Clear Sky Science · pl
Autoenkoder kierowany ważnością cech do redukcji wymiarowości w systemach wykrywania włamań
Dlaczego mądrzejsza obrona cybernetyczna ma znaczenie
Każdy e‑mail, który wysyłasz, każdy streamowany film i każde dokonane zakupy przechodzą przez sieci stale narażone na ataki. Systemy wykrywania włamań (IDS) pełnią rolę alarmów dla tych sieci, wykrywając podejrzane zachowania, zanim przerodzą się w kompromitację. Jednak współczesne dane sieciowe są ogromne i złożone, a ich przesiewanie może spowalniać systemy albo powodować przeoczanie subtelnych ataków. Artykuł opisuje nowy sposób inteligentnego zmniejszania tych danych, dzięki któremu narzędzia IDS stają się szybsze i lepsze w wykrywaniu nawet rzadkich, trudnych do zauważenia cyberataków. 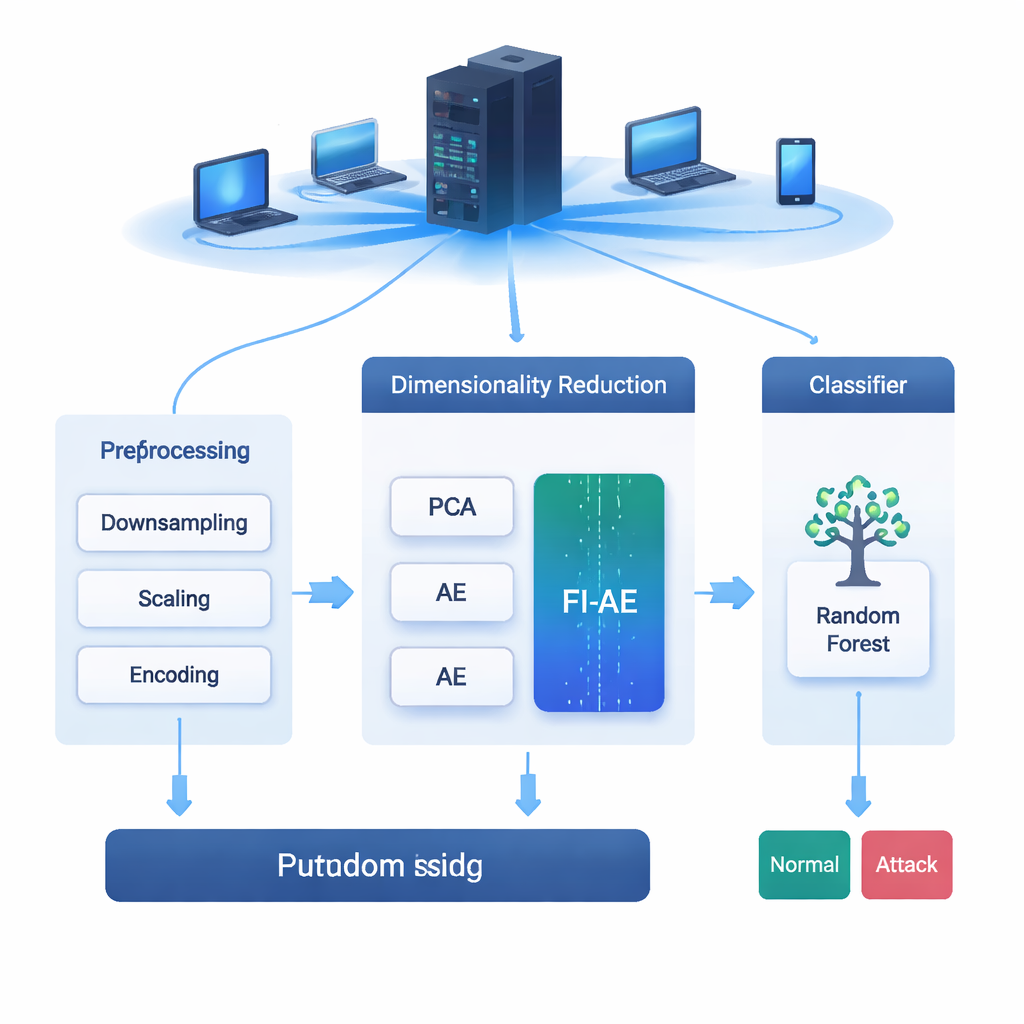
Problem nadmiaru danych sieciowych
Rekordy ruchu sieciowego zawierają dziesiątki, a nawet setki pomiarów dla każdego połączenia — na przykład długość trwania, liczbę bajtów czy wskaźniki błędów. Modele IDS oparte na uczeniu maszynowym polegają na tych pomiarach, aby zdecydować, czy ruch jest normalny, czy złośliwy. Jednak wykorzystanie wszystkich cech może spowolnić wykrywanie, a czasem nawet zaszkodzić dokładności, szczególnie gdy niektóre ataki są znacznie rzadsze niż inne. Popularne metody redukcji wymiarowości, takie jak analiza głównych składowych (PCA) czy standardowe autoenkodery, kompresują dane, ale skupiają się głównie na odtwarzaniu ogólnego charakteru ruchu. Oznacza to, że mogą przywiązywać większą wagę do dominujących, codziennych połączeń i przeoczyć subtelne, wyróżniające wzorce, które charakteryzują rzadkie typy ataków.
Nowy sposób porządkowania cech według znaczenia
Autorzy wprowadzają schemat uszeregowania cech zwany one‑versus‑all (OVA) feature importance, aby zaradzić tej nierównowadze. Zamiast pytać „które pomiary są najbardziej użyteczne ogólnie?”, OVA zadaje to pytanie oddzielnie dla każdego typu ataku. Dla każdej klasy (na przykład ruch normalny, odmowa usługi czy zgadywanie haseł) trenuje się model lasu losowego, aby odróżnić tę klasę od wszystkich pozostałych. Wbudowane w model oceny ważności wskazują, które pomiary są szczególnie pomocne dla danej klasy. Powtarzając ten proces dla każdej klasy, a następnie dla każdego pomiaru wybierając najwyższą ważność, jaką osiągał dla którejkolwiek klasy, metoda buduje jedną wektorową wagę, która uwypukla cechy istotne dla co najmniej jednego rodzaju ataku — nawet jeśli ten atak jest rzadki w danych.
Nauczanie autoenkodera, aby koncentrował się na kluczowych sygnałach
Aby wykorzystać te wagi, badacze zaprojektowali autoenkoder oparty na ważności cech (FI‑AE). Podobnie jak konwencjonalny autoenkoder, FI‑AE kompresuje dane wejściowe do niskowymiarowej reprezentacji „wąskiego gardła”, a następnie rekonstruuje oryginalne dane. Nowość polega na funkcji celu treningu: zamiast traktować wszystkie błędy rekonstrukcji jednakowo, model używa ważonego średniego błędu kwadratowego, który mnoży błąd każdego atrybutu przez jego ważność z OVA. Mówiąc prościej, FI‑AE jest bardziej karany za błędne odwzorowanie pomiarów kluczowych do rozróżnienia ataków, a mniej za mniej informacyjne szczegóły. Sama architektura jest kompaktowa, ściskając rekordy sieciowe do zaledwie 16 liczb i stosując standardowe techniki, takie jak normalizacja wsadu (batch normalization), dropout i optymalizator Adam, aby utrzymać stabilność treningu.
Testowanie metody
Zespół ocenił FI‑AE na trzech powszechnie używanych zestawach danych do wykrywania włamań: NSL‑KDD, UNSW‑NB15 oraz CIC‑IDS2017, które łącznie obejmują miliony połączeń i szeroki zakres typów ataków. Przed treningiem uporządkowali dane, równoważąc silnie skośne rozkłady klas, skalując cechy numeryczne i kodując kategorie w sposób zachowujący ich relację z etykietami docelowymi. Następnie porównali trzy pipeline’y kończące się klasyfikatorem lasu losowego: jeden z PCA, jeden ze standardowym autoenkoderem oraz jeden z FI‑AE do redukcji wymiarowości. We wszystkich trzech zbiorach danych FI‑AE konsekwentnie osiągał wyższą dokładność i miary F1, z szczególnie zauważalnymi poprawami dla klas mniejszościowych i rzadkich ataków, na których tradycyjne metody mają tendencję do słabości. 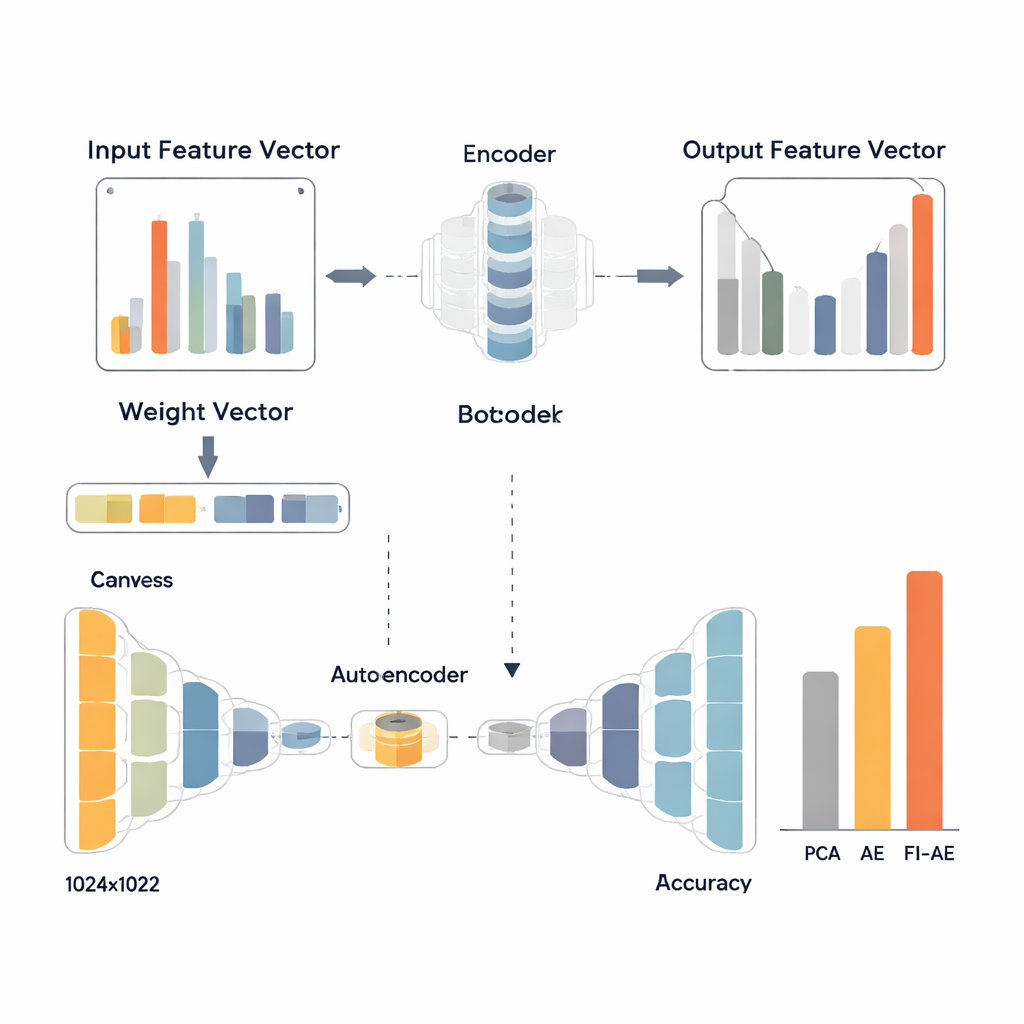
Co to znaczy dla codziennego bezpieczeństwa
Dla osób niespecjalizujących się w temacie kluczowy wniosek jest taki, że praca ta oferuje bardziej wybiórcze spojrzenie na monitorowanie sieci. Zamiast jedynie kompresować dane, aby były mniejsze, FI‑AE uczy się zachowywać te pomiary, które naprawdę mają znaczenie dla wykrywania różnych typów ataków, w tym rzadkich, które mogą wyrządzić największe szkody. Mając tylko 16 skondensowanych cech, systemy wykrywania włamań oparte na tym podejściu mogą działać wydajniej, jednocześnie osiągając lub przewyższając stan wiedzy pod względem dokładności wykrywania. W praktyce oznacza to, że narzędzia bezpieczeństwa mogą skanować więcej ruchu, reagować szybciej i zapewniać lepszą ochronę usług cyfrowych, na których ludzie polegają każdego dnia.
Cytowanie: Abdel-Rahman, M.A., Alluhaidan, A.S., El-Rahman, S.A. et al. Feature importance guided autoencoder for dimensionality reduction in intrusion detection systems. Sci Rep 16, 5013 (2026). https://doi.org/10.1038/s41598-026-36695-9
Słowa kluczowe: wykrywanie włamań, bezpieczeństwo sieci, redukcja wymiarowości, autoenkoder, ważność cech