Clear Sky Science · pl
Analiza wydajności zoptymalizowanej, opartej na uwadze kaskadowej sieci shuffle z długoterminowymi zależnościami w adaptacyjnym e‑learningu wśród specjalistów IT
Inteligentniejsze szkolenia online dla pracujących specjalistów technologicznych
Dla wielu specjalistów z dziedziny technologii informacyjnych (IT) kursy online są dziś głównym sposobem aktualizowania umiejętności. Jednak większość platform szkoleniowych nadal ocenia uczestników za pomocą grubych narzędzi, takich jak sumy punktów z quizów czy odznaki ukończenia. W tym badaniu zaprezentowano inteligentniejszy sposób odczytywania cyfrowych „śladow” pozostawianych przez uczących się i przekształcania ich w precyzyjne, działa-jące w czasie rzeczywistym wnioski o rzeczywistym poziomie przyswajania wiedzy przez każdą osobę.
Dlaczego uniwersalne kursy online zawodzą
Tradycyjny e‑learning traktuje większość uczących się jednakowo: wszyscy widzą te same moduły, rozwiązują te same quizy i są oceniani według tych samych stałych testów. Takie podejście pomija to, jak różnie specjaliści się rozwijają, zwłaszcza w szybko zmieniających się dziedzinach, takich jak cyberbezpieczeństwo czy przetwarzanie w chmurze. Wcześniejsze prace próbowały naprawić to za pomocą uczenia maszynowego — łącząc wyniki quizów, czas spędzony i dane kliknięć, by przewidzieć sukces — ale wiele modeli miało problemy z hałaśliwymi lub niekompletnymi danymi, nie skalowało się do realistycznych platform lub nie potrafiło śledzić, jak nauka rozwija się w ciągu tygodni i miesięcy. W efekcie często powstawały opóźnione, grube informacje zwrotne, które trudno było wykorzystać do dostosowania treści lub szybkiej interwencji.
Przekształcanie surowych logów kursów w czyste, uczciwe dane
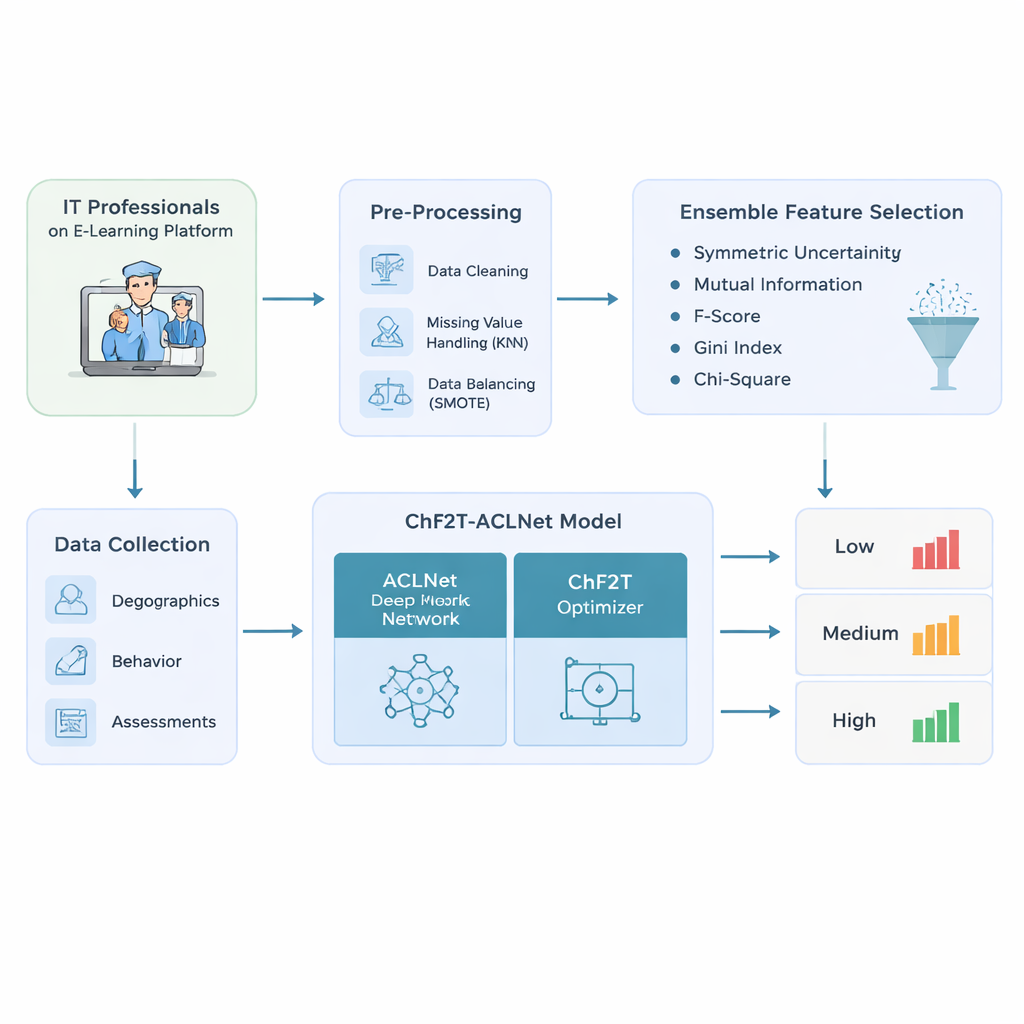
Autorzy zaczynają od zaprojektowania starannego potoku danych dla specjalistów IT korzystających z adaptacyjnych platform e‑learningowych. Zbierają bogatą mieszankę informacji: podstawowe dane profilowe, takie jak wiek i rola zawodowa; ślady behawioralne, jak czas spędzony, daty dostępu i aktywne dni; oraz wskaźniki wydajności, w tym wyniki quizów, próby, certyfikaty i oceny zwrotne. Przed jakimkolwiek modelowaniem dane są oczyszczane — usuwane są duplikaty, brakujące wartości szacowane na podstawie podobnych uczących się, a skośne rozkłady klas korygowane tak, by niskie, średnie i wysokie wyniki były reprezentowane bardziej równomiernie. Ten krok wyrównujący zapobiega tworzeniu modeli nadmiernie pewnych jedynie dla najczęstszych „przeciętnych” uczestników oraz niewrażliwych na tych, którzy mają trudności lub wyróżniają się wynikami.
Wybieranie tylko najbardziej wymownych sygnałów
Z oczyszczonego zestawu danych system nie po prostu wrzuca każdej dostępnej kolumny do czarnej skrzynki. Zamiast tego wykorzystuje zespół pięciu prostych metod rankingowych, by zdecydować, które cechy naprawdę mają znaczenie dla przewidywania wyników nauki. Każda metoda bada związek między rozważaną cechą — na przykład liczbą prób w quizie czy czasem spędzonym — a końcową etykietą wydajności. Łącząc ich rankingi za pomocą mediany, podejście filtruje hałaśliwe lub redundantne sygnały i zachowuje tylko te najbardziej informacyjne. To nie tylko zmniejsza nakład obliczeń potrzebnych później przez model, ale także pomaga mu skupić się na wzorcach, które istotnie rozróżniają słabych, średnich i osiągających wysokie wyniki.
Hybrydowa sieć trenowana jak drużyna sportowa
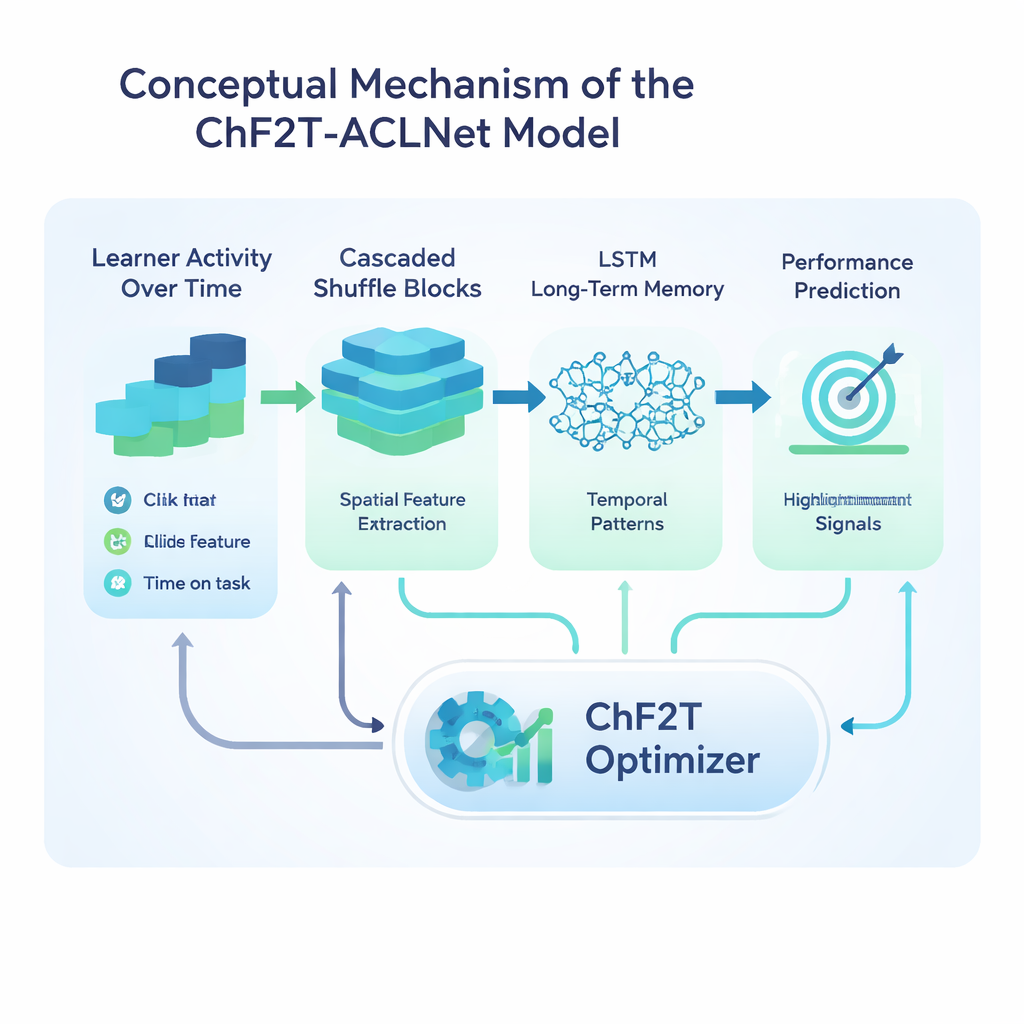
Rdzeniem badania jest hybrydowy model uczenia głębokiego o nazwie ACLNet, sparowany z niekonwencjonalną strategią treningową inspirowaną sportami drużynowymi. ACLNet najpierw używa lekkich bloków „shuffle”, by efektywnie skompresować i wymieszać sygnały wejściowe, a następnie przekazuje je do modułu pamięci śledzącego, jak zachowanie uczącego się zmienia się w czasie. Warstwa uwagi na szczycie wyróżnia najbardziej wpływowe kanały — takie jak nagłe spadki aktywności czy konsekwentnie wysokie wyniki quizów — zanim dokona końcowej prognozy klasy wydajności uczącego się. Aby dostroić wiele wewnętrznych ustawień tej sieci, autorzy wprowadzają algorytm Chaotic Football Team Training (ChF2T). Tutaj wirtualni „zawodnicy” eksplorują różne ustawienia parametrów, naśladując silnych wykonawców, unikając słabych, a od czasu do czasu wykonując duże, chaotyczne skoki, które pomagają wyszukiwaniu uciec z nieoptymalnych lokalnych rozwiązań. To połączenie struktury i kontrolowanego losu przyspiesza zbieżność i zmniejsza przeuczenie.
Jak system sprawdza się w praktyce
Badacze testują swój potok na syntetycznym, ale realistycznym zbiorze danych składającym się z 1200 specjalistów IT, stworzonym tak, by odzwierciedlać rzeczywiste zapisy systemów zarządzania nauką z celowo nierównymi rozkładami klas. Porównują swój model ChF2T‑ACLNet z kilkoma silnymi punktami odniesienia, w tym z ustawieniami uczenia zaufanego (federated learning), zaawansowanymi sieciami w stylu przetwarzania obrazów dostosowanymi do edukacji oraz innymi modelami głębokimi i zespołowymi. W wielu konfiguracjach walidacji krzyżowej proponowana metoda osiąga około 98,9% dokładności, z równie wysoką precyzją, czułością i miarami F. Osiąga również niemal doskonały współczynnik zgodności skorygowany o przypadek oraz wysokie wartości pola pod krzywą ROC, co oznacza, że niezawodnie rozdziela poziomy wydajności przy wielu progach. Pomimo złożoności system działa szybciej niż podejścia konkurencyjne, dzięki starannemu wyborowi cech, efektywnej konstrukcji sieci i szybkiemu zbieżeniu optymalizatora.
Co to oznacza dla codziennego uczenia się online
Mówiąc prościej, praca ta pokazuje, że można obserwować, jak specjaliści poruszają się po kursach online i z wysokim prawdopodobieństwem wywnioskować, kto ma trudności, kto przechodzi bez wyzwań, a kto opanowuje materiał — bez czekania na egzamin końcowy. Taki system mógłby uruchamiać wczesne wskazówki, polecać inne ćwiczenia lub ostrzegać mentorów długo zanim uczący się zacznie odstawać. Autorzy zauważają nadal istniejące wyzwania, w tym skalowanie do bardzo dużych platform, dostosowanie do szybko zmieniających się projektów kursów oraz ułatwienie wyjaśnialności decyzji modelu. Mimo to ich podejście stanowi mocny krok w kierunku systemów e‑learningowych, które zachowują się bardziej jak uważni trenerzy osobowi niż statyczne cyfrowe podręczniki.
Cytowanie: Yuvapriya, P., Subramanian, P. & Surendran, R. Optimized attention-based cascaded shuffle long-term dependent network based performance analysis of adaptive e-learning among IT professionals. Sci Rep 16, 6245 (2026). https://doi.org/10.1038/s41598-026-36470-w
Słowa kluczowe: adaptacyjny e‑learning, analiza nauczania, uczenie głębokie, szkolenie specjalistów IT, predykcja wyników uczniów