, klasyfikując poprawnie około 96 procent artykułów testowych i osiągając wynik F1 równy 0,956 — lepiej niż wcześniejsze systemy do wykrywania fałszywych wiadomości w urdu, które korzystały z mniejszych zbiorów danych lub prostszych metod.
Co to oznacza dla codziennych czytelników
Dla osób niebędących specjalistami przekaz jest prosty: przy wystarczającej ilości wysokiej jakości danych w urdu i odpowiednim typie SI możliwe jest zbudowanie narzędzi, które automatycznie oznaczają prawdopodobnie fałszywe treści z wysoką niezawodnością. Badanie pokazuje, że bogatsze reprezentacje języka i modele wielojęzyczne znacznie poprawiają zdolność komputerów do rozumienia, jak urdu jest rzeczywiście zapisywane w różnych regionach i tematach. Chociaż obecna praca koncentruje się wyłącznie na tekście i nie analizuje jeszcze obrazów ani zachowań w mediach społecznościowych, tworzy solidne podstawy pod przyszłe systemy, które mogłyby działać wielojęzycznie i wielomedialnie. W praktyce badania te przybliżają Pakistan do wtyczek do przeglądarek, paneli redakcyjnych czy filtrów w mediach społecznościowych, które pomagają ludziom oddzielić fakty od fikcji w języku, którego używają na co dzień.
Cytowanie: Feroz, A., Abbasi, W., Babar, M.Z. et al. Verifying Urdu news authenticity using deep learning with concatenated BERT and GloVe embedding. Sci Rep 16, 7352 (2026). https://doi.org/10.1038/s41598-026-36771-0
Słowa kluczowe: wykrywanie fałszywych wiadomości, język urdu, głębokie uczenie, BERT i GloVe, dezinformacja w sieci