Clear Sky Science · pl
Inteligentne rozpoznawanie zachowań uczniów dla inteligentnych środowisk nauczania
Dlaczego mądrzejsze klasy muszą widzieć, co robią uczniowie
W wielu klasach nauczyciele muszą zgadywać, kto nadąża, kto jest zagubiony, a kto potajemnie nie wykonuje zadania. W artykule badano, jak sztuczna inteligencja może automatycznie rozpoznawać, co robią uczniowie — na przykład czy czytają, piszą czy podnoszą rękę — na podstawie zwykłych zdjęć z klasy. Przekształcając surowe obrazy w wiarygodne miary aktywności, system ma na celu dostarczać nauczycielom informację zwrotną o zaangażowaniu w czasie rzeczywistym, bez polegania na czasochłonnych obserwacjach lub inwazyjnym monitorowaniu.
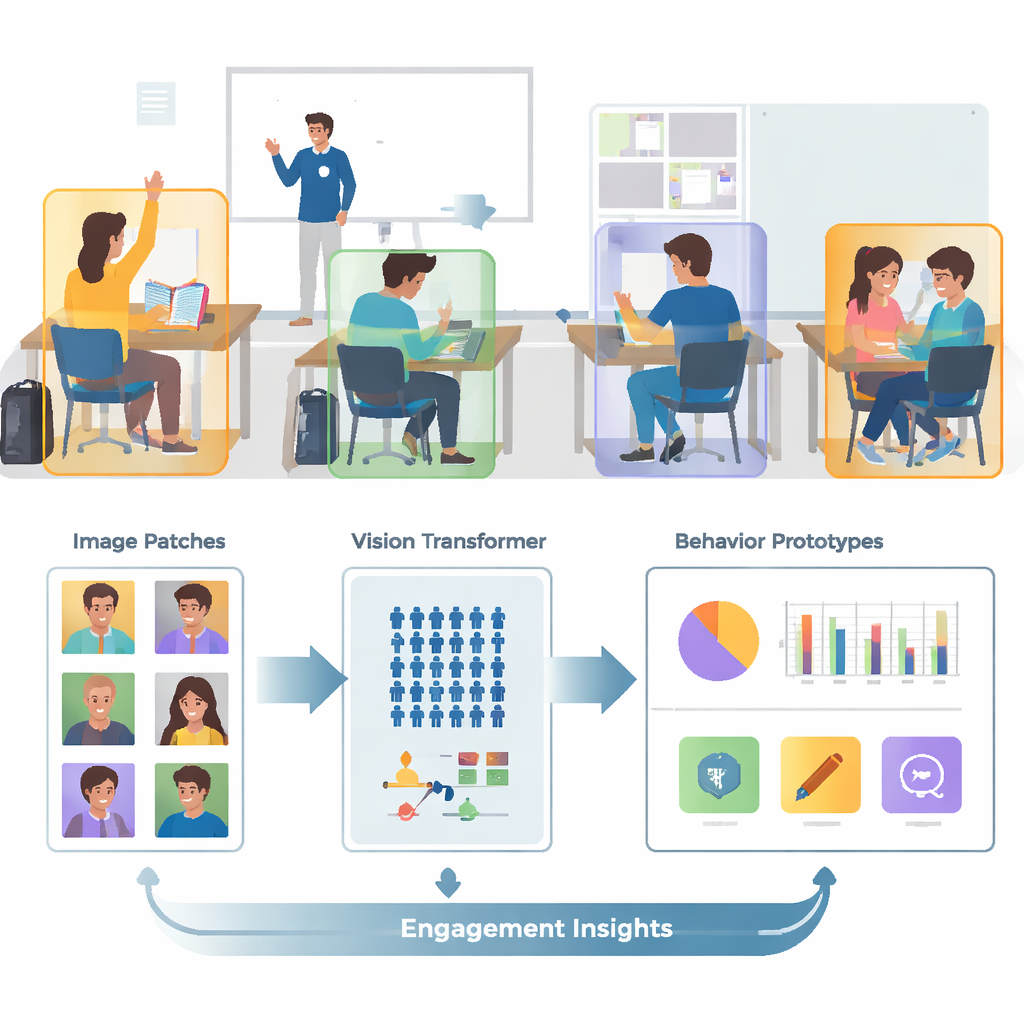
Od chaotycznych zdjęć do skoncentrowanych ujęć
Prawdziwe klasy są zatłoczone, zajęte i wizualnie mylące. Jedno zdjęcie może zawierać dziesiątki uczniów, nachodzące na siebie sylwetki i rozpraszające tło — ściany, ekrany, plakaty. Autorzy korzystają z publicznego zbioru obrazów o nazwie SCB‑05, który zawiera tysiące zdjęć klas oznaczonych konkretnymi zachowaniami — takimi jak podnoszenie ręki, czytanie, pisanie, stanie, rozmowa czy interakcja przy tablicy. Zamiast podawać całe sceny do modelu, system najpierw używa plików adnotacji, aby wyciąć regiony wokół każdego ucznia lub nauczyciela. Ten krok wstępnego przetwarzania usuwa dużą część wizualnego bałaganu, dzięki czemu model może skupić się na postawie, położeniu rąk i innych wskazówkach rozróżniających poszczególne zachowania.
Jak SI uczy się nowych zachowań na bardzo niewielu przykładach
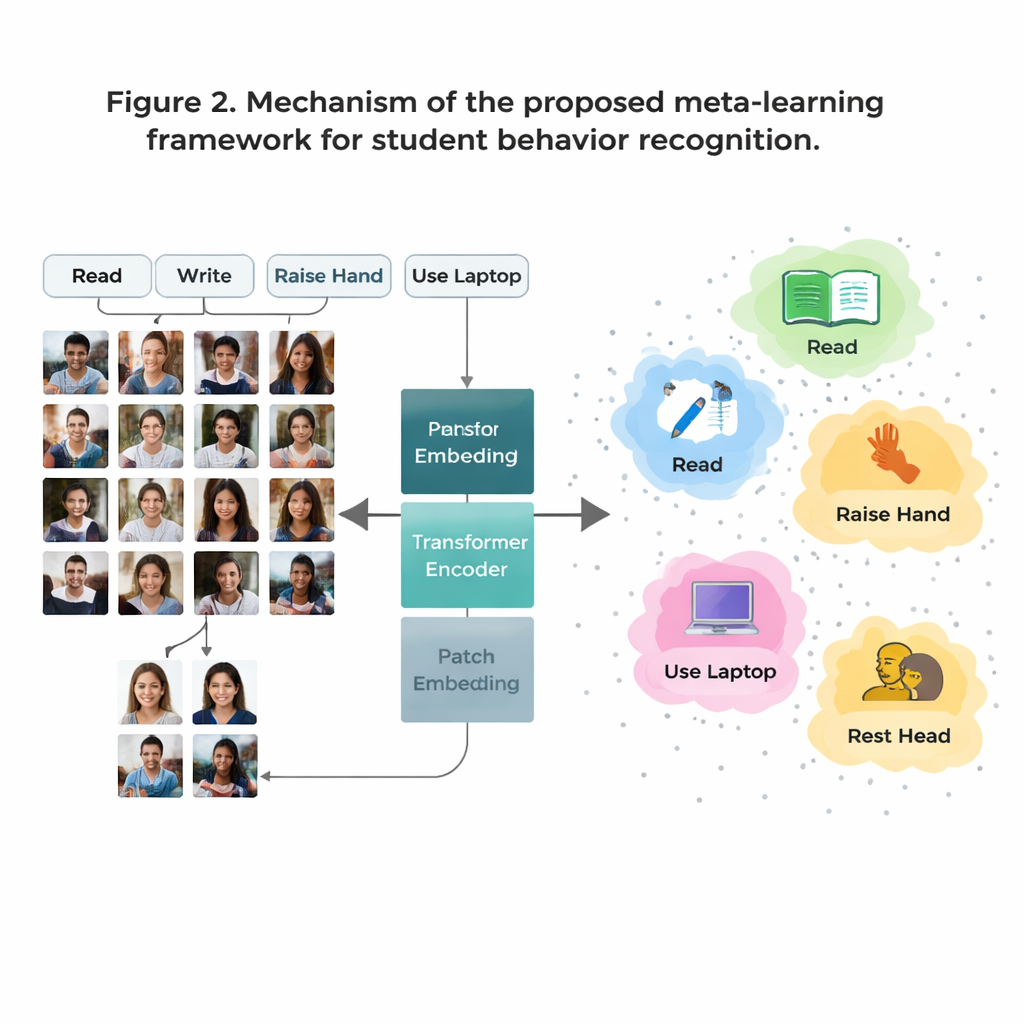
Główną przeszkodą jest to, że niektóre zachowania w klasie są powszechne w danych (np. czytanie), podczas gdy inne występują rzadko (np. krótkie interakcje na scenie). Zgromadzenie wystarczającej liczby oznaczonych zdjęć dla każdego możliwego zachowania jest kosztowne i rodzi obawy dotyczące prywatności. Aby temu zaradzić, autorzy stosują strategię zwaną „uczeniem przy niewielu przykładach” (few‑shot learning), w której model jest trenowany do rozpoznawania nowych klas na podstawie zaledwie kilku przykładów. Szkolenie organizowane jest jako wiele małych zadań, z których każde zawiera tylko kilka zachowań i kilka przykładowych obrazów dla każdego zachowania. Dla każdego zadania system tworzy prosty „prototyp” dla danego zachowania, uśredniając wewnętrzne reprezentacje tych przykładów. Nowe obrazy klasyfikuje się, sprawdzając, do którego prototypu są najbliższe, co pozwala modelowi szybko adaptować się nawet przy ograniczonych danych.
Widzieć całą klasę, nie tylko drobne szczegóły
Tradycyjne systemy obrazowe zwane splotowymi sieciami neuronowymi (CNN) mają tendencję do koncentrowania się na małych lokalnych wzorcach, jak krawędzie czy faktury. To może być ograniczające, gdy dwa zachowania, na przykład czytanie i pisanie, wyglądają bardzo podobnie z bliska. W pracy tej autorzy zastępują te starsze sieci modelem Vision Transformer, który dzieli obraz na łatki i uczy się relacji między wszystkimi łatkami. Globalny widok pomaga systemowi zrozumieć subtelne różnice w postawie i długodystansowe wskazówki — na przykład zależność między podniesioną ręką a nauczycielem na przodzie sali. Zespół dodatkowo ulepsza model, trenując go tak, by przybliżał obrazy przedstawiające to samo zachowanie i oddalał obrazy myląco podobne, ale różne, ze szczególnym naciskiem na trudne, mylące przypadki. Dzięki temu wewnętrzna mapa zachowań staje się czystsza i łatwiejsza do rozdzielenia.
Jak dobrze to działa i dlaczego ma to znaczenie
Na benchmarku SCB‑05 proponowana metoda osiąga około 91% trafności ogólnej oraz wysokie wyniki w bardziej wymagających miarach uwzględniających niezrównoważone dane. Powszechne zachowania, takie jak czytanie czy podnoszenie ręki, są rozpoznawane szczególnie dobrze, podczas gdy rzadsze działania, takie jak pisanie przy tablicy, pozostają trudniejsze, ale nadal wypadają lepiej niż w poprzednich systemach. Wizualne inspekcje wewnętrznych klastrów modelu pokazują, że różne zachowania tworzą zwarte, dobrze odseparowane grupy, co świadczy o tym, że SI nauczyła się odrębnych „sygnatur” działań w klasie. Testy na innym zbiorze danych z różnymi kątami kamer i układami sali wykazały jedynie niewielki spadek wydajności, co sugeruje, że wyuczona reprezentacja nie jest związana z jedną konkretną salą czy szkołą.
Co to oznacza dla nauczania i uczenia się
Mówiąc prościej, badanie pokazuje, że komputery potrafią wiarygodnie wykrywać wiele kluczowych zachowań uczniów ze zdjęć, nawet jeśli widziały tylko kilka przykładów każdego z nich. Zamiast zastępować nauczycieli, takie systemy mogłyby dyskretnie podsumowywać, kto jest zaangażowany, kto często szuka pomocy, czy które aktywności tracą uwagę — i to wszystko bez śledzenia tożsamości uczniów. Przy dalszej pracy nad prywatnością, uczciwością i analizą wideo w czasie rzeczywistym, tego rodzaju SI świadoma zachowań mogłaby stać się potężnym sprzymierzeńcem dla pedagogów projektujących bardziej responsywne i inkluzywne środowiska nauczania.
Cytowanie: Abozeid, A., Alrashdi, I. & Al-Makhlasawy, R.M. Intelligent recognition of students’ behavior for smart learning environments. Sci Rep 16, 5674 (2026). https://doi.org/10.1038/s41598-026-36633-9
Słowa kluczowe: inteligentna klasa, zachowanie ucznia, widzenie komputerowe, uczenie przy niewielu przykładach, vision transformer