Clear Sky Science · pl
Metoda rozwiązywania niejednoznaczności krótkich tekstów oparta na modelu BERT i algorytmie najkrótszej ścieżki
Dlaczego wyjaśnianie mylących nazw ma znaczenie
Każdego dnia wyszukujemy, przeglądamy i rozmawiamy, używając krótkich, często chaotycznych fragmentów tekstu — tweetów, zapytań wyszukiwarki, wiadomości czatu. Te fragmenty zawierają nazwy osób, miejsc, firm i rzeczy, które mogą mieć więcej niż jedno znaczenie, jak „Apple” jako owoc lub „Apple” jako firma. Komputery muszą odgadnąć, które znaczenie mamy na myśli, a gdy się pomylą, wyniki wyszukiwania, rekomendacje i usługi online stają się znacznie mniej użyteczne. W artykule przedstawiono nowy sposób pomagający maszynom poprawnie interpretować takie niejednoznaczne nazwy w krótkich tekstach, zwłaszcza w chińskich mediach społecznościowych i zapytaniach, poprzez połączenie nowoczesnych modeli językowych z inteligentnym algorytmem grafowym.
Z chaotycznych krótkich tekstów do jasnych celów
Dla komputerów krótkie teksty są zaskakująco trudne do zrozumienia. W przeciwieństwie do długich artykułów zawierają bardzo mało kontekstu i są pełne slangu, skrótów i niekompletnych zdań. Tradycyjne metody próbowały dopasować nazwę z tekstu do wpisów w bazie wiedzy lub korzystały z ręcznie tworzonych reguł i prostszych modeli uczenia maszynowego. Podejścia te często traktują każde słowo jako mające jedno stałe znaczenie, co zawodzi, gdy to samo słowo może oznaczać tytuł zawodowy, firmę lub piosenkę, zależnie od użycia. Efektem jest częsta dezorientacja co do tego, do jakiej rzeczywistej encji odnosi się słowo w tweecie lub zapytaniu.
Nauczanie systemu rozpoznawania niejednoznacznych nazw
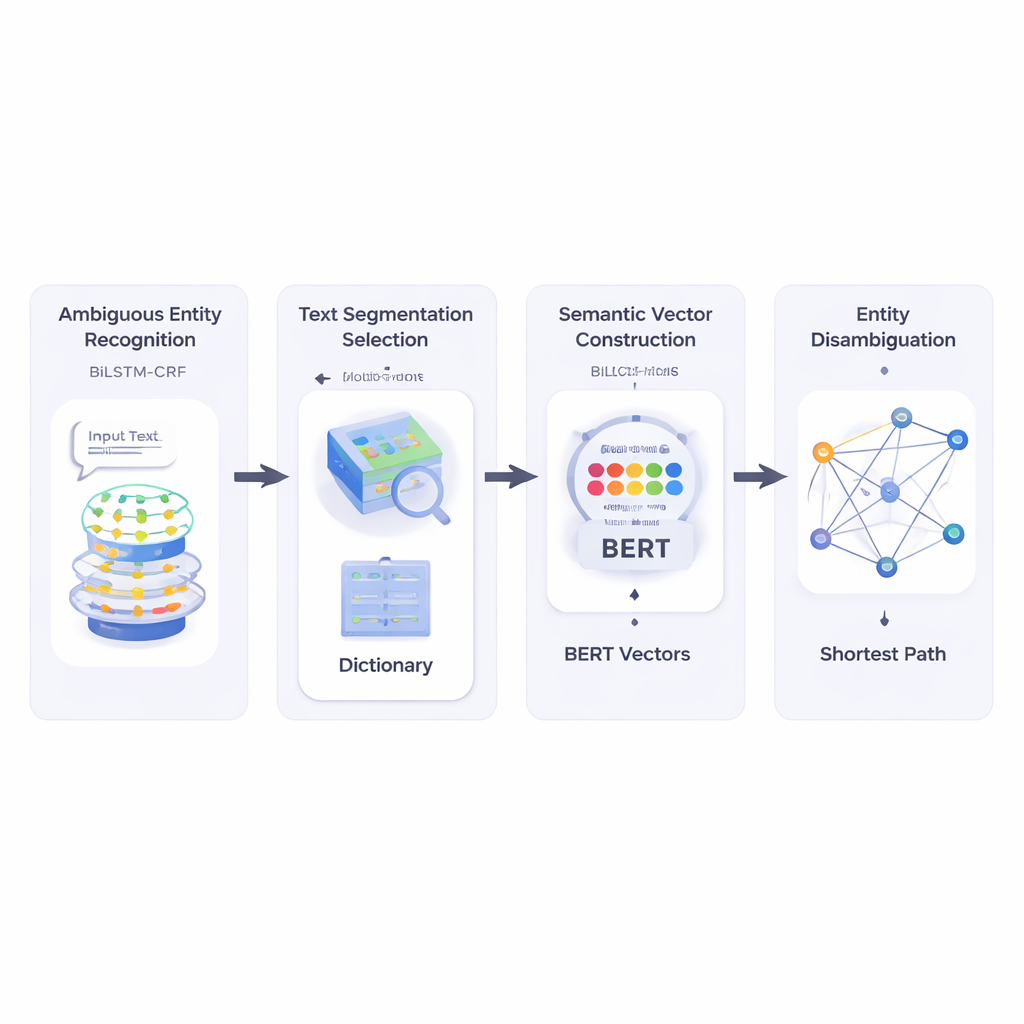
Autorzy najpierw budują system, który czyta krótki tekst i identyfikuje, które fragmenty są nazwami encji oraz które z nich mogą być niejednoznaczne. Używają kombinacji sieci neuronowych zwanej BiLSTM‑CRF, która dobrze nadaje się do etykietowania sekwencji słów, biorąc pod uwagę kontekst zarówno z lewej, jak i z prawej strony. Gdy potencjalne encje są oznaczone, system odwołuje się do dużego zasobu leksykalnego o nazwie HowNet. Jeśli HowNet podaje kilka znaczeń dla słowa, słowo to zostaje oznaczone jako niejednoznaczne; jeśli jest tylko jedno znaczenie, traktuje się je jako już jasne. Ten krok daje systemowi skoncentrowaną listę nazw, które rzeczywiście wymagają rozstrzygnięcia niejednoznaczności.
Przekształcanie znaczeń w punkty w przestrzeni
Następnie metoda dzieli krótki tekst na kandydackie segmenty słów i wybiera najlepszy podział, sprawdzając, jak dobrze każde możliwe cięcie zgadza się znaczeniowo z jasno zrozumiałymi słowami odniesienia w tym samym zdaniu. Do pomiaru tego autorzy polegają na BERT — potężnym uprzednio wytrenowanym modelu językowym, który generuje numeryczny „wektor semantyczny” dla każdego użycia słowa, uchwytując jego kontekstowo zależne znaczenie. Poprzez obliczanie podobieństwa kosinusowego między tymi wektorami, system znajduje segmentację, której części są najbardziej semantycznie zgodne z jednoznacznymi terminami odniesienia. Pozwala to modelowi reprezentować każde możliwe znaczenie każdego słowa jako punkt w wielowymiarowej przestrzeni.
Znajdowanie najkrótszej drogi do właściwego znaczenia
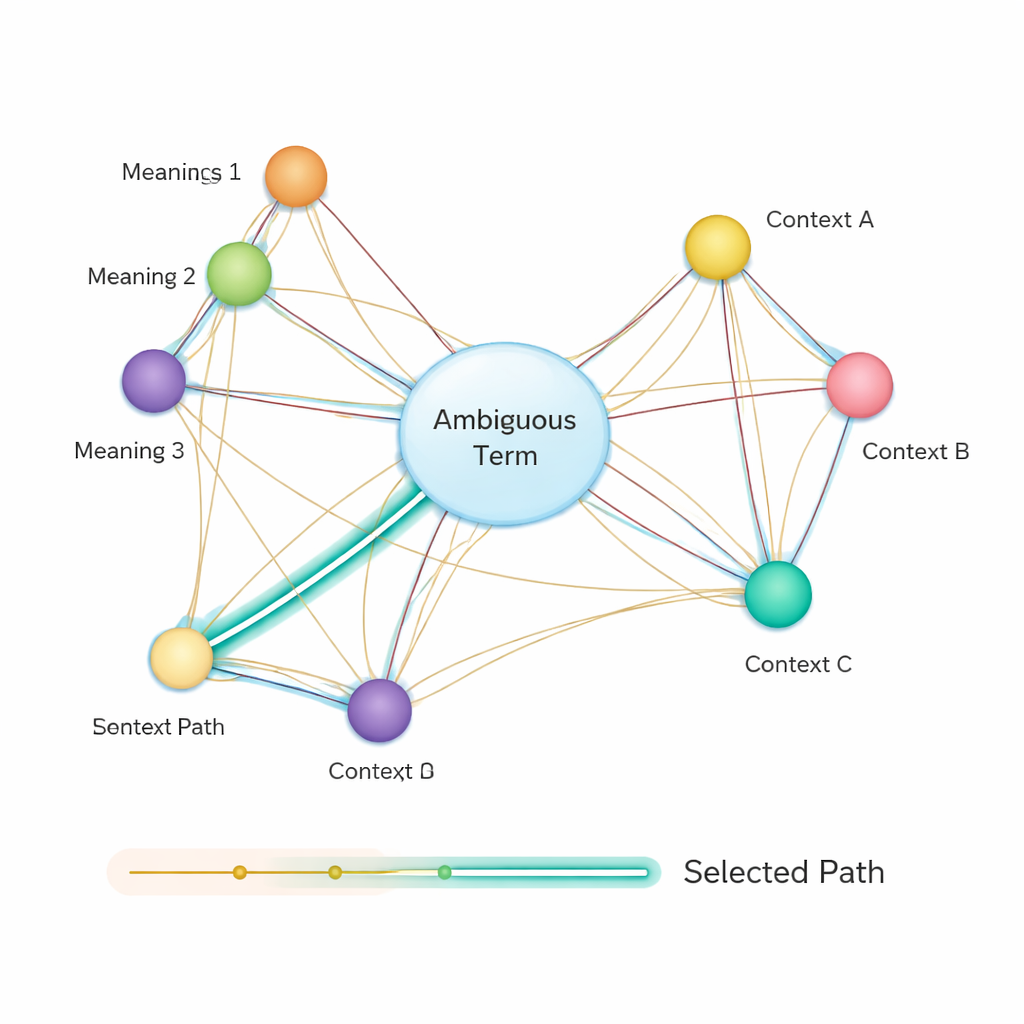
Później metoda buduje sieć semantyczną: graf, w którym każde możliwe znaczenie każdego terminu jest węzłem, a krawędzie łączą znaczenia, które mogą współwystępować w tym samym zdaniu. Siła każdej krawędzi oparta jest na tym, jak podobne są znaczenia, ponownie przy użyciu wektorów opartych na BERT. Aby zdecydować, które znaczenie niejednoznacznego słowa najlepiej pasuje do zdania, autorzy stosują klasyczny algorytm znany jako algorytm najkrótszej ścieżki Dijkstry. Intuicyjnie system szuka ścieżki przez ten graf znaczeń, która utrzymuje ogólną semantyczną „odległość” jak najmniejszą. Wybrana ścieżka odpowiada spójnej interpretacji wszystkich terminów, a znaczenie niejednoznacznej encji leżące na tej ścieżce zostaje wybrane jako ostateczna odpowiedź.
O ile lepiej to działa?
Badacze przetestowali swoją metodę na publicznym chińskim zbiorze danych z benchmarku CLUE, który symuluje rzeczywiste scenariusze krótkich tekstów, takie jak posty w mediach społecznościowych i zapytania. Porównali cztery podejścia: wersje używające tradycyjnych osadzeń Word2Vec, modelu językowego ELMo, systemu opartego na BERT bez kroku najkrótszej ścieżki oraz pełny pipeline BiLSTM‑CRF‑BERT‑SPA. Wśród tysiąca tekstów ich kompletna metoda poprawiła dokładność, czułość i miarę F1 o około jedną czwartą średnio w porównaniu z innymi. W praktyce system był zarówno lepszy w wykrywaniu poprawnych encji, jak i w robieniu tego konsekwentnie dla różnych rozmiarów danych.
Co to znaczy dla codziennej technologii
Dla osób niebędących specjalistami wniosek jest prosty: poprzez połączenie potężnego modelu rozumienia języka (BERT) z wyszukiwaniem najkrótszej ścieżki w grafie, autorzy dają komputerom bardziej niezawodny sposób ustalania, do czego naprawdę odnosi się niejednoznaczna nazwa w krótkich, zaszumionych tekstach. Może to uczynić wyszukiwarki mądrzejszymi, pomóc platformom społecznościowym lepiej rozumieć posty oraz usprawnić narzędzia dalszego przetwarzania, takie jak systemy rekomendacyjne i grafy wiedzy. Choć metoda jest obecnie ukierunkowana na język chiński i nadal można ją usprawnić pod kątem efektywności, pokazuje, jak łączenie nowoczesnej sztucznej inteligencji z klasycznymi algorytmami może znacząco zmniejszyć niejasności w tym, jak maszyny interpretują nasz codzienny język.
Cytowanie: Liu, X., Zhang, D., Xiao, T. et al. A short text entity disambiguation method based on BERT model and shortest path algorithm. Sci Rep 16, 5720 (2026). https://doi.org/10.1038/s41598-026-36411-7
Słowa kluczowe: rozwiązywanie niejednoznaczności encji, krótki tekst, BERT, graf wiedzy, przetwarzanie języka naturalnego