Clear Sky Science · pl
Super‑rozdzielczość obrazów teledetekcyjnych w dowolnej skali między domenami poprzez uczenie wag meta
Bardziej ostre widoki z kosmosu
Obrazy satelitarne napędzają wszystko, od planowania miast po reagowanie na katastrofy, ale wiele z nich jest bardziej rozmytych niż byśmy chcieli z powodu ograniczeń sprzętu kamer i transmisji danych. W pracy tej przedstawiono nowy sposób przekształcania zamazanych zdjęć satelitarnych w ostrzejsze przy dowolnie wybranym poziomie powiększenia, wykorzystujący strategię uczenia, która potrafi dostosować się do specyfiki obrazów lotniczych bez konieczności ponownego trenowania dla każdej sytuacji.
Dlaczego ostrzejsze obrazy satelitarne są ważne
Obrazy teledetekcyjne o wysokiej rozdzielczości są kluczowe do wykrywania drobnych obiektów, śledzenia zmian na terenie oraz szczegółowego mapowania użytkowania ziemi. Jednak w rzeczywistości satelity muszą godzić rozdzielczość z kosztami, rozmiarem czujnika i przepustowością, więc wiele obrazów trafia w niższej jakości, niż by analitycy oczekiwali. Tradycyjne techniki „super‑rozdzielczości” potrafią wyostrzyć obrazy, ale zwykle są trenowane pod stały współczynnik powiększenia, na przykład dokładnie dwa lub cztery razy większy. Oznacza to, że operatorzy potrzebują oddzielnych modeli dla każdego poziomu powiększenia, co jest nieefektywne i mało elastyczne przy obsłudze wielu satelitów i różnorodnych zadań.
Ponad uniwersalnym powiększeniem
Najnowsze badania opracowały „super‑rozdzielczość o ciągłej skali”, która traktuje obraz jako gładki sygnał i potrafi generować ostre wyniki przy dowolnym współczynniku powiększenia za pomocą pojedynczego modelu. Większość z tych metod powstała i była testowana na zwykłych zdjęciach, a nie danych satelitarnych. Zwykle decydują one, jak mieszać informacje z pobliskich pikseli, używając stałych reguł geometrycznych — w praktyce ważenia są oparte na odległości. Działa to całkiem dobrze dla scen naturalnych, takich jak twarze czy krajobrazy, ale obrazy satelitarne zawierają gęste zabudowania, powtarzalne tekstury i nagłe krawędzie, które nie podążają za tymi samymi wzorcami. Gdy modele trenowane na zdjęciach naturalnych stosuje się do widoków satelitarnych, ich założenia zawodzą, a detale takie jak dachy, drogi czy pojazdy nie są odtwarzane wiernie.
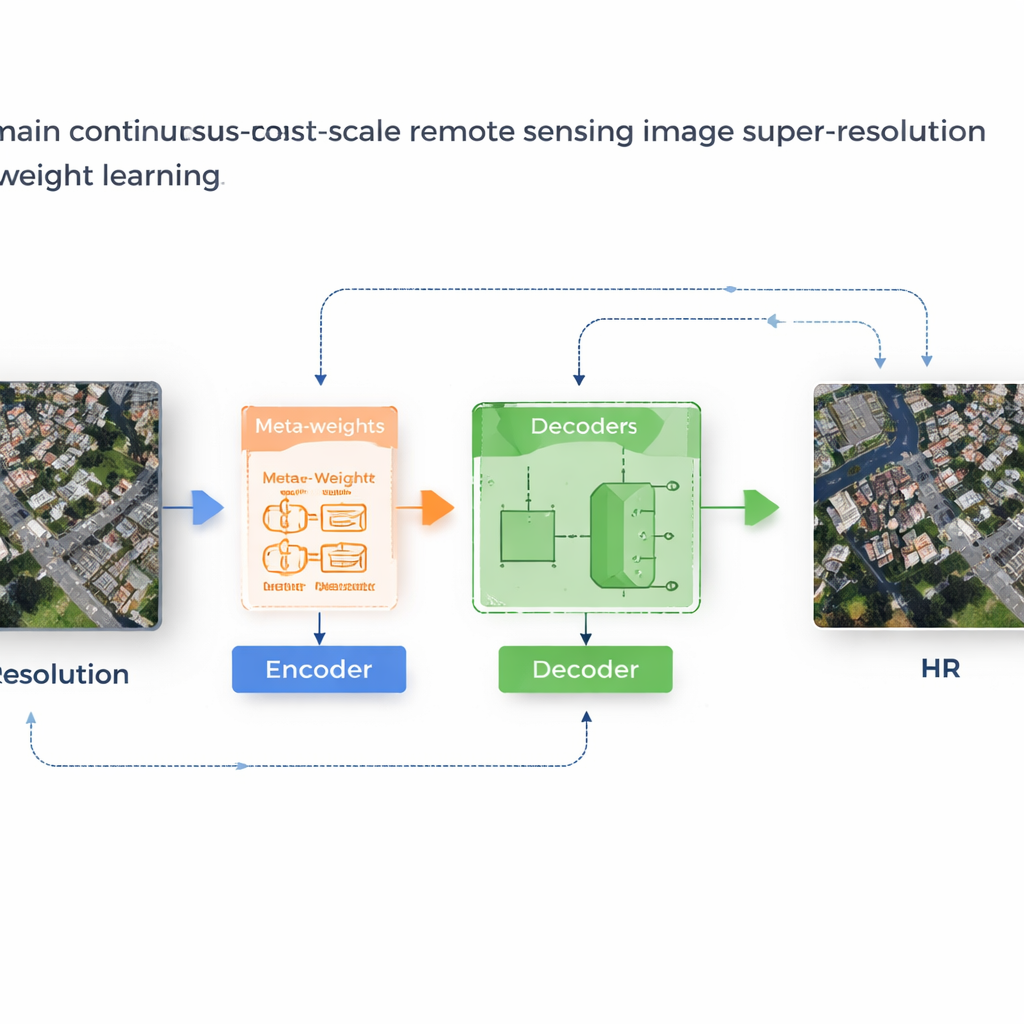
System uczący się własnych reguł
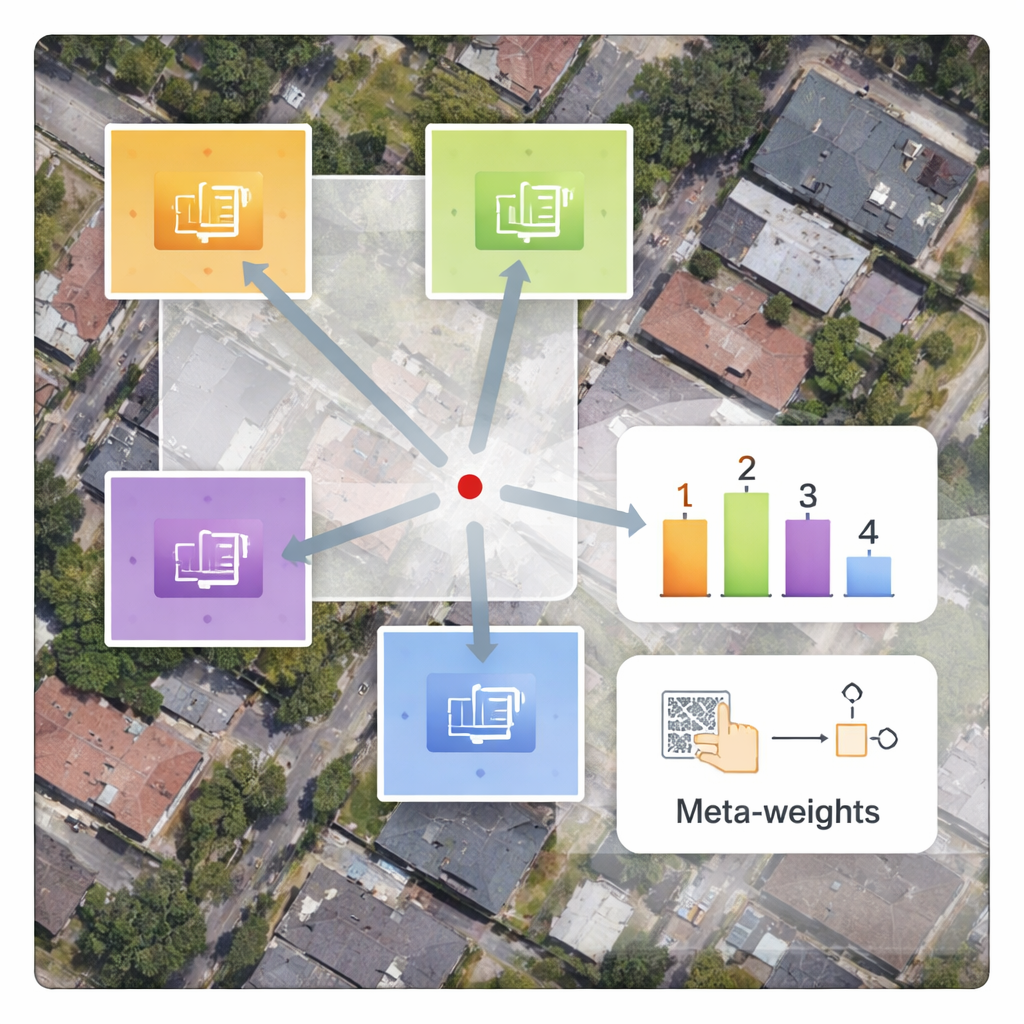
Autorzy proponują ramę nazwaną MLIN (Meta‑Learning‑based Implicit Neural Network) do rozwiązania tego problemu międzydomenowego. Zamiast ręcznie określać, jak należy łączyć cechy pobliskich pikseli, MLIN uczy się tych reguł łączenia z danych. Zachowuje silny enkoder obrazów, który został pierwotnie wytrenowany na zdjęciach naturalnych, całkowicie zamrożony, dzięki czemu nadal może wydobywać bogate wzorce wizualne bez zniekształcania ich przez mniejsze zbiory satelitarne. Na to nakłada się nowy „implicit decoder” wyposażony w moduł meta‑uczenia. Dla każdego punktu w obrazie o wysokiej rozdzielczości, który model ma odtworzyć, moduł ten analizuje otaczające cechy i ich dokładne pozycje, a następnie przewiduje zestaw miękkich wag, które mówią dekoderowi, jak silnie wykorzystać każdego sąsiada. Innymi słowy, system przestaje zakładać, że liczy się tylko odległość; pozwala lokalnej zawartości — takim jak tekstury dachów, pól czy wody — kształtować rekonstrukcję.
Z rozmytych bloków do wyraźnych struktur
Technicznie metoda działa poprzez próbkowanie małego 2×2 sąsiedztwa ukrytych cech wokół każdego docelowego położenia w obrazie wyjściowym. Meta‑sieć łączy następnie informacje o tych cechach, ich względnych współrzędnych oraz żądanym współczynniku powiększenia, aby wybrać wagi sumujące się do jedności. Dekoder wykorzystuje te wagi do mieszania predykcji z każdego sąsiada, wytwarzając końcową wartość koloru w tym miejscu. Ponieważ ważenia są uczone, MLIN może traktować złożone rejony — jak gęste osiedla mieszkaniowe, porty ze statkami czy lotniska z pasami startowymi — bardzo inaczej niż gładkie obszary, takie jak pustynie czy oceany. Eksperymenty na dwóch szeroko używanych zbiorach satelitarnych (WHU‑RS19 i UCMerced) wykazują, że MLIN konsekwentnie dostarcza wyższe wyniki liczbowej jakości i wizualnie ostrzejsze detale niż kilka wiodących metod ciągłego powiększenia, zarówno dla znanych poziomów powiększenia, jak i ekstremalnych powiększeń dochodzących do dziesięciokrotności.
Szybsze trenowanie bez dodatkowych opóźnień
Praktyczną zaletą projektu jest to, że trenowanymi na obrazach satelitarnych są tylko nowy dekoder i sieć meta‑wag, podczas gdy duży enkoder pozostaje stały. To znacznie skraca czas treningu w porównaniu z metodami, które uczą wszystkie parametry od podstaw. Chociaż meta‑sieć wprowadza dodatkowe obliczenia, nowoczesne procesory graficzne radzą sobie z takimi operacjami efektywnie, więc czas przetwarzania pojedynczego obrazu pozostaje niemal taki sam jak w podejściach istniejących. Badania ablacyjne — staranne testy, w których części systemu są usuwane lub upraszczane — potwierdzają, że ważenie świadome zawartości jest kluczowym składnikiem poprawiającym zarówno ostrość krawędzi, jak i ciągłość tekstur.
Wyraźniejsze oczy Ziemi
Mówiąc prosto, praca ta pokazuje, jak ponownie wykorzystać potężne modele obrazów trenowane na codziennych zdjęciach i sprytnie dostosować je do bardzo innego świata obrazów satelitarnych. Pozwalając systemowi nauczyć się, jak równoważyć informacje z pobliskich pikseli w oparciu o to, co faktycznie znajduje się w scenie, MLIN produkuje wyraźniejsze, bardziej wiarygodne obrazy satelitarne na dowolnym poziomie powiększenia z użyciem jednego modelu. To oznacza lepsze narzędzia dla naukowców, planistów i służb ratunkowych, które polegają na szczegółowych widokach naszej planety, przy jednoczesnym utrzymaniu umiarkowanych wymagań obliczeniowych i pamięciowych.
Cytowanie: Zhang, Q., Ma, S., Tang, Y. et al. Cross-domain continuous-scale remote sensing image super-resolution via meta-weight learning. Sci Rep 16, 6073 (2026). https://doi.org/10.1038/s41598-026-36632-w
Słowa kluczowe: super‑rozdzielczość satelitarna, obrazy teledetekcyjne, meta‑uczenie, zoom o dowolnej skali, ulepszanie obrazu