Clear Sky Science · pl
Wzmacnianie odporności na ataki w semantycznym buforowaniu dla bezpiecznych systemów retrieval-augmented generation
Dlaczego inteligentniejsza pamięć AI ma znaczenie
Wraz z wprowadzaniem chatbotów i asystentów AI do miejsc pracy, szkół, a nawet szpitali, coraz częściej polegają one na sztuczce polegającej na „zapamiętywaniu” poprzednich pytań, aby móc szybciej i taniej odpowiadać na podobne zapytania. Ta pamięć, znana jako semantyczny bufor, może znacznie obniżyć koszty i opóźnienia — ale może też otworzyć tylne drzwi dla atakujących, którzy chcą wyprowadzić system na błędne odpowiedzi lub wymusić wyciek poufnych informacji. Artykuł bada te ukryte ryzyka i przedstawia nowy projekt, SAFE-CACHE, który ma na celu utrzymanie szybkości pamięci AI przy jednoczesnym znacznym utrudnieniu jej nadużywania.
Jak współczesne asystenty AI ponownie wykorzystują poprzednie odpowiedzi
Nowoczesne duże modele językowe (LLM) często działają w konfiguracji zwanej retrieval-augmented generation (RAG). Gdy zadajesz pytanie, system najpierw odnajduje istotne dokumenty, a następnie LLM generuje odpowiedź, korzystając z tych materiałów. Ponieważ wiele osób zadaje niemal te same pytania innymi słowami, firmy dodają teraz semantyczny bufor: zbiór starych pytań i odpowiedzi oraz matematyczne odciski ich znaczeń. Gdy pojawia się nowe zapytanie, system sprawdza, czy jego odcisk jest „wystarczająco bliski” któremuś z już zapisanych; jeśli tak, po prostu ponownie wykorzystuje starą odpowiedź zamiast przeprowadzać cały proces wyszukiwania i generowania. Pomysł ten, wdrażany przez narzędzia takie jak GPTCache oraz platformy chmurowe Microsoftu i Google’a, oszczędza koszty i przyspiesza odpowiedzi w botach obsługi klienta, wewnętrznych narzędziach firmowych i innych usługach AI o dużym natężeniu ruchu. 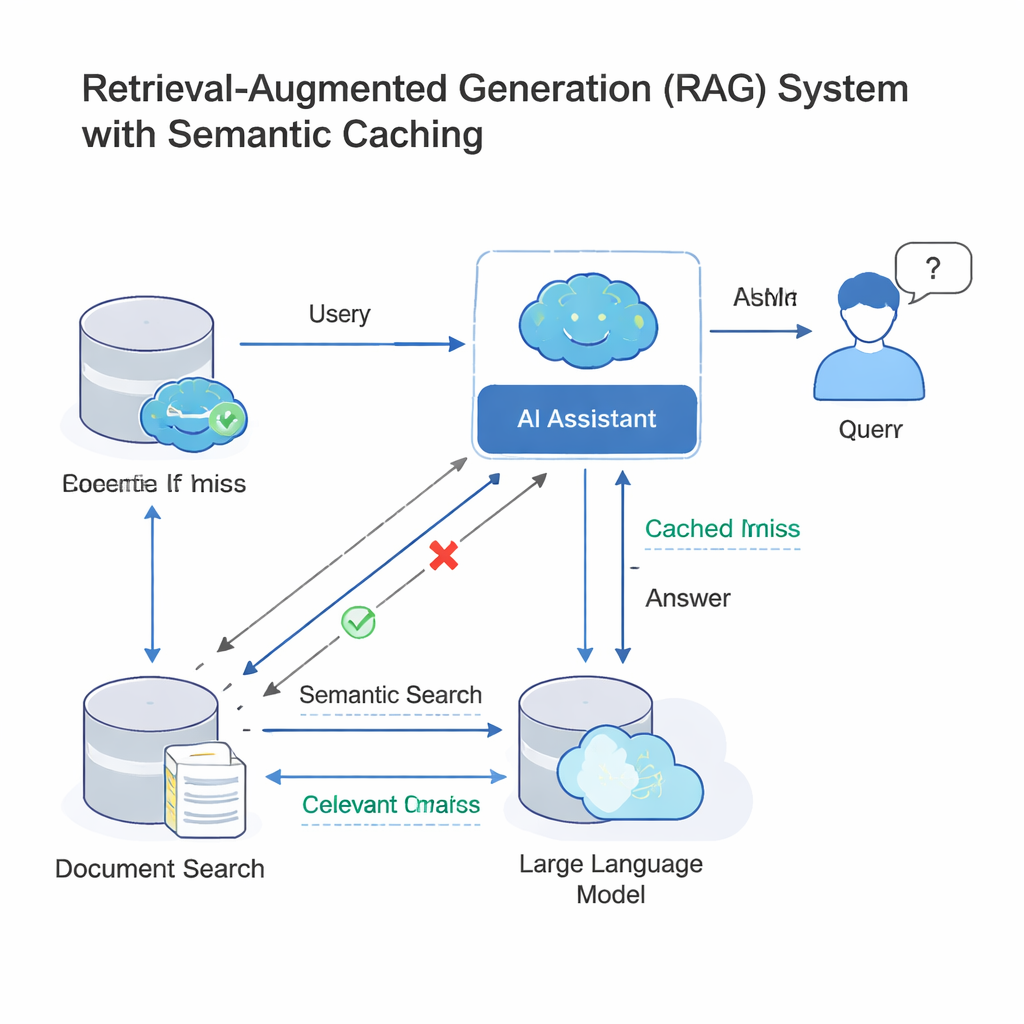
Gdy sprytne sformułowanie zamienia się w lukę bezpieczeństwa
Ta sama skrótowa metoda, która zwiększa prędkość, może zostać obrócona przeciwko systemowi. Atakujący mogą konstruować zapytania, które wyglądają podobnie strukturalnie, lecz znaczą coś innego — zmieniając datę, podstawiając osobę lub miejsce albo odwracając sens pytania. Ponieważ dzisiejsze bufory w dużej mierze ufają liczbowej podobieństwie osadzonych wektorów (tych odcisków znaczeń), złośliwe zapytanie może „kolidować” z benignowym w tej przestrzeni wektorowej, mimo że intencja się zmieniła. Taka kolizja może spowodować zwrócenie niewłaściwej odpowiedzi z bufora, potencjalnie ujawniając poufne informacje lub powodując zapisanie złych danych do późniejszego ponownego użycia. Wcześniejsze prace wykazały już, że bazy wektorowe i semantyczne bufory można w ten sposób truć, szczególnie gdy wielu użytkowników dzieli ten sam bufor w systemach multi-tenant.
Przekształcanie rozproszonych pytań w stabilne klastry intencji
Autorzy twierdzą, że źródłem problemu jest traktowanie każdego zapytania jako izolowanego przypadku. Ich rozwiązanie, SAFE-CACHE, grupuje pary pytanie–odpowiedź z przeszłości w klastry reprezentujące podstawowe intencje — na przykład „kto wygrał wybory do senatu Arizony w 2022 roku?” albo „jaka jest cena oprogramowania Full Self-Driving Tesli?”. Zamiast dopasowywać nowe zapytania bezpośrednio do pojedynczych starych elementów, SAFE-CACHE porównuje je ze środkiem, czyli centroidem, każdego klastra. Aby zbudować te klastry, najpierw osadza każde pełne pytanie wraz z odpowiedzią (nie tylko samo pytanie), tak by różnice w odpowiedziach — na przykład odmowa ujawnienia danych wrażliwych — również wpływały na grupowanie. Następnie używa algorytmu wykrywania społeczności do znalezienia naturalnych klastrów i testów statystycznych do oznaczania hałaśliwych grup, które mogą mieszać różne intencje lub zawierać pozycje adwersarialne. Podejrzane klastry są oczyszczane i dzielone przy użyciu specjalnie wytrenowanego bi-enkodera, który nauczył się zbliżać uczciwe przykłady i oddalać zainfekowane.
Uczenie małego modelu wzmacniania pamięci AI
Niektóre intencje pojawiają się w rzeczywistym ruchu tylko kilka razy, co sprawia, że ich klastry są kruche. Aby je ustabilizować, SAFE-CACHE wykorzystuje dostrojony lekki model językowy (wariant Gemma-3 o 1 miliardzie parametrów) do generowania parafraz zachowujących tę samą intencję przy różnych sformułowaniach. Dodatkowe przykłady zagęszczają klastry i sprawiają, że ich centroidy są bardziej wiarygodne, bez potrzeby ręcznego oznaczania tysięcy wariantów. W czasie działania każde nowe zapytanie jest osadzane i porównywane z tymi centroidami. Jeśli jego podobieństwo do najlepiej dopasowanego centroidu przekracza starannie dobrany próg, zwracana jest odpowiedź z bufora; w przeciwnym razie system wraca do pełnego potoku RAG i później decyduje, jak sklastrować nową parę. W eksperymentach wykorzystujących silne metody ataku oparte na przekształceniach metamorfistycznych i GPT‑4.1, SAFE-CACHE zmniejszył liczbę udanych prób zatruć o około dwie trzecie do trzech czwartych w porównaniu z projektem w stylu GPTCache, przy zachowaniu praktycznie niezmienionej szybkości odpowiedzi. 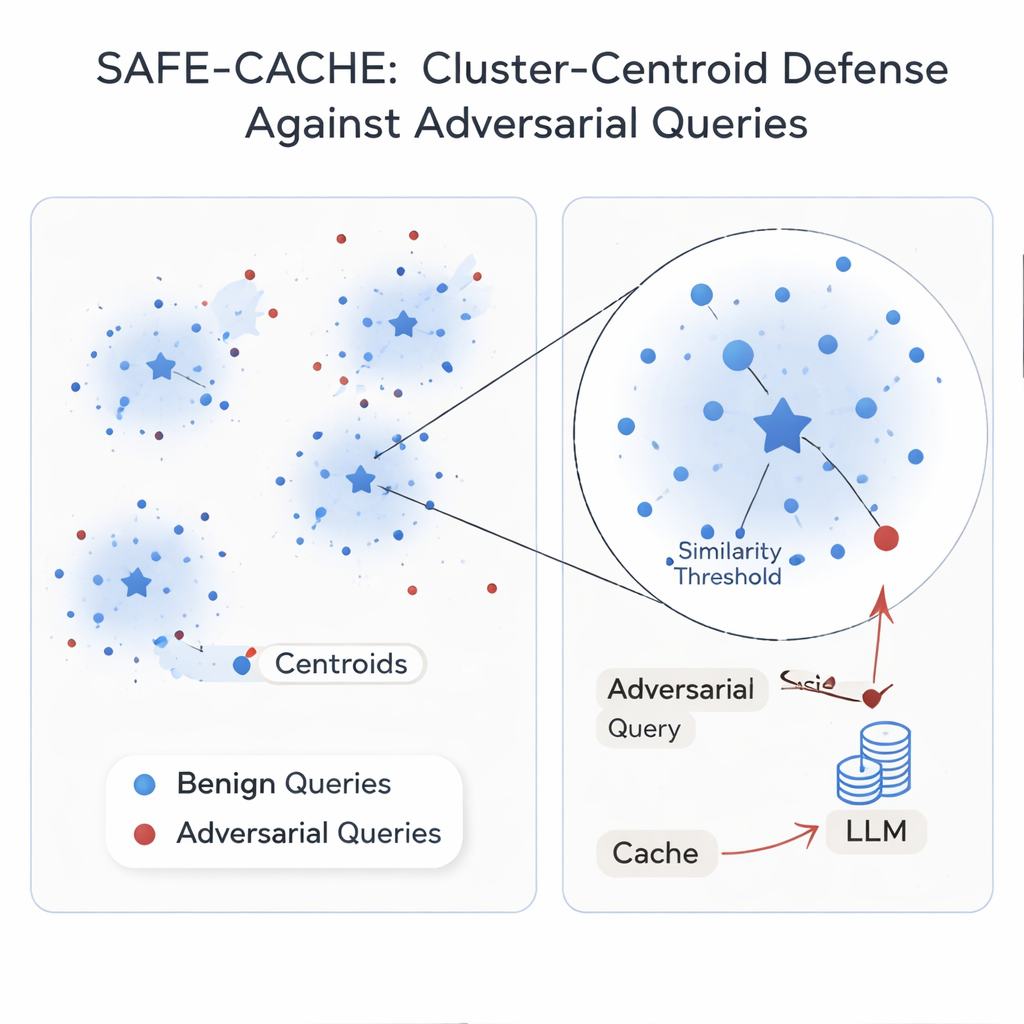
Co to oznacza dla codziennych użytkowników AI
Dla nietechnicznych odbiorców wniosek jest taki, że nadawanie systemom AI „pamięci” nie jest bezkosztowe: naiwny projekt może prowadzić do wycieków tajemnic lub wprowadzania błędnych odpowiedzi. SAFE-CACHE pokazuje, że organizując pamięć wokół głębszych wzorców na poziomie intencji i wzmacniając te wzorce ukierunkowanymi parafrazami, można zachować korzyści prędkości i kosztów wynikające z semantycznego buforowania przy jednoczesnym znaczącym zmniejszeniu ryzyka ataku. W miarę jak asystenci AI stają się furtką do wrażliwych danych — od dokumentów firmowych po informacje osobiste — podejścia takie jak SAFE-CACHE będą kluczowe, aby upewnić się, że to, co AI zapamiętuje, nie może być łatwo użyte przeciwko nam.
Cytowanie: Afiffy, M., Fakhr, M.W. & Maghraby, F.A. Enhancing adversarial resilience in semantic caching for secure retrieval augmented generation systems. Sci Rep 16, 5936 (2026). https://doi.org/10.1038/s41598-026-36721-w
Słowa kluczowe: semantyczne buforowanie, retrieval-augmented generation, ataki adwersarialne, obrona oparta na klastrach, bezpieczeństwo LLM