Clear Sky Science · pl
Ulepszanie długodystansowej estymacji głębi poprzez heterogeniczne kodowanie CNN-transformer i międzywymiarową fuzję semantyczną
Widzenie głębi jednym okiem
Współczesne roboty, samochody autonomiczne i drony często polegają na drogich czujnikach 3D, by określić odległość obiektów. W tym badaniu pokazano, jak zwykłe kamery kolorowe, takie jak w smartfonach, można znacznie bardziej wykorzystać: autorzy proponują nowy sposób, w jaki komputer może wywnioskować głębię z jednego zdjęcia, koncentrując się na najtrudniejszej części sceny — dużych odległościach, gdzie przeszkody są małe, rozmyte i łatwe do błędnej oceny.
Dlaczego odległe obiekty są trudne do oceny
Estymacja głębi z pojedynczego obrazu, zwana monocularną estymacją głębi, to pewnego rodzaju wizualna sztuczka. Obiekty bliskie zajmują wiele pikseli i mają ostre tekstury, więc dzisiejsze sieci neuronowe radzą sobie dobrze na krótkich i średnich dystansach. Jednak im dalej, tym samochody kurczą się do kilku pikseli, a oznaczenia na drodze zanikają w mgle. Standardowe konwolucyjne sieci neuronowe dobrze wykrywają lokalne detale, lecz mają problem z uchwyceniem całościowego kontekstu ulicy. Nowsze modele typu Transformer dobrze widzą globalny kontekst, ale są mniej wrażliwe na drobne krawędzie i tekstury. W efekcie obie rodziny metod często zawodzą tam, gdzie najważniejsze jest niezawodne oszacowanie — na dużych odległościach.
Łączenie dwóch sposobów widzenia
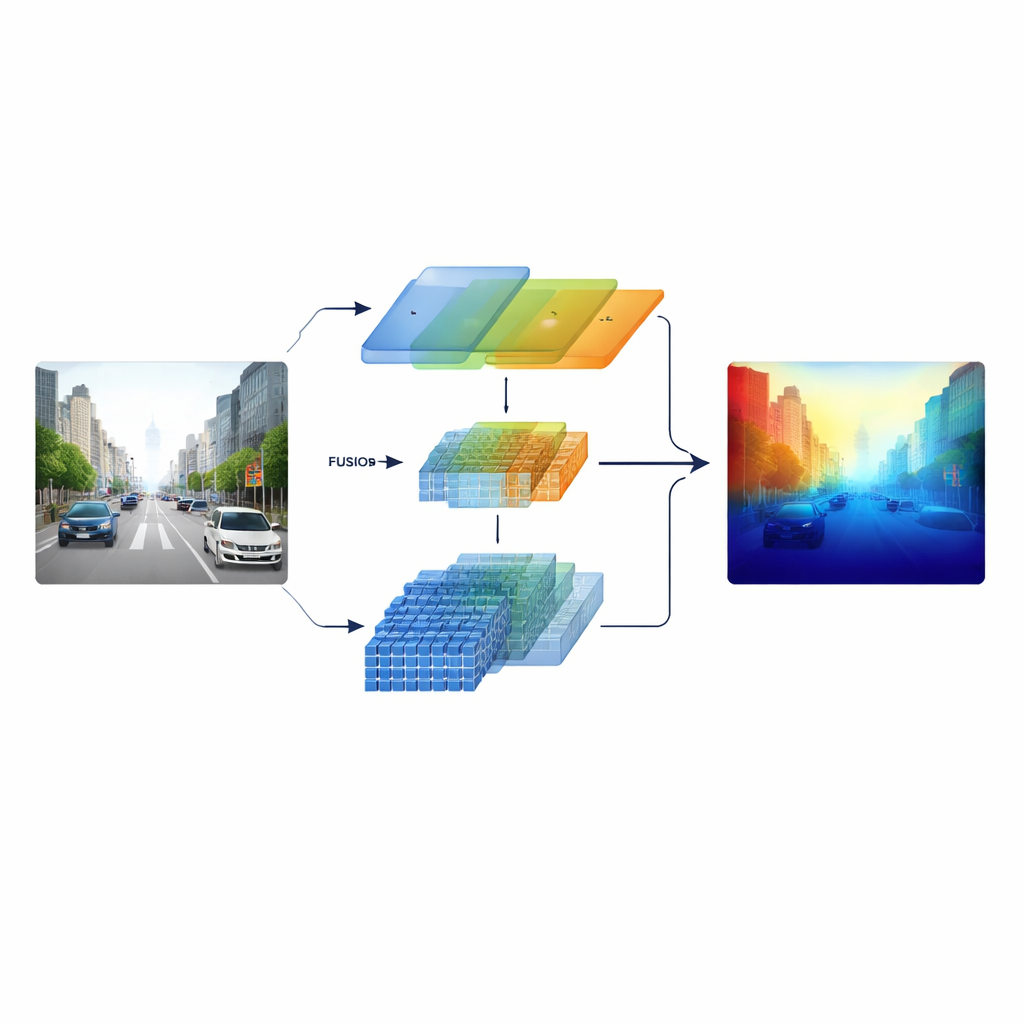
Badacze rozwiązują to, budując „heterogeniczny” enkoder, który uruchamia równolegle dwa różne typy przetwarzania obrazu. Jedna gałąź opiera się na klasycznej, ResNet‑owej sieci konwolucyjnej wyspecjalizowanej w ostrych lokalnych wzorcach, takich jak oznaczenia pasa, słupy i krawędzie obiektów. Druga gałąź wykorzystuje Swin Transformera, zaprojektowanego do wychwytywania długozasięgowych powiązań w obrazie, na przykład układu korytarza drogi czy sylwetki odległych budynków. Zamiast łączyć te dwie perspektywy dopiero na końcu, system zachowuje cechy wieloskalowe z obu gałęzi i przekazuje je do starannie zaprojektowanego etapu fuzji, tak aby drobna struktura i szeroki kontekst wzajemnie się uzupełniały przez cały proces.
Przekraczanie kanałów, przestrzeni i skali
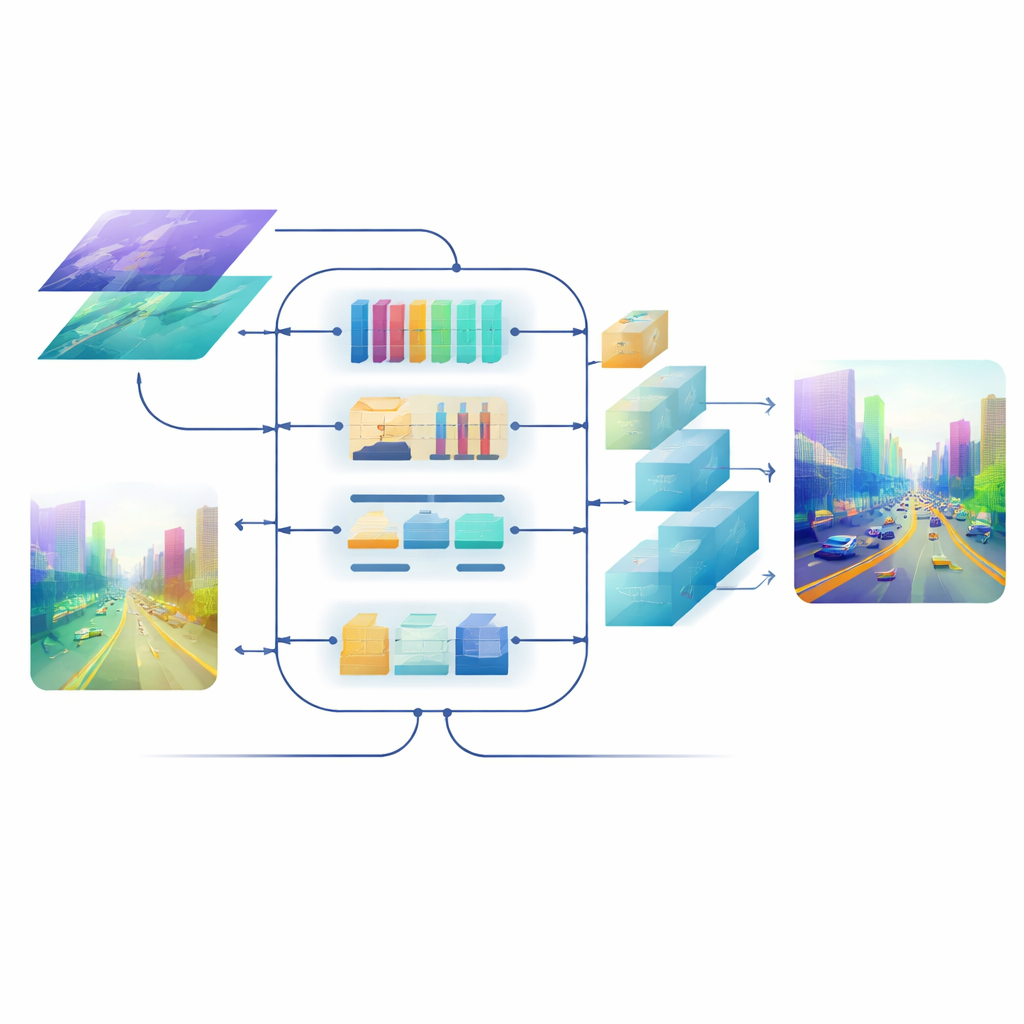
W sercu modelu znajduje się moduł Cross-dimensional Semantic Fusion, który działa jak inteligentne pomieszczenie spotkań dla dwóch strumieni informacji. Najpierw decyduje, które kanały — różne typy wyuczonych wzorców wizualnych — zasługują na większą uwagę, balansując sygnały z tekstur o wysokiej szczegółowości i wskazówek scenicznych na wyższym poziomie. Następnie rozpatruje osobno kierunki poziome i pionowe, które są szczególnie istotne w scenach pełnych dróg, budynków i drzew, aby wyeksponować ważne struktury rozciągające się przez obraz. Wreszcie miesza płytkie, bogate w detale cechy z głębszymi, bardziej abstrakcyjnymi na kilku skalach. Krok z uczącym się ważeniem pozwala sieci zdecydować, ile ufać każdej gałęzi dla danego regionu, dzięki czemu małe, odległe obiekty nie zostają zagłuszone przez bliską scenę.
Uszlachetnianie końcowego obrazu
Nawet mając dobrze zfuzowane cechy, przekształcenie ich z powrotem w mapę głębi o pełnej rozdzielczości może rozmywać krawędzie i utracać cienkie struktury. Aby tego uniknąć, zespół zaprojektował dekoder oparty na mechanizmach uwagi. Bloki powiększające używają lekkich konwolucji depth-wise, by powiększyć mapę bez utraty kontekstu, a wieloskalowy mechanizm samo-uwagi grupuje kanały cech tak, by policzyć uwagę efektywnie. Ten etap dopracowuje prognozy głębi na każdej skali, utrzymując przy tym kontrolę nad obciążeniem obliczeniowym. Efektem jest gładkie, spójne pole głębi, w którym granice obiektów — na przykład kontur oddalonego rowerzysty czy szczeble łóżka piętrowego — pozostają ostre.
Jak dobrze działa w rzeczywistym świecie
Metoda została przetestowana na kilku standardowych zbiorach danych. Na KITTI, dużej kolekcji scen drogowych, model osiąga stan wiedzy w większości powszechnie stosowanych miar, a co kluczowe, generuje najniższy błąd w wyznaczonych obszarach długodystansowych. Zapewnia też czystsze granice głębi wokół obiektów niż konkurencyjne systemy. Na NYU Depth V2, zawierającym sceny wnętrz, oraz na benchmarku SUN RGB-D ten sam model dobrze się uogólnia, rekonstruując meble i układy pomieszczeń w przekonujących chmurach punktów 3D. Badania ablacyjne — systematyczne testy usuwające lub zamieniające komponenty — pokazują, że każdy proponowany element, od hybrydowego enkodera po moduł fuzji i blok uwagi dekodera, mierzalnie poprawia wydajność, zwłaszcza dla odległych obszarów o niskiej teksturze.
Co to oznacza dla codziennej technologii
Mówiąc prościej, ta praca uczy sieć neuronową używać jednocześnie lupy i szerokokątnego obiektywu oraz łączyć je w przemyślany sposób. Poprzez lepsze wyważenie lokalnych detali i globalnego rozumienia sceny proponowane rozwiązanie znacząco poprawia zdolność pojedynczej kamery do oceny głębi daleko na drodze lub w całym pomieszczeniu. To sprawia, że praktyczniejsze staje się wyposażenie robotów, pojazdów i dronów w tańsze sensory, zapewniając im jednocześnie bogate trójwymiarowe rozumienie świata — ważny krok w kierunku bezpieczniejszych, bardziej zdolnych i bardziej przystępnych cenowo systemów autonomicznych.
Cytowanie: Chen, Y., Yin, Q., Zhao, L. et al. Enhancing long-range depth estimation via heterogeneous CNN-transformer encoding and cross-dimensional semantic fusion. Sci Rep 16, 9396 (2026). https://doi.org/10.1038/s41598-026-36755-0
Słowa kluczowe: estymacja głębi z jednej kamery, wizja komputerowa, fuzja transformera i CNN, jazda autonomiczna, rekonstrukcja scen 3D