Clear Sky Science · pl
Szczegółowa ocena dużych modeli językowych w medycynie z użyciem nieparametrycznego modelowania diagnostycznego poznawczego
Dlaczego to ma znaczenie dla przyszłych wizyt u lekarza
Systemy sztucznej inteligencji, które mówią i piszą, znane jako duże modele językowe, szybko przechodzą z laboratoriów badawczych do szpitali. Potrafią już pomagać lekarzom w analizie skomplikowanych wykresów, sugerować leczenie i odpowiadać na pytania medyczne. Jednak większość testów tych systemów daje tylko jedną ogólną ocenę, podobną do oceny końcowej, co może ukrywać niebezpieczne luki. To badanie pokazuje nowy sposób wniknięcia w te wyniki i ujawnienia, które obszary medycyny modele naprawdę rozumieją — i gdzie nadal mogą zagrażać pacjentom.
Wyjście poza pojedynczy wynik testu
Obecnie większość systemów medycznych AI ocenia się po tym, ile pytań poprawnie odpowiadają na egzaminach wzorowanych na testach licencyjnych dla lekarzy. Podejście to jest proste, lecz prymitywne. Model może uzyskać wysoki wynik ogólny, a jednocześnie mieć słabość w krytycznej dziedzinie, takiej jak analiza rytmu serca czy choroby wątroby. W rzeczywistej klinice takie luki mogą mieć konsekwencje śmiertelne. Autorzy argumentują, że bezpieczne użycie AI w medycynie wymaga głębszej, bardziej szczegółowej oceny — takiej, która potrafi zmapować profil umiejętności zamiast wystawiać jedną, potencjalnie mylącą ocenę.

Inteligentniejszy sposób testowania wiedzy medycznej
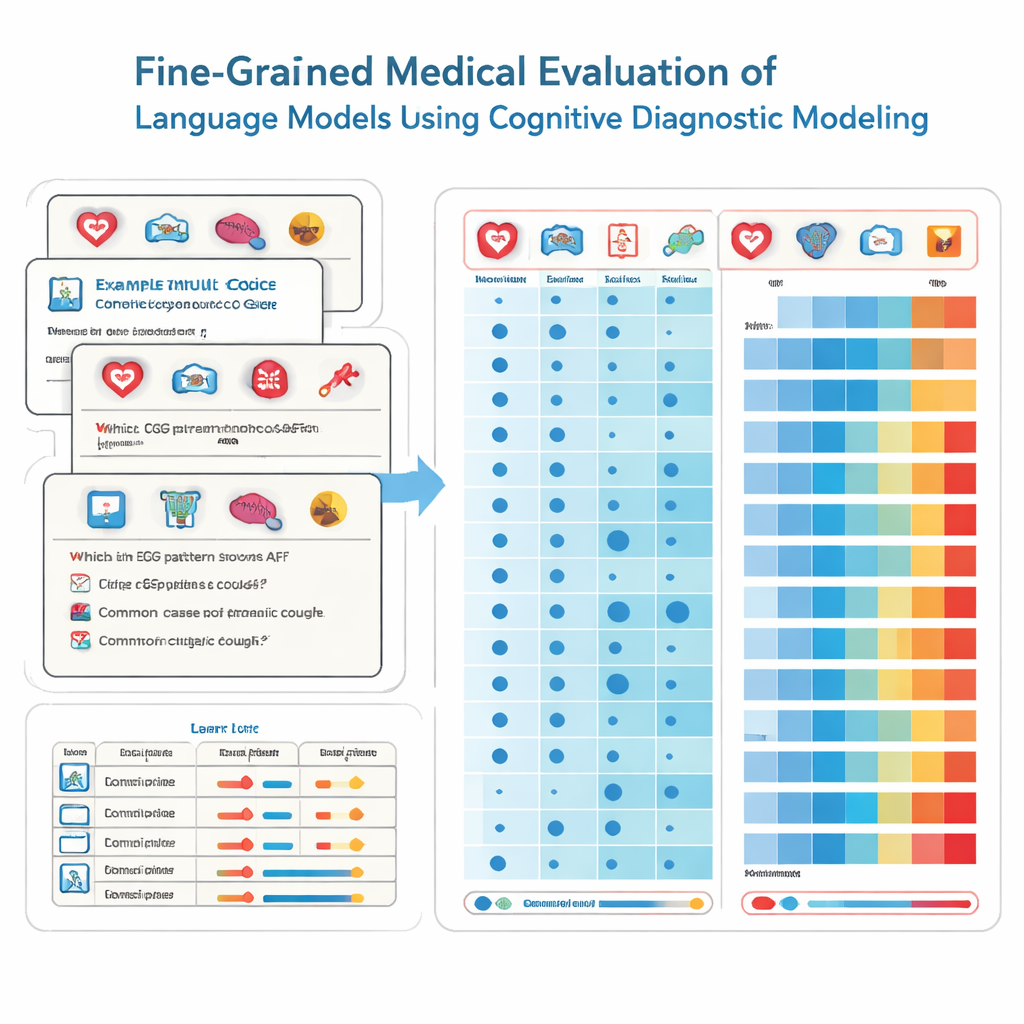
Aby to osiągnąć, badacze zapożyczają narzędzia z psychologii edukacyjnej zwane diagnostyką poznawczą. Zamiast traktować każde pytanie egzaminacyjne tak, jakby mierzyło tę samą ogólną zdolność, metoda ta rozbija wiedzę medyczną na konkretne elementy budulcowe, takie jak kardiologia, radiologia czy opieka ratunkowa. Każde pytanie wielokrotnego wyboru jest oznaczone dokładnym zestawem wymaganych umiejętności. Korzystając z nieparametrycznej techniki statystycznej, zespół porównuje, jak model odpowiada na tysiące takich pytań z wzorcami idealnych odpowiedzi. Na tej podstawie wnioskują, czy model „opanował” każdą z podstawowych umiejętności, podobnie jak szczegółowe świadectwo szkolne może pokazać silne i słabe strony w poszczególnych przedmiotach.
Test 41 modeli AI na egzaminie medycznym
Zespół przetestował 41 szeroko stosowanych modeli językowych, w tym systemy komercyjne i otwartoźródłowe, na 2809 starannie zweryfikowanych pytaniach pochodzących z chińskiej krajowej bazy pytań medycznych. Pytania te obejmują 22 poddziedziny medycyny i są przeznaczone dla studentów przystępujących do egzaminu licencyjnego na lekarza. Każde pytanie ma jedną poprawną odpowiedź i jest oznaczone przez ekspertów, wskazując, które specjalności obejmuje. Korzystając z ich metody diagnostycznej, badacze oszacowali dla każdego modelu, ile z tych 22 atrybutów medycznych model faktycznie opanował, a nie tylko ile pytań przypadkowo odpowiedział poprawnie.
Silna wiedza ogólna, lecz ostre luki
Wyniki są jednocześnie imponujące i niepokojące. Modele o najlepszych wynikach, takie jak kilka czołowych systemów komercyjnych, odpowiadały poprawnie na większość pytań i wykazały opanowanie 20 z 22 dziedzin medycznych. Wśród wszystkich modeli wydajność była doskonała w wielu powszechnych specjalnościach, osiągając pełne opanowanie w 15 obszarach, w tym kardiologii, dermatologii i endokrynologii. Jednak analiza o wysokiej rozdzielczości ujawniła wyraźne luki w innych dziedzinach. Radiologia pozostawała w tyle z dużo niższymi wskaźnikami opanowania, a dwa podobszary — EKG & nadciśnienie & lipidologia oraz choroby wątroby — nie zostały opanowane przez żaden model. Co ważne, niektóre mniejsze modele wykazywały te same opanowane umiejętności co dużo większe, co pokazuje, że sama wielkość nie gwarantuje szerokiej, niezawodnej wiedzy medycznej.
Wybór właściwego narzędzia do właściwego zadania
Te szczegółowe profile mają znaczenie, ponieważ modele o bardzo podobnych wynikach ogólnych mogą mieć bardzo różne wzorce mocnych i słabych stron. Jeden system może być silny w neurologii, a słaby w farmakologii, podczas gdy inny wykazuje odwrotny wzorzec. Dla kierownictwa szpitali oznacza to, że nie można bezpiecznie wybierać asystenta AI wyłącznie na podstawie jego głównego wyniku egzaminu czy liczby parametrów. Zamiast tego potrzebne są wyniki diagnostyczne, takie jak w tym badaniu, aby dopasować każdy model do konkretnych zadań klinicznych oraz zaprojektować procedury, w których specjaliści-ludzie weryfikują wyjścia AI w obszarach wysokiego ryzyka, gdzie model jest znany z słabości.
Co to oznacza dla pacjentów i klinicystów
Mówiąc prosto, badanie konkluduje, że wysoka „ocena” na testach medycznych nie gwarantuje, że system AI jest bezpieczny do użycia we wszystkich częściach medycyny. Nowe podejście działa bardziej jak dokładne badanie kontrolne samego AI, ujawniając, które „organy” — w tym przypadku specjalności medyczne — są zdrowe, a które wymagają uwagi. Poprzez odkrycie ukrytych luk w krytycznych obszarach, takich jak interpretacja EKG i choroby wątroby, metoda daje szpitalom, regulatorom i deweloperom praktyczną mapę działania: używać modeli tylko tam, gdzie dowiedziono ich siły, utrzymywać ludzi w obiegu tam, gdzie pozostają słabości, i ukierunkować przyszłe treningi na najbardziej ryzykowne luki. Tego rodzaju szczegółowa ocena — jak twierdzą autorzy — nie jest tylko pożyteczna, lecz niezbędna przed powierzeniem opieki nad pacjentem AI.
Cytowanie: Zheng, T., Liu, J., Feng, S. et al. Fine-grained evaluation of large language models in medicine using non-parametric cognitive diagnostic modeling. Sci Rep 16, 6460 (2026). https://doi.org/10.1038/s41598-026-36627-7
Słowa kluczowe: sztuczna inteligencja medyczna, duże modele językowe, bezpieczeństwo kliniczne, ocena modelu, testy diagnostyczne