Clear Sky Science · pl
Hybrydowy model ResNet50-vision transformer z mechanizmem uwagi do klasyfikacji zdjęć lotniczych
Dlaczego inteligentniejsze „oczy w niebie” mają znaczenie
Zdjęcia lotnicze z dronów i satelitów dziś wspierają działania ratunkowe, planowanie miast, rolnictwo, a nawet zarządzanie ruchem. Jednak nauczenie komputerów rozumienia tych złożonych, zatłoczonych widoków z góry wciąż jest trudne. W niniejszym badaniu przedstawiono dwa nowe modele sztucznej inteligencji, które łączą różne sposoby „widzenia” obrazów, by rozpoznawać dziesięć typów obiektów na zdjęciach z dronów — takich jak budynki, samochody, drzewa i drogi — z lepszą dokładnością niż wcześniejsze metody. Podejście to może sprawić, że zautomatyzowany monitoring z powietrza będzie szybszy, bardziej niezawodny i łatwiejszy do wdrożenia w praktyce.
Wyzwania patrzenia z góry
Zdjęcia lotnicze różnią się od codziennych fotografii, które robimy telefonem. Obiekty są mniejsze, mogą występować pod nietypowymi kątami i często są ciasno skupione. Samochód częściowo zasłonięty przez drzewo, wąska ścieżka lub hałdy gruzu po osuwisku mogą być trudne do szybkiego zauważenia nawet dla ludzi. Tymczasem rządy, zespoły ratunkowe i agencje środowiskowe coraz częściej polegają na danych z dronów i satelitów do monitorowania powodzi, pożarów, rozrostu miast i uszkodzeń infrastruktury. Przy tysiącach satelitów na orbicie i rosnącym rynku obrazowania lotniczego wolumen danych zwiększa się szybciej, niż ludzie są w stanie je ręcznie przejrzeć, co napędza potrzebę dokładniejszej i wydajniejszej automatycznej klasyfikacji.
Mieszanie dwóch sposobów, w jaki maszyny uczą się widzieć
Większość skutecznych dziś systemów rozpoznawania obrazów opiera się na uczeniu głębokim. Jedna rodzina, sieci konwolucyjne, świetnie radzi sobie z wyłapywaniem lokalnych wzorców, takich jak krawędzie, tekstury i małe kształty. Druga, nowsza rodzina zwana vision transformerami traktuje obraz jak sekwencję pakietów i szczególnie dobrze uchwytuje związki na dłuższych dystansach — na przykład jak droga, zespół dachów i pobliskie pole współgrają w scenie. W tej pracy połączono oba podejścia: dobrze znany model konwolucyjny ResNet-50 oraz vision transformera. Każdy z nich przetwarza to samo zdjęcie lotnicze i wydobywa własny zestaw cech numerycznych — zwarte podsumowania tego, czego sieć nauczyła się o scenie. Te dwa strumienie informacji są następnie łączone i przekazywane do modułu „uwagi”, który uczy się, które cechy są najistotniejsze przy rozróżnianiu dziesięciu docelowych klas.
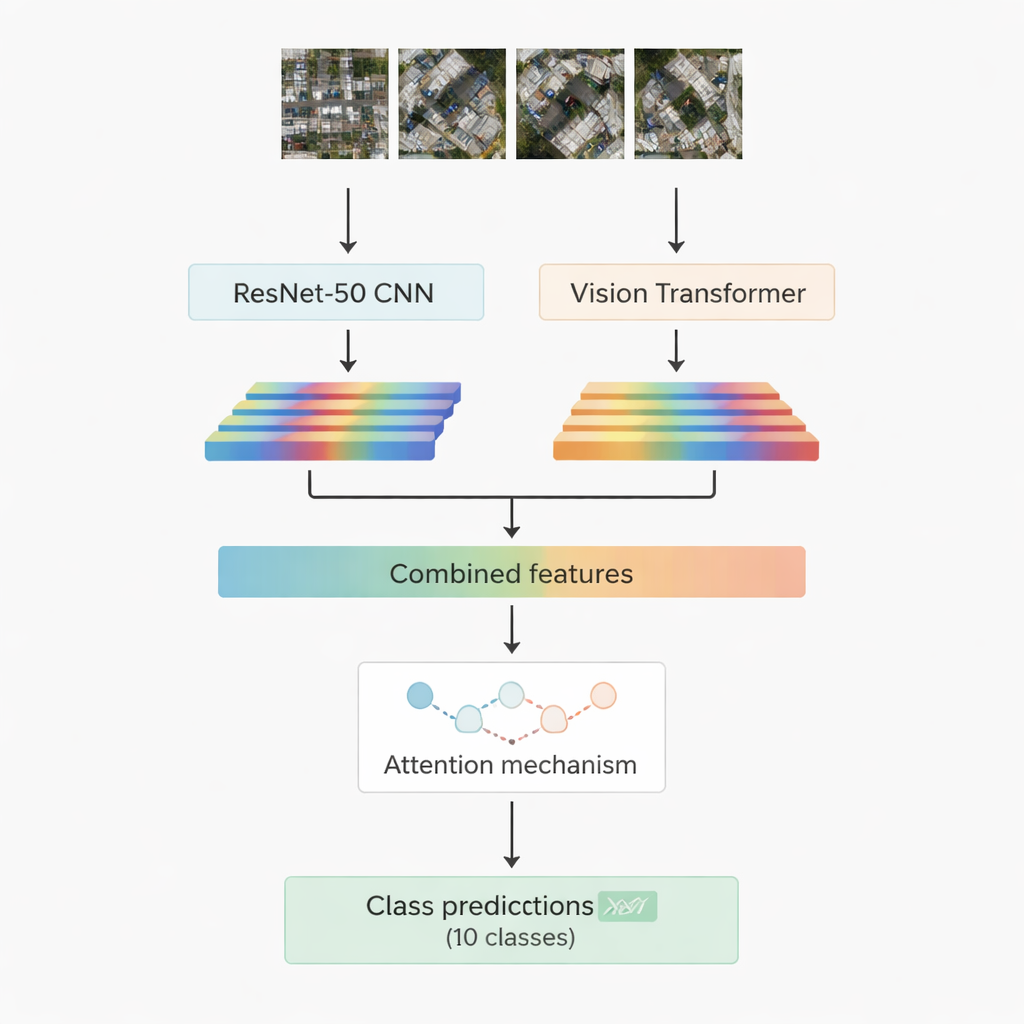
Dwie strategie uwagi, by skupić się na tym, co ważne
Badacze zaprojektowali i przetestowali dwie wersje hybrydowego systemu. W pierwszej po prostu łączą cechy z ResNet-50 i transformera i podają je do modułu multi-head attention. Ten mechanizm można sobie wyobrazić jako wiele małych reflektorów, z których każdy patrzy na cechy pod nieco innym kątem, a następnie łączy swoje ustalenia. W drugiej wersji stosują attention krzyżowy (cross-attention): cechy z sieci konwolucyjnej pełnią rolę zapytania, które pyta cechy transformera, gdzie patrzeć, pozwalając jednemu strumieniowi kierować drugim. W obu przypadkach wynik uwagi przechodzi przez standardowe warstwy, które ostatecznie przypisują fragment obrazu do jednej z dziesięciu klas, w tym: budynki, samochody, gruz, ścieżki, metalowe drogi, otwarte pola, cienie, zbiorniki (tanki), drzewa i dachy.
Testy na rzeczywistych zdjęciach z dronów
Aby ocenić skuteczność swoich modeli, autorzy wykorzystują publiczny zestaw danych ze stanu Sikkim w Indiach, zebrany przez drona latającego na wysokości 60–120 metrów nad ziemią. Dane obejmują rzeki, lasy, wzgórza i tereny zabudowane, podzielone na małe fragmenty tak, by każdy obraz należał do jednej z dziesięciu kategorii. Zbiór jest zrównoważony, z równą liczbą obrazów treningowych i testowych w każdej klasie, co czyni go uczciwym polem testowym. Badacze trenują obie hybrydowe wersje w identycznych warunkach, a następnie porównują ich wydajność za pomocą powszechnie stosowanych miar: dokładności (accuracy), precyzji, recall, F1-score, macierzy pomyłek i krzywych ROC. Porównują też swoje wyniki z kilkoma znanymi sieciami i nowszymi metodami opartymi na transformerach z literatury.

Ostrość klasyfikacji i potencjał praktyczny
Oba modele hybrydowe przewyższają wcześniejsze systemy na tym zbiorze, osiągając ogólną dokładność odpowiednio 95,52% i 95,80%, z nieznacznie lepszą wersją z multi-head attention. Ich wydajność pozostaje silna i stabilna w odniesieniu do wszystkich dziesięciu typów obiektów, a szczegółowe analizy pokazują, że nawet słabsze klasy są rozpoznawane na wysokim poziomie. To sugeruje, że mieszanka sieci konwolucyjnych, vision transformerów i mechanizmów uwagi to silna recepta na rozumienie złożonych scen lotniczych. Dla czytelnika popularnonaukowego najważniejsze jest to, że komputery coraz lepiej odpowiadają na pytania typu „Gdzie są drogi?” lub „Które fragmenty przedstawiają gruz lub budynki?” w ogromnych zbiorach zdjęć z dronów. W miarę jak takie modele będą udoskonalane i stosowane do nowych zbiorów danych, mogą stać się podstawą inteligentniejszej reakcji na katastrofy, monitoringu środowiskowego i usług smart-city opartych na szybkim, niezawodnym rozpoznawaniu obrazów z powietrza.
Cytowanie: Aboghanem, A., Abd Elfattah, M., M. Amer, H. et al. A hybrid ResNet50-vision transformer model with an attention mechanism for aerial image classification. Sci Rep 16, 5940 (2026). https://doi.org/10.1038/s41598-026-36492-4
Słowa kluczowe: klasyfikacja zdjęć lotniczych, obrazy z dronów, uczenie głębokie, vision transformer, teledetekcja