Clear Sky Science · pl
Wykrywanie ognia i dymu w czasie rzeczywistym przy użyciu wizjonerskich transformerów i uczenia czasoprzestrzennego
Dlaczego szybsze alarmy pożarowe mają znaczenie
Pożary w domach, fabrykach i lasach mogą stać się śmiertelne w ciągu kilku minut. Dziś wiele alarmów wciąż polega na czujnikach ciepła lub dymu, które reagują dopiero, gdy płomienie są już dobrze rozwinięte. W tym artykule opisano nowy system widzenia komputerowego, który potrafi niemal natychmiast wykrywać oznaki ognia i dymu na nagraniach z kamer, nawet w trudnych warunkach, takich jak słabe oświetlenie czy silna mgła. Poprzez połączenie kilku zaawansowanych technik sztucznej inteligencji w jednym modelu, badacze dążą do dostarczania strażakom, urbanistom i agencjom ochrony środowiska znacznie wcześniejszego sygnału ostrzegawczego — co może ratować życie, mienie i ekosystemy.
Rosnące wyzwanie wykrywania płomieni
Nowoczesne miasta i obszary leśne są coraz częściej monitorowane kamerami, ale nauczenie komputerów niezawodnego rozpoznawania ognia i dymu na tych obrazach i wideo jest trudne. Tradycyjne podejścia wykorzystują sieci neuronowe, które dobrze radzą sobie ze statycznymi obrazami lub krótkimi klipami, jednak często zawodzą w chaotycznych scenach z rzeczywistego świata. Pojedyncze zdjęcie może pokazywać coś, co wygląda jak dym, a w rzeczywistości jest tylko mgłą lub spalinami. Systemy skupione na wideo potrafią śledzić ruch kształtów w czasie, lecz zwykle są wolne i wymagające dla sprzętu. W efekcie wcześniejsze modele często generowały fałszywe alarmy lub przegapiały subtelne, szybko zmieniające się oznaki niebezpieczeństwa — zwłaszcza przy słabym oświetleniu, gęstym dymie lub zagraconym tle.
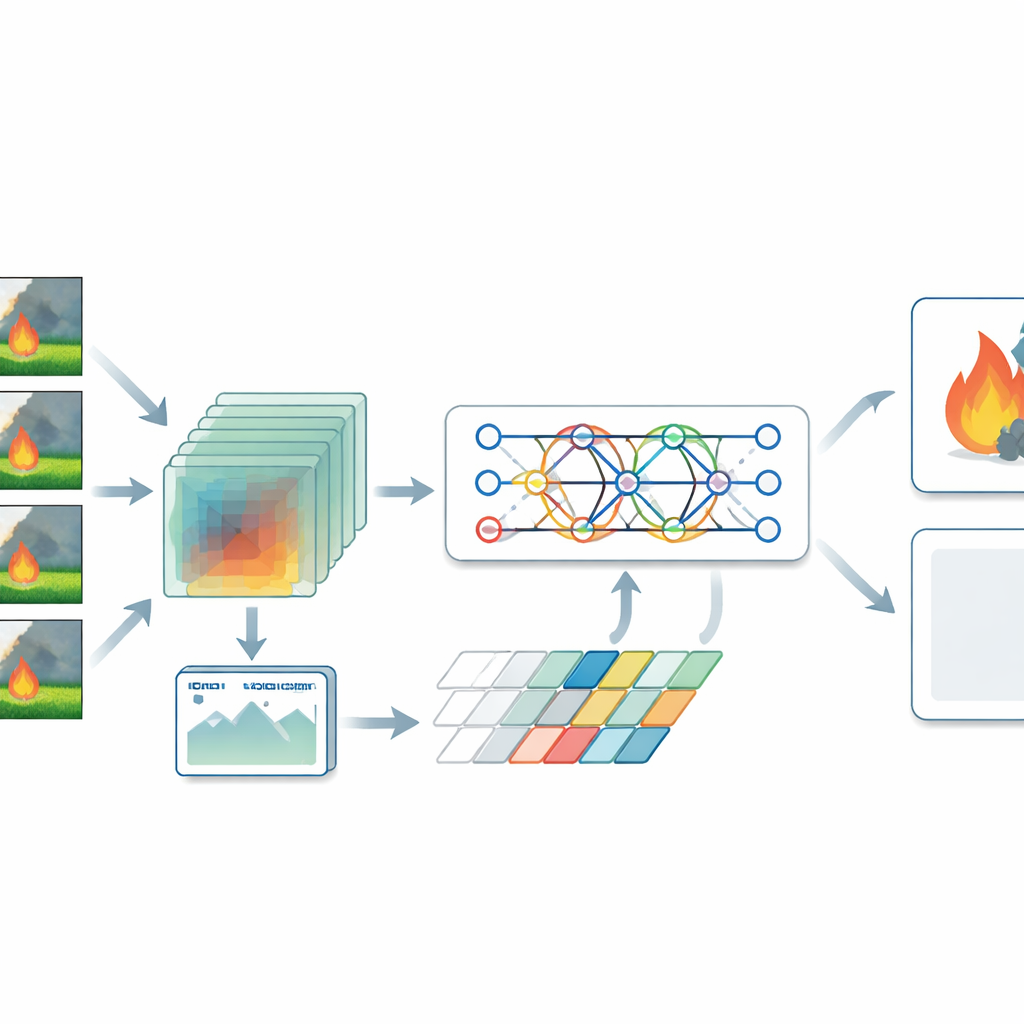
Hybrydowy „obserwator” AI dla obrazów i wideo
Autorzy proponują model hybrydowy, który traktuje wykrywanie pożaru zarówno jako problem przestrzenny, jak i czasowy. Dla obrazów statycznych wykorzystują rodzaj sieci neuronowej zwanej vision transformerem, która analizuje obraz jako mozaikę regionów i uczy się, jak odległe obszary są ze sobą powiązane. Dzięki temu potrafi dostrzec szerokie wzory, takie jak smugi dymu rozciągające się przez dolinę czy rozproszone płomienie w lesie. Dla wideo system polega na trójwymiarowej sieci konwolucyjnej, która przetwarza jednocześnie stos klatek, wychwytując, jak dym i ogień zmieniają się w czasie. Następnie enkoder transformerowy analizuje te zmiany i skupia uwagę na chwilach oraz regionach najbardziej prawdopodobnych dla niebezpieczeństwa, zamiast nadawać równą wagę każdej klatce.
Łączenie wskazówek i równoważenie danych
Kluczowym elementem systemu jest warstwa fuzji, która łączy szczegółowe wskazówki ze zdjęć statycznych z wzorami ruchu z wideo. Dzięki skomponowaniu tych uzupełniających się widoków model lepiej odróżnia prawdziwe pożary od nieszkodliwych podobieństw, takich jak refleksy zachodzącego słońca, mgła czy chmury. Badacze zauważyli również, że wiele publicznych zestawów danych zawiera znacznie więcej przykładów z ogniem niż bezogniskowych, co może powodować, że model będzie nadmiernie zgłaszał płomienie. Aby temu przeciwdziałać, wygenerowali szeroką gamę realistycznych scen bezogniowych poprzez staranne augmentacje danych — zmianę jasności, kadrowanie i odbicia lustrzane obrazów oraz symulowanie sytuacji, takich jak mgłą poranki czy słabo oświetlone wnętrza. Następnie trenowali model z funkcją straty, która explicite wyrównuje błędy popełniane na przypadkach z ogniem i bez ognia, poprawiając niezawodność w codziennym użyciu.
Testowanie systemu
Aby sprawdzić skuteczność swojego podejścia, autorzy przetestowali je na dwóch szeroko stosowanych zbiorach danych: jednym prawie tysiąca pojedynczych obrazów z NASA Space Apps Challenge i drugim składającym się z wideo związanych z pożarami z platformy Kaggle. Po wstępnej obróbce i zrównoważeniu danych trenowali i oceniali swój model hybrydowy obok znanych bazowych modeli, takich jak ResNet, VGG, LSTM, czyste sieci 3D konwolucyjne oraz kilku hybrydowych połączeń tych starszych metod. Nowy system osiągnął około 99,2% dokładności na obrazach NASA i 98,3% na zbiorze wideo, wyraźnie przewyższając modele tradycyjne, które zwykle osiągały od średnich 80. do średnich 90. procent. Działał też wystarczająco szybko — w dziesiątkach milisekund na klatkę — i miał umiarkowany rozmiar modelu, co czyni go odpowiednim do wdrożenia na urządzeniach brzegowych, takich jak małe GPU i płytki wbudowane.
Co to oznacza dla codziennego bezpieczeństwa
Mówiąc prostymi słowami, badania te pokazują, że przemyślanie zaprojektowana sztuczna inteligencja może w czasie rzeczywistym analizować materiały z kamer i wiarygodnie odpowiadać na proste, lecz kluczowe pytanie: „Czy tu i teraz występuje ogień lub niebezpieczny dym?” Poprzez łączenie szerokiego kontekstu wizualnego, ruchu w czasie i inteligentnego skupienia uwagi na najbardziej wymownych szczegółach, model hybrydowy znacząco redukuje zarówno przeoczone pożary, jak i fałszywe alarmy. Po dalszym dostrojeniu i ekspozycji na bardziej zróżnicowane sceny — takie jak gęste miasta, przestrzenie podziemne czy ekstremalne warunki pogodowe — może stać się praktycznym fundamentem dla inteligentniejszych systemów alarmowych, sieci monitorowania pożarów lasów oraz narzędzi bezpieczeństwa przemysłowego, które reagują szybciej i dokładniej niż wiele obecnych rozwiązań.
Cytowanie: Lilhore, U.K., Sharma, Y.K., Venkatachari, K. et al. Real time fire and smoke detection using vision transformers and spatiotemporal learning. Sci Rep 16, 8928 (2026). https://doi.org/10.1038/s41598-026-36687-9
Słowa kluczowe: wykrywanie pożaru, wykrywanie dymu, widzenie komputerowe, modele transformerowe, monitorowanie w czasie rzeczywistym