Clear Sky Science · pl
Dopasowanie średnich w jądrze poprawia estymację ryzyka przy przestrzennych przesunięciach rozkładu
Dlaczego ważne jest ocenianie ryzyka przy zmieniających się mapach
Modele uczenia maszynowego są coraz częściej wykorzystywane do przewidywania, gdzie będą występować gatunki, jak są zorganizowane guzy w tkance czy jak rozprzestrzenia się zanieczyszczenie. Dane używane do trenowania tych modeli bywają jednak zbierane w bardzo konkretnych miejscach — gęsto próbkowane okolice miast, szpitale czy łatwo dostępne stanowiska terenowe — podczas gdy modele stosuje się na znacznie większych, odmiennych obszarach. Ta rozbieżność między miejscem pochodzenia danych a miejscem prognozowania może sprawiać, że modele wydają się bezpieczniejsze i dokładniejsze, niż są w rzeczywistości. Artykuł „Kernel mean matching enhances risk estimation under spatial distribution shifts” stawia pozornie proste pytanie: kiedy świat wygląda inaczej niż Twoje dane treningowe, jak bardzo model może się mylić i jak to wykryć?
Kiedy trening i testowanie żyją w różnych światach
W statystyce „ryzyko” modelu to jego oczekiwany błąd na nowych, niewidzianych danych. Standardowe sztuczki oceniające — jak walidacja krzyżowa czy wydzielenie losowego zestawu testowego — cicho zakładają, że dane treningowe i testowe pochodzą z tego samego rozkładu. Dane przestrzenne łamią to założenie. Gradienty środowiskowe, skupione próbkowanie i zmieniający się klimat powodują, że warunki, w których trenujemy model, mogą znacznie różnić się od tych, w których go wdrażamy. Na przykład obserwacje gatunków często koncentrują się przy drogach, podczas gdy decyzje ochronne dotyczą obszarów odległych; próbki guzów mogą pochodzić z jednej części tkanki, a predykcje są potrzebne gdzie indziej. W takich przypadkach konwencjonalne estymaty ryzyka mają tendencję do nadmiernego optymizmu, ukrywając, jak bardzo model może zawieść w nowych lokalizacjach.
Stare narzędzia mają problemy z uprzedzeniami przestrzennymi
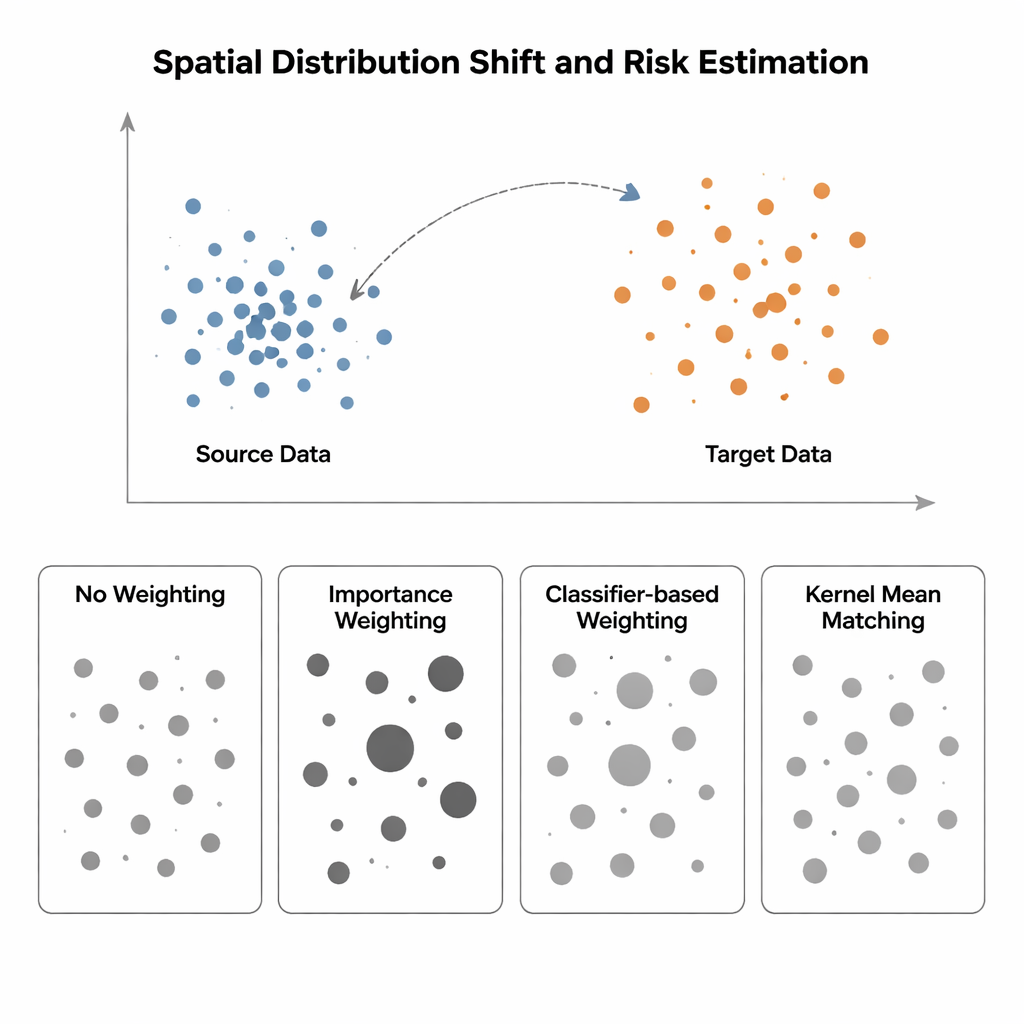
W badaniu porównano cztery sposoby estymacji ryzyka modelu, gdy rozkład wejściowy przesuwa się z regionu „źródłowego” (gdzie etykiety są znane) do regionu „docelowego” (gdzie etykiety są rzadkie lub brakujące). Najprostsza metoda, nazwana Brak Wag, mierzy po prostu średni błąd na dostępnych danych i zakłada, że źródło i cel są podobne — założenie, które zawodzi przy uprzedzeniach przestrzennych. Ważenie istotnościowe próbuje to naprawić przez skalowanie każdej próbki źródłowej w zależności od tego, jak często taki punkt występuje w celu względem źródła. W teorii to przywraca poprawne ryzyko, ale w praktyce wymaga estymacji gęstości w wysokich wymiarach. Gdy dane źródłowe są ciasno skupione, a dane docelowe bardziej rozproszone — typowa sytuacja w ekologii przestrzennej czy obrazowaniu medycznym — te estymaty gęstości stają się zawodna i kilka próbek otrzymuje ogromne wagi, co czyni estymatę ryzyka bardzo niestabilną. Podejścia oparte na klasyfikatorach, które uczą klasyfikatora rozróżniającego punkty źródłowe od docelowych i zamieniają jego prawdopodobieństwa na wagi, unikają jawnej estymacji gęstości, ale często dają źle skalibrowane ryzyka, ponieważ optymalizują trafność klasyfikacji, a nie dopasowanie rozkładów.
Inna droga: bezpośrednie dopasowanie rozkładów
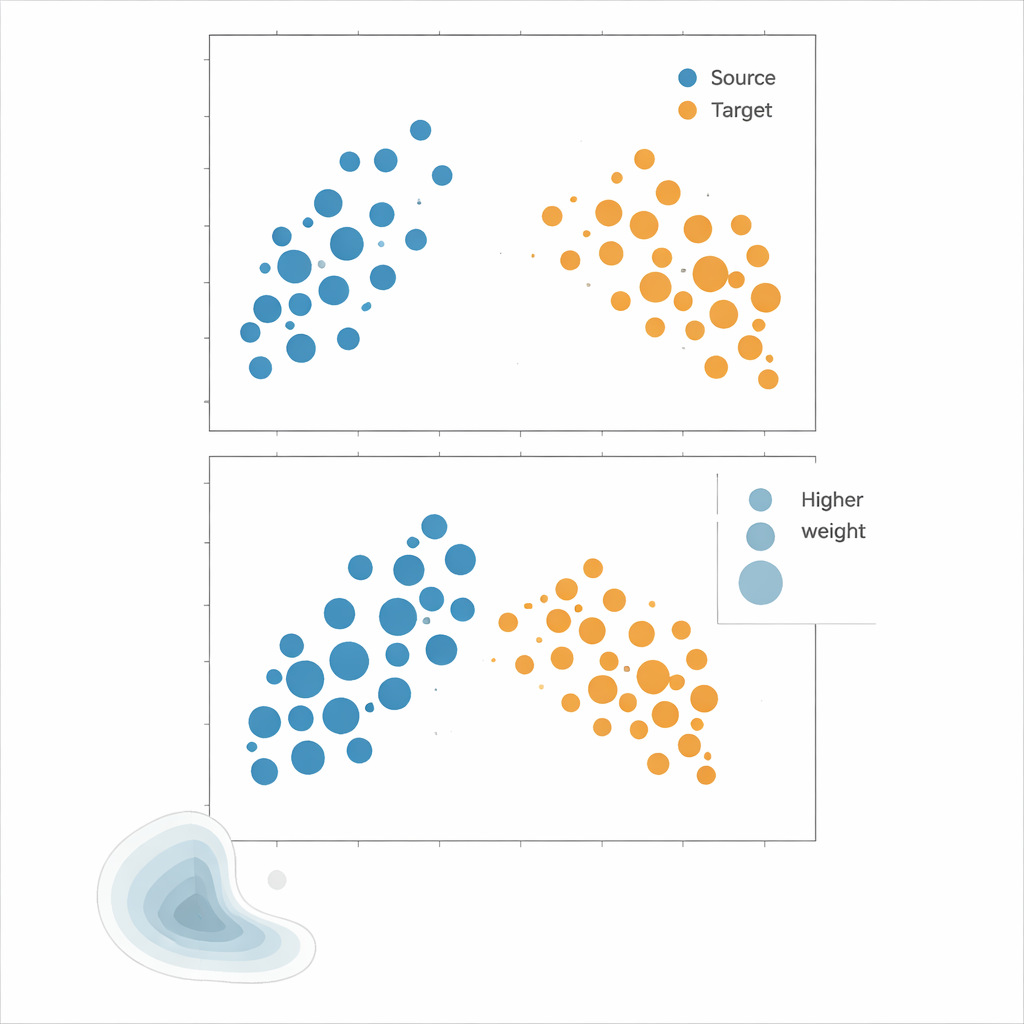
Autorzy polecają dopasowanie średnich w jądrze (Kernel Mean Matching, KMM), podejście omijające estymację gęstości. Zamiast próbować policzyć, jak prawdopodobny jest każdy punkt w źródle i w celu, KMM poszukuje wag dla próbek źródłowych, które sprawiają, że ich średnia „sygnatura” w elastycznej przestrzeni cech zdefiniowanej przez jądro zgadza się ze średnią próbek docelowych. Intuicyjnie rozciąga lub kurczy wpływ poszczególnych punktów źródłowych tak, aby ważona chmura punktów źródłowych razem przypominała chmurę punktów docelowych. Po znalezieniu tych wag ryzyko estymuje się jako ważoną średnią błędów na źródle. Narzędzie uzupełniające, Funkcja Korelacji Lokalnej, mierzy, jak bardzo dane są skupione w przestrzeni; służy jako diagnostyka, która pokazuje, kiedy przesunięcia rozkładu są na tyle silne, że przeważanie ma sens.
Postawienie metod na próbę
Aby sprawdzić, która strategia działa najlepiej, autorzy przeprowadzili obszerne eksperymenty na danych syntetycznych i rzeczywistych. Syntetyczne „krajobrazy” budowane są z mieszanin klastrów Gaussa, których rozmiar, kształt i pokrycie domeny można precyzyjnie kontrolować, co pozwala na testy strukturalne, takie jak przycinanie części domeny, zmiana wzorców korelacji między cechami czy przełączanie między silnie skupionymi a niemal jednorodnymi rozkładami punktów. Zbiorami rzeczywistymi są m.in. wystąpienia roślin w krajach nordyckich opisane klimatem i lokalizacją oraz przestrzenne układy komórek odpornościowych w obrębie guzów. W tych scenariuszach modele trenuje się na skupionych danych źródłowych i ocenia na mniej skupionych danych docelowych, naśladując typowe uprzedzenia w próbkowaniu. Wydajność oceniano za pomocą kilku miar błędu, koncentrując się na tym, jak ściśle estymowane ryzyko każdej metody śledzi prawdziwy błąd na celu.
Mniej zawodna estymacja ryzyka w złożonych, wysokowymiarowych przestrzeniach
W prawie wszystkich zestawieniach syntetycznych i rzeczywistych KMM dostarcza najdokładniejsze i najstabilniejsze estymaty ryzyka. Zmniejsza średni bezwzględny błąd procentowy o około 12 do 87 procent w porównaniu z alternatywami i co istotne unika „eksplozji wag”, która dręczy ważenie istotnościowe w wysokich wymiarach. Na przykład w trudnych układach rozmieszczenia komórek nowotworowych ważenie istotnościowe może generować błędy przekraczające kilka tysięcy procent, podczas gdy KMM pozostaje w granicach rozsądku. Przeważanie oparte na klasyfikatorach zazwyczaj poprawia wyniki względem metod naiwnych, ale wciąż ustępuje KMM, co odzwierciedla jego fokus na dyskryminacji zamiast wiernego dopasowania rozkładów. Wyniki te sugerują, że w zastosowaniach przestrzennych — gdzie dane są skupione, obarczone uprzedzeniami i wysokowymiarowe — KMM oferuje ugruntowany sposób na ocenę, ile zaufania można pokładać w predykcjach modelu.
Co to oznacza dla decyzji w świecie rzeczywistym
Dla użytkowników spoza specjalizacji, stosujących uczenie maszynowe w ekologii, naukach o środowisku czy biomedycynie, przekaz jest prosty: standardowe wyniki testowe mogą wprowadzać w błąd, gdy region wdrożenia różni się od regionu, z którego pochodzą dane. Dopasowanie średnich w jądrze zapewnia sposób korekty tego stanu przez zrównoważenie wpływu próbek treningowych tak, aby statystycznie przypominały miejsca lub tkanki, które nas interesują. Badanie pokazuje, że to podejście konsekwentnie daje bardziej uczciwe estymaty błędu modelu, nawet przy silnych uprzedzeniach przestrzennych i wielu zmiennych wejściowych. W praktyce oznacza to bardziej wiarygodne wskazówki przy wyborze modeli oraz jaśniejszy obraz tego, gdzie prognozy są godne zaufania — i gdzie trzeba zachować ostrożność.
Cytowanie: Serov, E., Koldasbayeva, D. & Zaytsev, A. Kernel mean matching enhances risk estimation under spatial distribution shifts. Sci Rep 16, 6921 (2026). https://doi.org/10.1038/s41598-026-36740-7
Słowa kluczowe: przesunięcie rozkładu, modelowanie przestrzenne, dopasowanie średnich w jądrze, estymacja ryzyka modelu, dane ekologiczne i biomedyczne