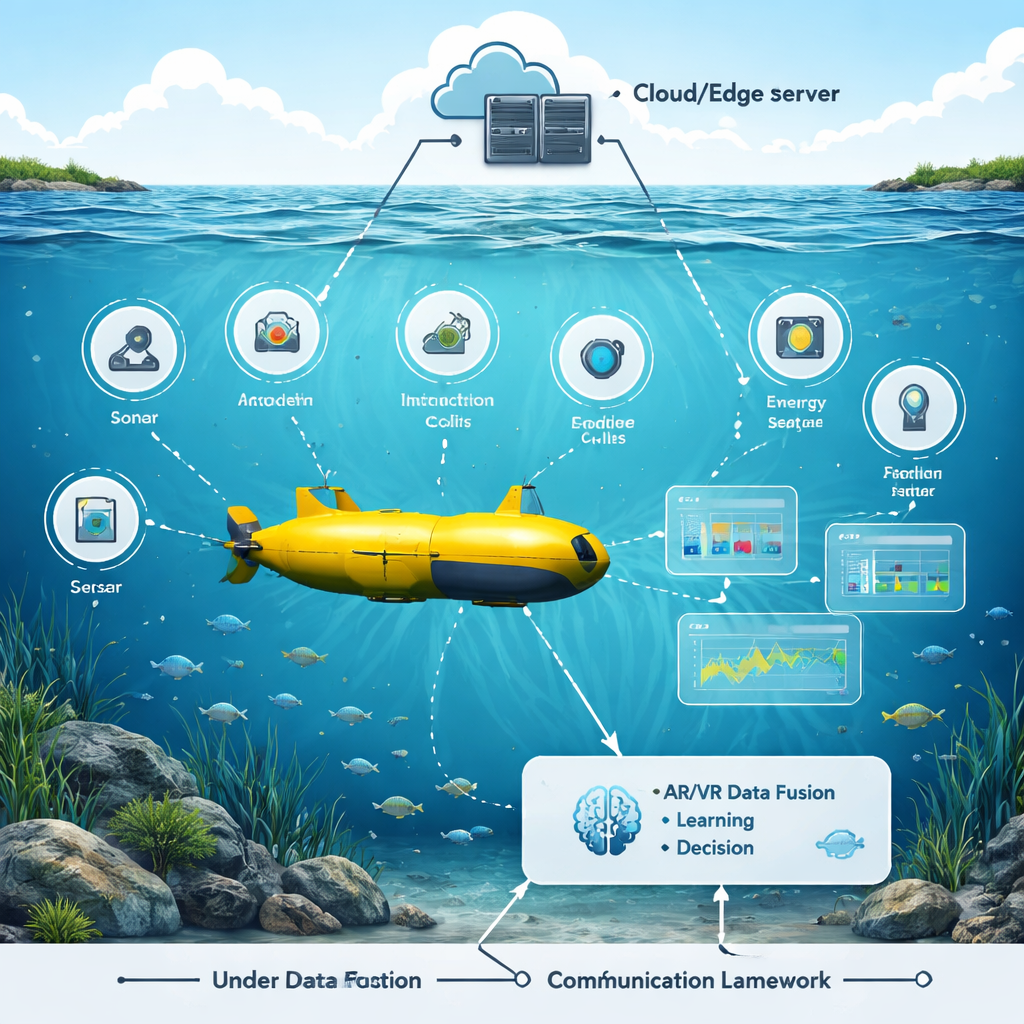
Na dnie morskim autonomiczne pojazdy podwodne pełnią rolę naszych oczu i uszu w badaniach klimatu, inspekcjach infrastruktury oraz akcjach poszukiwawczo-ratowniczych. Tymczasem te robotyczne okręty podwodne zmagają się z podstawowym problemem: komunikowaniem się i podejmowaniem decyzji w trudnym środowisku, gdzie sygnały są wolne, zaszumione, a energia—ograniczona. Artykuł przedstawia nowe podejście, które pomaga robotom podwodnym w komunikacji, wykrywaniu obiektów i zachowaniu bezpieczeństwa, łącząc rzeczywistość rozszerzoną i wirtualną z gałęzią sztucznej inteligencji zwaną uczeniem ze wzmocnieniem.
Dlaczego komunikacja pod wodą jest tak trudna
Wysyłanie danych pod wodą jest znacznie trudniejsze niż przez powietrze. Fale radiowe, które zasilałyby Wi‑Fi i 5G, są szybko tłumione przez wodę morską. Sygnały akustyczne (oparte na dźwięku) przemieszczają się dalej, ale oferują bardzo niskie szybkości przesyłu i mogą być opóźniane, odbijane lub zniekształcane. Indukcja magnetyczna działa jedynie na dystansach rzędu kilkudziesięciu metrów. Istniejące systemy sterowania dla robotów podwodnych często traktują te kanały oddzielnie i stosują stałe reguły nawigacji i pomiarów. Powoduje to wolne dostosowanie do zmiennych warunków, marnowanie energii baterii oraz pozostawianie łączy komunikacyjnych podatnych na podsłuch lub ataki.
Wirtualny ocean, by trenować lepsze instynkty Figure 1.
Autorzy zbudowali stanowisko testowe AR/VR odtwarzające zatłoczony świat podwodny: poruszające się ryby, skały, łodzie i boje, wraz z realistycznym szumem i tłumieniem sygnałów w wodzie. Symulowany pojazd podwodny przemieszcza się w tym środowisku, używając wielu czujników—sonaru, kamer, modemów akustycznych, mierników energii i lokalizatorów pozycji. W scenie wirtualnej badacze mogą suwakami zmieniać położenie obiektów, warunki wodne i ustawienia czujników, i natychmiast widzieć reakcję robota. Ta warstwa AR/VR to nie tylko wizualny dodatek; scala surowe strumienie danych z czujników w jednorodny obraz 3D, który jest łatwiejszy do zrozumienia i wykorzystania przez system AI.
Nauka robota poprzez doświadczenie
W sercu systemu znajduje się strategia AI, którą autorzy nazywają Adaptive Augmented Reality and Reinforcement Learning Scheduling Strategy (AARLSS). Zamiast działać według stałego skryptu, robot uczy się metodą prób i błędów w wirtualnym oceanie. W każdej chwili obserwuje scentralizowany stan czujników, wybiera akcję (na przykład zmianę kursu, dostosowanie częstotliwości próbkowania czujników lub przełączenie między łącznością krótkiego i długiego zasięgu) i otrzymuje nagrodę. Ta nagroda równoważy cztery cele: oszczędzanie energii, zmniejszanie opóźnień, obniżanie ryzyka bezpieczeństwa oraz ograniczanie użycia zasobów obliczeniowych i sieciowych. Głęboka sieć Q‑learning przechowuje i aktualizuje oczekiwaną wartość różnych decyzji, wykorzystując mini-partie z przeszłych doświadczeń zapisanych w pamięci odtwarzania, dzięki czemu robot uczy się zarówno z niedawnych, jak i starszych sytuacji.
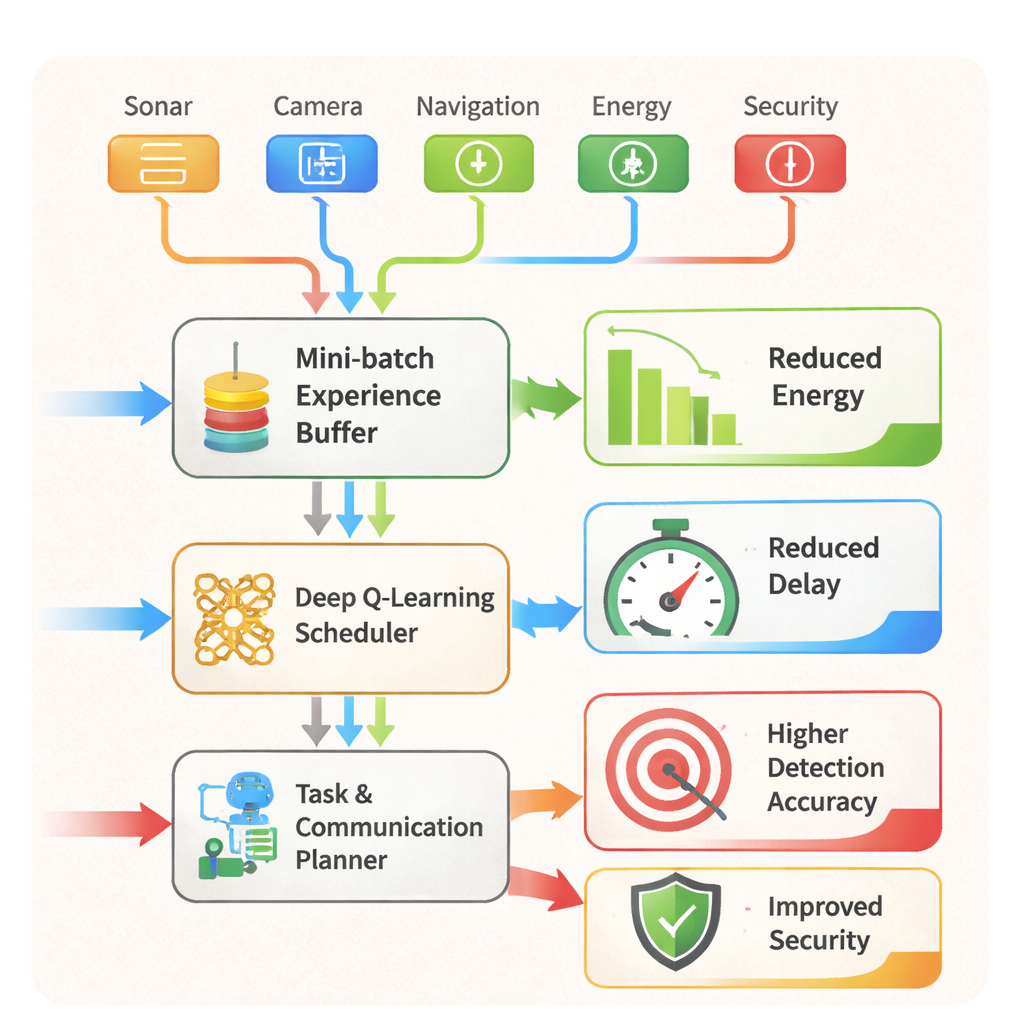
Od inteligentnego harmonogramowania do bezpieczniejszych misji Figure 2.
AARLSS pełni również rolę harmonogramu w czasie rzeczywistym. Decyduje, które zadania—nawigacja, wykrywanie obiektów, komunikacja czy kontrole bezpieczeństwa—powinny działać gdzie i kiedy, oraz czy dane mają być przetwarzane na pokładzie robota, zlecane na serwer brzegowy, czy opóźniane. Na to nakłada się wbudowany system wykrywania włamań, który nieustannie skanuje wzorce w danych z czujników i sieci, by wykrywać anomalie sugerujące atak lub awarię, i może uruchamiać działania ochronne, takie jak blokowanie ryzykownych łączy czy wymuszanie obliczeń lokalnych. W testach w symulatorze AR/VR system przewyższył kilka znanych metod uczenia ze wzmocnieniem. Zmniejszył zużycie energii pojazdu podwodnego o około 20%, skrócił opóźnienia w komunikacji i wykonywaniu zadań o około 18–20% oraz podniósł dokładność wykrywania obiektów do około 97–98%, nawet podczas złożonych manewrów i w zatłoczonych scenach.
Co to oznacza dla rzeczywistych mórz
Dla osób spoza branży kluczowy przekaz jest taki: badania te wskazują drogę do robotów podwodnych bardziej niezależnych, wydajnych i godnych zaufania. Trenując w bogatym wirtualnym oceanie i ucząc się jednoczesnego balansowania energią, czasem, dokładnością i bezpieczeństwem, AARLSS pozwala pojazdowi decydować, kiedy mówić, kiedy słuchać, a kiedy zachować ciszę, by oszczędzać energię—przy jednoczesnym uważnym obserwowaniu otoczenia i ochronie danych. Chociaż wyniki pochodzą z zaawansowanego symulatora, a nie z otwartego morza, sugerują, że przyszłe floty robotów podwodnych mogą realizować dłuższe, bezpieczniejsze i bogatsze w dane misje przy mniejszym nadzorze ludzi, poprawiając wszystko, od nauk o morzu po inspekcje przemysłu morskiego.
Cytowanie: Lakhan, A., Mohammed, M.A., Ghani, M.K.A. et al. A novel augmented reality and reinforcement learning empowered communication framework for underwater unmanned autonomous vehicle.
Sci Rep16, 6241 (2026). https://doi.org/10.1038/s41598-026-36647-3
Słowa kluczowe: robotyka podwodna, autonomiczne pojazdy podwodne, uczenie ze wzmocnieniem, rzeczywistość rozszerzona, komunikacja podwodna