Clear Sky Science · pl
Walidacja kliniczna lekkich architektur CNN dla wiarygodnej wieloklasowej klasyfikacji raka płuca z użyciem technik histopatologicznych
Dlaczego to badanie ma znaczenie dla pacjentów i lekarzy
Rak płuca bywa często śmiertelny, ponieważ jest wykrywany późno lub źle sklasyfikowany, co może opóźnić właściwe leczenie. W tym badaniu sprawdzono, czy niewielkie, efektywne programy komputerowe — zamiast ogromnych, energochłonnych modeli — potrafią wiarygodnie rozpoznawać różne typy raka płuca na podstawie mikroskopowych obrazów tkanek. Jeśli takie lekkie narzędzia sprawdzą się w praktyce, mogłyby być stosowane w szpitalach na całym świecie, także w placówkach o ograniczonych zasobach obliczeniowych, aby wspierać patologów w szybszym i bardziej spójnym stawianiu diagnoz.
Dokładne oglądanie nowotworu przy użyciu mikroskopów cyfrowych
Gdy podejrzany guzek płuca jest usuwany lub pobierany w biopsji, patolodzy badają cienkie, barwione przekroje tkanek pod mikroskopem, aby zdecydować, czy zmiana jest łagodna, czy należy do jednego z typów nowotworu. W pracy tej autorzy koncentrują się na trzech kluczowych kategoriach: tkance płucnej łagodnej, gruczolakoraku płuca i płaskonabłonkowym raku płuca. Podtypy te mają znaczenie kliniczne, ponieważ różnie reagują na leczenie. Zespół wykorzystuje cyfrowe zdjęcia tych preparatów — obrazy histopatologiczne — i pyta, czy zwarte sieci neuronowe potrafią nauczyć się subtelnych wzorców wizualnych rozróżniających każdą klasę, od kształtów komórek po architekturę tkanki, równie wiarygodnie jak znacznie większe modele.
Budowanie mniejszych, lecz mądrzejszych klasyfikatorów cyfrowych
Większość najnowocześniejszych systemów rozpoznawania obrazów jest bardzo duża i wymaga drogich procesorów graficznych, co utrudnia ich wdrożenie w wielu klinikach. Naukowcy zaprojektowali więc cztery „lite” modele analizy obrazów nazwane Lite-V0, Lite-V1, Lite-V2 i Lite-V4, z których każdy jest uproszczoną wersją splotowej sieci neuronowej (CNN). Wszystkie cztery opierają się na tej samej podstawowej recepturze: stopniowo wydobywają cechy wizualne za pomocą stosu prostych bloków konstrukcyjnych, następnie podsumowują obraz i zwracają jedną z trzech etykiet tkanki płucnej. Różnice między wersjami dotyczą liczby bloków i ich szerokości — innymi słowy, ile pojemności ma model do nauki złożonych wzorców. Tak kontrolowany projekt pozwala zespołowi zbadać, ile złożoności jest naprawdę potrzebne do wiarygodnej klasyfikacji nowotworów.
Trenowanie, testowanie i wybór najuczciwszego modelu
Aby nauczyć i przetestować te modele, autorzy zebrali zrównoważony zbiór 15 000 obrazów tkanek płucnych, starannie podzielony na grupy treningowe, walidacyjne i testowe z równą liczbą obrazów dla każdej klasy. Przed trenowaniem każdy obraz jest skalowany, normalizowany i delikatnie augmentowany przez odbicia, niewielkie obroty i przybliżenia, aby naśladować różne warunki, w jakich mogą wyglądać preparaty. Co istotne, zespół nie ocenia modeli wyłącznie na podstawie surowej dokładności, ponieważ ta metryka może ukrywać słabe wyniki dla jednej klasy. Zamiast tego polegają na wskaźniku „macro-F1”, który zmusza model do dobrego radzenia sobie ze wszystkimi trzema typami tkanek, a nie tylko z najłatwiejszymi. Niestandardowa procedura trenowania ciągle monitoruje ten zrównoważony wynik i automatycznie przerywa trening, gdy poprawy ustają, zachowując najlepszą wersję każdego modelu do porównań. 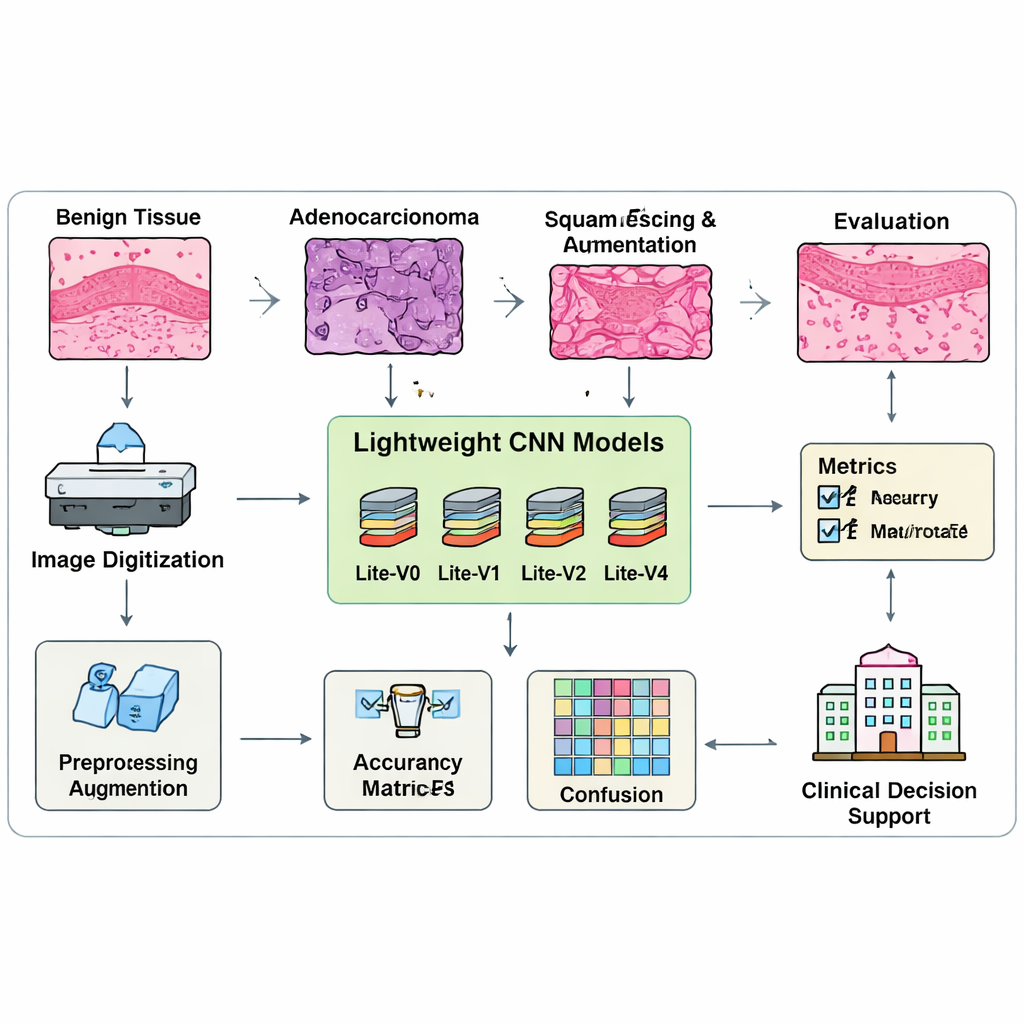
Co naprawdę potrafi najlepszy lekki model
Po zakończeniu eksperymentów jedna wersja — Lite-V2 — wyróżnia się. Nie jest to najmniejsza ani największa sieć, lecz plasuje się pośrodku i osiąga najlepszą równowagę między dokładnością a wydajnością. Na niewidzianych wcześniej obrazach testowych Lite-V2 poprawnie klasyfikuje tkankę łagodną, gruczolakoraka i płaskonabłonkowego raka z wysoką i równomiernie rozłożoną skutecznością, osiągając wartość macro-F1 około 0,96. Macierze pomyłek pokazują, że rzadko myli trzy kategorie, podczas gdy głębsze wersje zaczynają „przeuczać się”, zapamiętując dane treningowe, ale tracąc wiarygodność na nowych przypadkach. Autorzy powtórzyli dodatkowo wielokrotnie uruchomienia Lite-V2 z różnymi losowymi punktami startowymi i zastosowali test statystyczny, aby potwierdzić, że jego przewaga nad innymi wariantami nie jest przypadkowa. 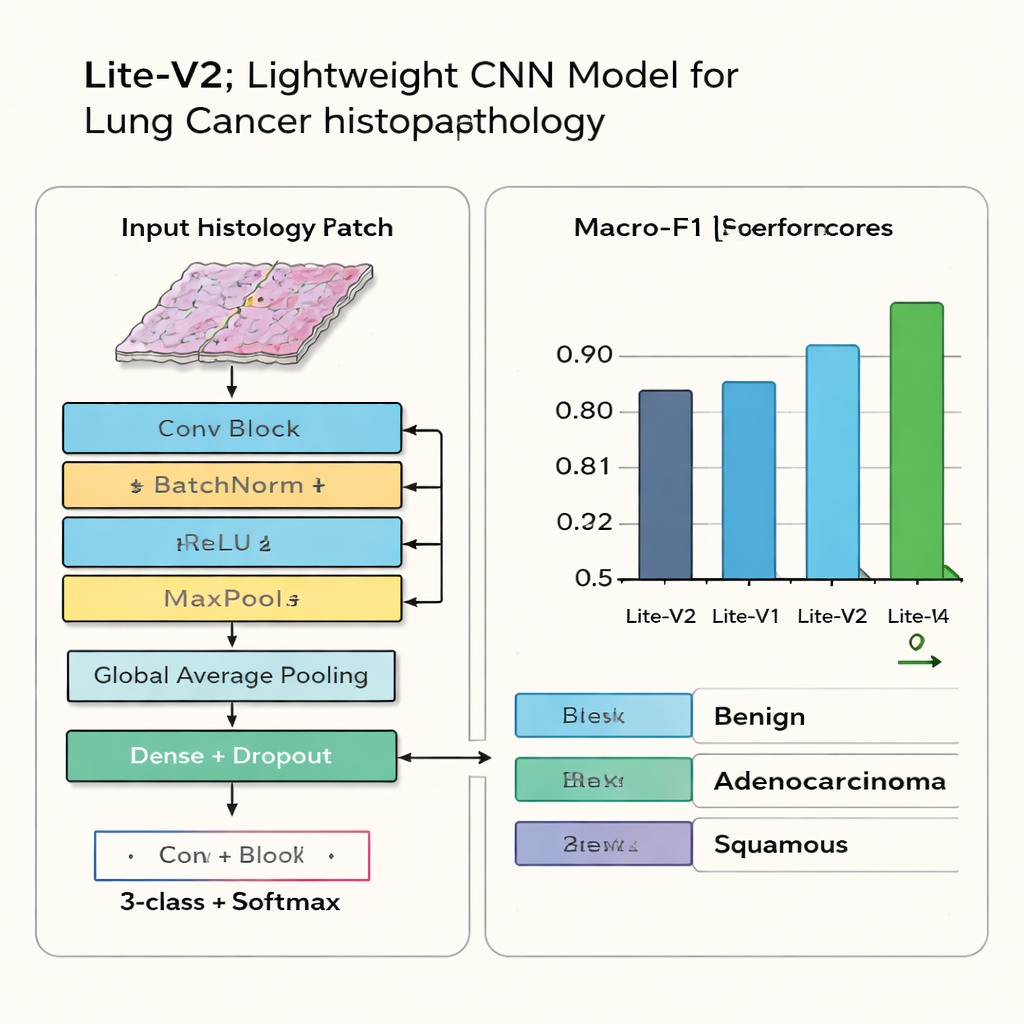
Z kodu badawczego do wsparcia w świecie rzeczywistym
Ponad liczby wydajności badanie podkreśla praktyczne wdrożenie. Ponieważ Lite-V2 i jego „rodzeństwo” są kompaktowe, mogą działać na skromnym sprzęcie szpitalnym lub nawet na urządzeniach brzegowych bez konieczności wysyłania wrażliwych obrazów do chmury. Autorzy publikują powtarzalne ramy eksperymentalne, które rejestrują każdy szczegół eksperymentu — od przetwarzania danych po krzywe treningowe i wzorce błędów — aby inne zespoły mogły zweryfikować lub rozszerzyć pracę. Dla pacjentów i klinicystów kluczowy wniosek jest taki, że przemyślanie zaprojektowana lekka sztuczna inteligencja może przybliżyć wiarygodną klasyfikację raka płuca do codziennej praktyki patologicznej, wspierając szybsze i bardziej spójne decyzje — nawet w klinikach pozbawionych najwyższej mocy obliczeniowej.
Cytowanie: Raza, A., Hanif, F. & Mohammed, H.A. Clinical validation of lightweight CNN architectures for reliable multi-class classification of lung cancer using histopathological imaging techniques. Sci Rep 16, 6512 (2026). https://doi.org/10.1038/s41598-026-36652-6
Słowa kluczowe: rak płuca, histopatologia, splotowe sieci neuronowe, AI w obrazowaniu medycznym, komputerowe wspomaganie diagnostyki