Clear Sky Science · pl
Oddzielenie treści od stylu w generowaniu obrazów wielostylowych przy użyciu architektury dyfuzji latentnej
Dlaczego lepsze style obrazów mają znaczenie
Od plakatów filmowych i grafik do gier po filtry w mediach społecznościowych — coraz częściej oczekujemy, że obrazy będą zarówno efektowne wizualnie, jak i silnie spersonalizowane. Jednak w praktyce wiele systemów transferu stylu nadal napotyka problemy: mogą zniekształcać twarz osoby, wyginać budynki lub wymagać ciężkiego sprzętu. W artykule przedstawiono nowy model AI, który obiecuje bogatsze style artystyczne przy jednoczesnym zachowaniu oryginalnego obrazu i działaniu na tyle efektywnym, by być użytecznym na codziennych urządzeniach.
Oddzielanie «czego to dotyczy» od «jak to wygląda»
Rdzeniem tej pracy jest model nazwany Dual-Condition Lightweight Style Diffusion Model (DCLSDM). Jego kluczowa idea polega na traktowaniu treści obrazu — obiektów, układu i sceny — jako jednego „kanału”, a traktowania artystycznego — kolorów, faktur, pociągnięć pędzla — jako drugiego, i kontrolowaniu ich niezależnie. Zamiast pozwalać jednej sieci mieszać te dwa aspekty, DCLSDM wykorzystuje dwie dedykowane ścieżki: jedną dla treści i jedną dla stylu. Ścieżka treści koncentruje się na rozumieniu kształtów i znaczeń w obrazie wejściowym lub opisie tekstowym, podczas gdy ścieżka stylu uczy się wizualnego charakteru wybranego dzieła lub opisu stylu.
Jak zbudowano nowy model
DCLSDM opiera się na modelach dyfuzyjnych — tej samej rodzinie technik, która stoi za wieloma nowoczesnymi generatorami obrazów. Zamiast działać bezpośrednio na pełnej rozdzielczości, pracuje w skompresowanej przestrzeni „latentnej”, co jest znacznie wydajniejsze. Moduł zwany Perceiver IO wydobywa treść: przyjmuje obraz lub podpis i destyluje geometrię oraz semantykę sceny do zwartej reprezentacji. Osobny moduł stylu przetwarza jeden lub więcej obrazów stylu albo tekstów i konwertuje je na wektory cech stylu. Te cechy stylu można mieszać za pomocą ważonego interpolowania, co pozwala na płynne przejścia między np. impresjonistycznym a minimalistycznym wyglądem bez typowego „brejowatego” uśrednienia.
Zachowanie struktury przy zmianie stylu
W sieci dyfuzyjnej, która właściwie generuje obraz, dwa typy informacji są wprowadzane przez niezależne kanały. Sygnały treści kierują warstwami sieci, które odpowiadają za strukturę — gdzie mają znajdować się krawędzie, obiekty i układy. Sygnały stylu są wprowadzane przez dedykowane warstwy uwagi, które przede wszystkim kształtują faktury, kolory i pociągnięcia pędzla. Dodatkowo komponent zwany ControlNet dodaje dodatkowe wskazówki strukturalne przy użyciu map krawędzi lub głębokości wyekstrahowanych z oryginalnej treści. To połączenie pozwala np. przemalować letni krajobraz w zimną paletę lub odwzorować fotografię jako obraz w stylu van Gogha, przy jednoczesnym zachowaniu gór, drzew i budynków na właściwych miejscach i bez zniekształceń.
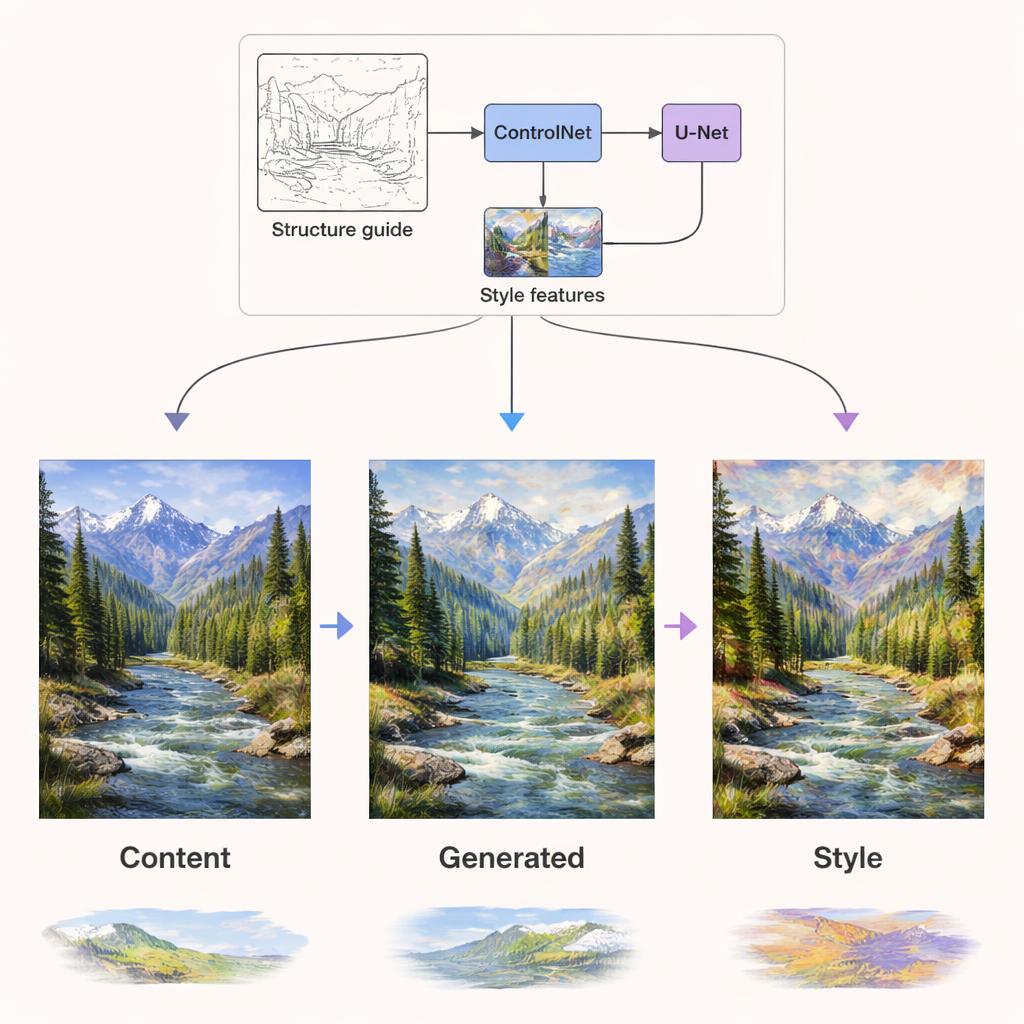
Lepsza jakość, więcej stylów, mniejsze zapotrzebowanie obliczeniowe
Autorzy rygorystycznie testują DCLSDM na dwóch publicznych zbiorach danych: WikiArt, obejmującym dziesiątki ruchów artystycznych, oraz Summer2Winter Yosemite, skupiającym się na sezonowych zmianach krajobrazu. Porównują swój model z szeregiem zaawansowanych systemów używanych w badaniach i przemyśle. W miarach podobieństwa strukturalnego, postrzeganej jakości wizualnej oraz stopnia, w jakim wygenerowane obrazy przypominają prawdziwe dzieła sztuki, DCLSDM konsekwentnie osiąga najwyższe wyniki. Działa też szybciej, zużywa mniej pamięci i ma mniej parametrów niż wielu konkurentów, a jednocześnie oferuje elastyczne mieszanie wielu stylów i obsługuje wejście stylu w postaci zarówno obrazów, jak i tekstu.
Co to oznacza dla codziennej kreatywności
W praktyce ta praca pokazuje, że można dać użytkownikom precyzyjną kontrolę nad wyglądem obrazu bez poświęcania tego, co obraz pokazuje — i zrobić to na skromniejszym sprzęcie. Projektanci mogliby szybko eksplorować wiele artystycznych opracowań tego samego układu, aplikacje mobilne mogłyby oferować bogatsze filtry, które nie deformują twarzy ani scen, a projekty związane z dziedzictwem kulturowym mogłyby przekształcać stare zdjęcia, zachowując kluczowe detale strukturalne. Poprzez wyraźne oddzielenie treści od stylu w nowoczesnym ramach dyfuzyjnym, DCLSDM wskazuje na przyszłość, w której narzędzia kreatywne będą zarówno potężniejsze, jak i bardziej niezawodne w codziennym użyciu.
Cytowanie: Chu, K., Shang, Y., Zhang, L. et al. Content style decoupling for multi style image generation using latent diffusion architecture. Sci Rep 16, 6642 (2026). https://doi.org/10.1038/s41598-026-36407-3
Słowa kluczowe: transfer stylu obrazu, modele dyfuzyjne, oddzielenie treści i stylu, generowanie sztuki cyfrowej, efektywne generowanie obrazów