Clear Sky Science · pl
Optymalizacja wielozadaniowa i stabilność zbieżności z hierarchicznym uczeniem cech dla samonaprowadzonej optymalizacji
Mądrzejsza sztuczna inteligencja, która potrafi jednocześnie wykonywać wiele zadań
Nowoczesne aplikacje coraz częściej polegają na sztucznej inteligencji, która musi robić kilka rzeczy jednocześnie — na przykład rozumieć obrazy i tekst razem, wspierać decyzje medyczne lub pomagać samochodom postrzegać drogę. Jednak gdy jeden model AI uczy się zbyt wielu umiejętności naraz, trening może stać się niestabilny, a umiejętności zaczynają wzajemnie na siebie wpływać. W artykule wprowadzono nową ramę uczenia głębokiego, nazwaną Unified Multitask and Multiview Deep Architecture (UMDA), zaprojektowaną tak, aby jeden model mógł uczyć się z wielu typów danych i rozwiązywać wiele zadań bez zamętu i niestabilności.
Dlaczego wielozadaniowe AI często ma trudności
Większość obecnych systemów uczących się kilku zadań (uczenie wielozadaniowe) lub łączących kilka źródeł danych, takich jak obrazy i tekst (uczenie wielowidokowe), cierpi na trzy poważne problemy. Po pierwsze, różne zadania mogą ze sobą konkurować podczas treningu: poprawa wyników w jednym zadaniu może po cichu zaszkodzić innemu — problem znany jako negatywny transfer. Po drugie, zwykłe łączenie lub uśrednianie informacji z różnych źródeł często powoduje utratę subtelnych, lecz ważnych zależności między nimi. Po trzecie, sam proces treningu może stać się chwiejny, z dużymi wahaniami kierunku aktualizacji parametrów modelu. Problemy te są szczególnie poważne w zastosowaniach rzeczywistych, takich jak diagnostyka medyczna czy inspekcja przemysłowa, gdzie dane są złożone, a decyzje muszą być wiarygodne.
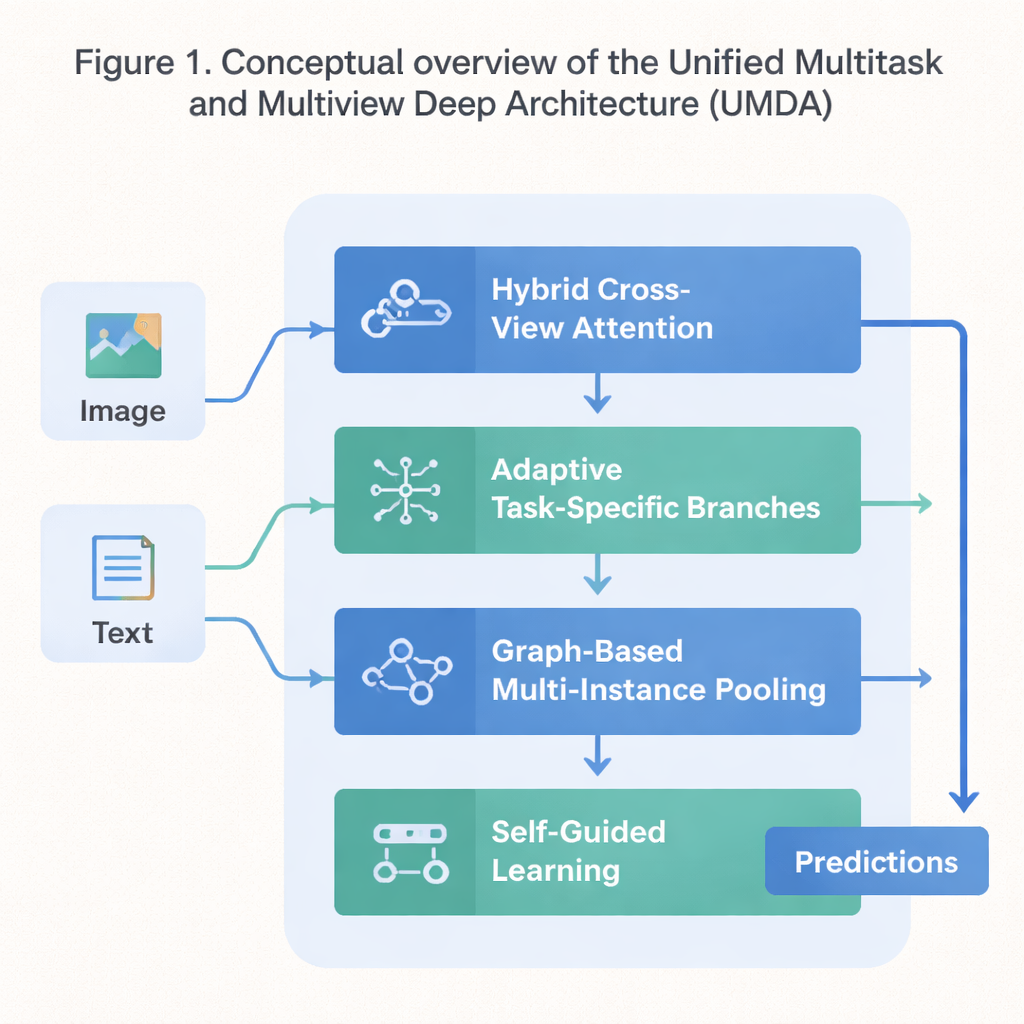
Czteroczęściowy plan dla współpracującego uczenia
UMDA przeciwdziała tym słabościom, dzieląc proces uczenia na cztery ściśle powiązane części, które wymieniają informacje w kontrolowany sposób. Pierwsza część, nazwana Hybrydową Uwagą Międzywidokową (Hybrid Cross‑View Attention), analizuje różne widoki tych samych danych — na przykład tekst i obrazy opisujące film — i uczy, który widok powinien wpływać na inny na każdym etapie. Wykorzystuje narzędzia matematyczne, które zachęcają model do unikania nadmiernego polegania na jednym widoku, do utrzymywania odrębności poszczególnych widoków, a jednocześnie do utrzymania ich ogólnej zgodności. Innymi słowy, uczy model, by słuchał wszystkich swoich „zmysłów” bez pozwalania jednemu zagłuszyć pozostałe.
Zachowanie odrębności zadań przy jednoczesnej współpracy
Druga część, Adaptacyjne Rozgałęzianie Specyficzne dla Zadań (Adaptive Task‑Specific Branching), oddziela wiedzę ogólną dzieloną przez wiele zadań od specjalistycznej wiedzy potrzebnej każdemu zadaniu osobno. Zamiast zmuszać wszystkie zadania do korzystania dokładnie z tych samych cech, UMDA buduje oddzielne „gałęzie” dla każdego zadania, które nadal mogą się komunikować przez starannie ważone połączenia. Dodatkowe terminy karne w funkcji celu treningowego nakłaniają te gałęzie do tego, by różniły się wystarczająco, by się specjalizować, ale nie tak bardzo, by przestały współpracować. Ta równowaga pomaga zmniejszyć szkodliwe interferencje między zadaniami, zachowując jednocześnie korzyści płynące z wzajemnego uczenia się.
Dostrzeganie struktury w zbiorach przykładów
Wiele rzeczywistych zbiorów danych występuje jako kolekcje powiązanych elementów — na przykład wiele wycinków obrazu z jednej szkiełka medycznego lub wiele klatek z wideo. Trzecia część UMDA, nazwana Opartym na Grafie Warstwowaniem Wieloinstancyjnym (Graph‑Based Multi‑Instance Pooling), jawnie modeluje relacje między tymi elementami, traktując je jako węzły w sieci. Łączy podobne elementy, pozwala informacji przepływać wzdłuż tych połączeń, a następnie podsumowuje całą kolekcję do jednej zwartej reprezentacji. Dodatkowa regularyzacja skłania pobliskie elementy do zgody między sobą, przy zachowaniu wystarczającej różnorodności, co pozwala modelowi wychwycić strukturalne wzorce, które proste uśrednianie by pominęło.
Samooptymalizujący się trening dla równomiernego postępu
Ostatnia część, Samonaprowadzone Uczenie (Self‑Guided Learning), koncentruje się na sposobie treningu modelu, a nie na jego wewnętrznej strukturze. Ciągle mierzy, jak silne i jak podobne są sygnały treningowe każdego zadania, a następnie automatycznie dostosowuje tempo uczenia dla każdego zadania. Wygładza i przeważa też gradienty — sygnały mówiące modelowi, jak się zmieniać — tak, aby zadania o podobnych celach wzmacniały się wzajemnie, a zadania ciągnące w bardzo różnych kierunkach nie destabilizowały treningu. W testach na standardowym zbiorze mieszającym streszczenia filmów i plakaty UMDA osiągnęła wyższą średnią dokładność niż kilkanaście zaawansowanych konkurencyjnych metod, utrzymała bardziej spójną relację między widokami i zmniejszyła kluczowy miernik niestabilności treningu o ponad połowę.
Co to oznacza dla systemów AI w rzeczywistości
Dla osób niebędących specjalistami kluczowa wiadomość jest taka, że UMDA oferuje sposób budowy pojedynczych modeli AI, które mogą bardziej niezawodnie obsługiwać wiele typów danych i celów. Ucząc model, kiedy dzielić się informacją, a kiedy ją zachować odrębnie, oraz pozwalając mu automatycznie dostroić sposób uczenia, rama dostarcza lepsze przewidywania, spójniejsze wewnętrzne reprezentacje i płynniejszy trening. Dzięki temu stanowi obiecujący element konstrukcyjny przyszłych systemów w medycynie, prowadzeniu autonomicznym i innych złożonych zastosowaniach, w których AI musi interpretować wiele sygnałów jednocześnie, nie tracąc równowagi.
Cytowanie: Mahmood, K., Althobaiti, M.M., Hassan, M.U. et al. Multitask optimization and convergence stability with hierarchical feature learning for self guided optimization. Sci Rep 16, 6414 (2026). https://doi.org/10.1038/s41598-026-36622-y
Słowa kluczowe: uczenie wielozadaniowe, AI multimodalna, stabilność uczenia głębokiego, sieci uwagi, grafowe sieci neuronowe