Clear Sky Science · pl
Ramowa uczenia przez wzmacnianie dla komputerowego testowania adaptacyjnego z wykorzystaniem podejścia wieloramiennego bandyty
Inteligentniejsze testy dla cyfrowej klasy
Każdy, kto uczestniczył w długim, uniwersalnym teście, wie, jak nużący i niesprawiedliwy może się on wydawać. Niektóre pytania są zbyt proste, inne niewykonalnie trudne, a końcowy wynik może nie odzwierciedlać rzeczywistej wiedzy. W artykule przedstawiono nowy sposób tworzenia testów komputerowych, które w czasie rzeczywistym dostosowują się do odpowiedzi każdej osoby. Czerpiąc z pomysłów współczesnej sztucznej inteligencji, autorzy dążą do tego, by egzaminy były krótsze, bardziej precyzyjne i lepiej dopasowane do rzeczywistej umiejętności zdającego.
Dlaczego testy stałe zawodzą
Tradycyjne egzaminy zadają wszystkim uczniom te same pytania. Ułatwia to tworzenie testów, ale marnuje informacje: zdolniejsi uczniowie przedzierają się przez wiele łatwych pozycji, podczas gdy uczniowie mający trudności szybko zostają przytłoczeni. Komputerowe testowanie adaptacyjne próbuje to naprawić, dobierając kolejne pytania na podstawie wcześniejszych odpowiedzi, ale większość obecnych systemów nadal opiera się na statystycznych modelach i regułach opracowanych dekady temu. Starsze podejścia mają trudności ze wychwyceniem złożonych wzorców odpowiedzi i często nie radzą sobie w pełni z dużą różnorodnością uczących się w nowoczesnych, masowych środowiskach online.
Wprowadzenie współczesnej SI do testowania
Autorzy proponują nową ramę, która łączy uczenie głębokie i uczenie przez wzmacnianie, aby prowadzić test adaptacyjny od początku do końca. System działa w cyklach powtarzalnych. Najpierw jednowymiarowa splotowa sieć neuronowa (1D‑CNN) analizuje niedawne odpowiedzi osoby, trudność pytań oraz inne statystyki podsumowujące. Z tego strumienia danych produkuje pojedynczą liczbę reprezentującą aktualny poziom umiejętności na skali znormalizowanej, podobnie jak tradycyjne teorie testowania opisują zdolność, lecz tutaj uczoną bezpośrednio z danych. Sieć jest trenowana, by rozpoznawać subtelne wzorce, takie jak konsekwentne sukcesy przy trudniejszych pytaniach lub niespodziewane błędy przy łatwiejszych. 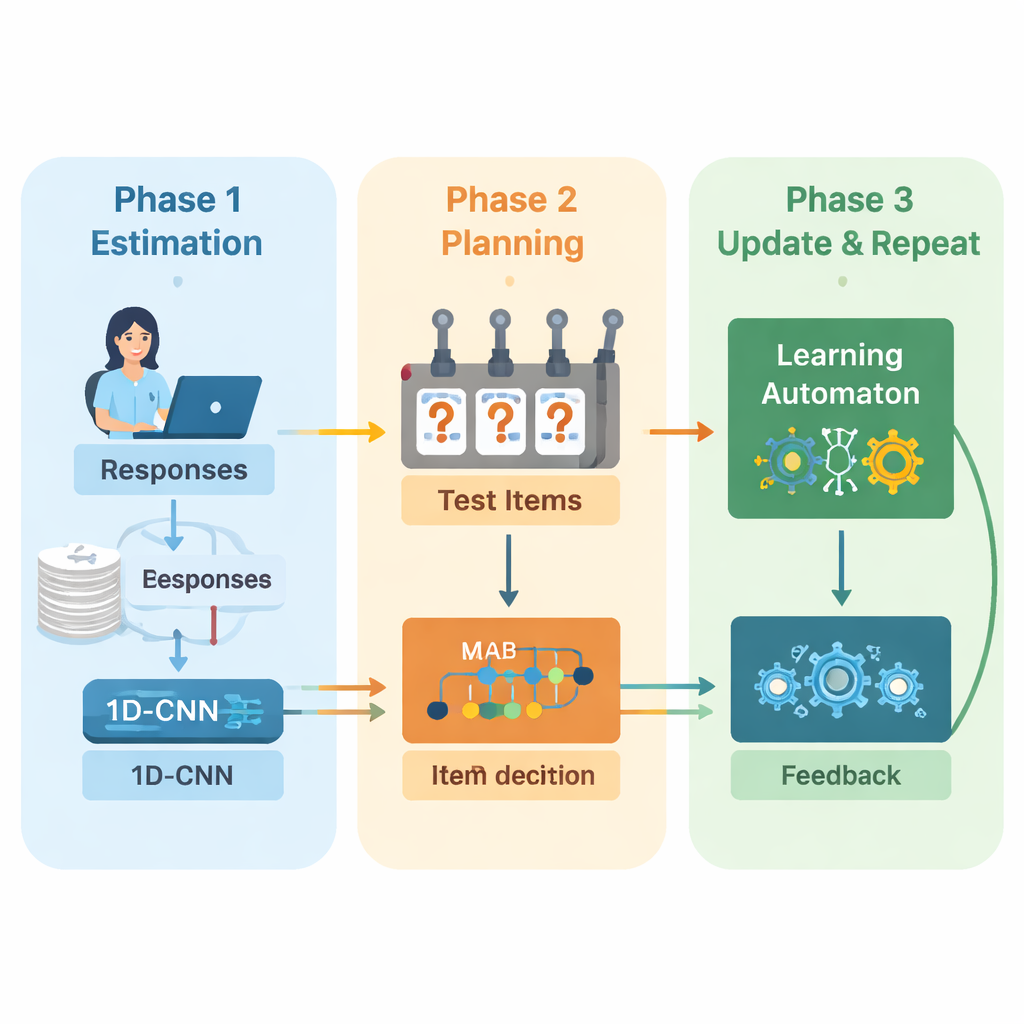
Dobór właściwego kolejnego pytania
Gdy system ma zaktualizowaną ocenę umiejętności, musi zdecydować, co zadać dalej. Autorzy wykorzystują do tego strategię „wieloramiennego bandyty”, klasyczne narzędzie z teorii decyzji, w którym każdemu możliwemu działaniu przypisuje się analogię pociągnięcia dźwigni w automacie do gry. W tym kontekście każde pytanie w bazie jest jedną „ramieniem”. Algorytm rozważa pytania o trudności mniej więcej odpowiadającej bieżącej estymacji umiejętności, a następnie wybiera te, które mają największą przewidywaną wartość informacyjną. Godzi dwa cele: dobranie odpowiedniej trudności, aby odpowiedzi nie były ani zbyt łatwe, ani zbyt trudne, oraz pokrycie jak największej liczby obszarów treści, by test nie pomijał istotnych tematów. Proces wyboru kieruje wynik nagrody łączący oba te cele.
Uczenie się na własnych decyzjach
Aby ciągle się poprawiać w trakcie testu, system dodaje kolejny komponent uczący się, zwany automatorem uczącym. Moduł ten obserwuje, jak estymowana umiejętność zmienia się między rundami oraz czy trafność odpowiedzi osoby rośnie czy maleje. Dostosowuje niewielki zestaw prawdopodobieństw, które podsumowują oczekiwanie modelu co do tego, czy umiejętność wzrośnie, pozostanie bez zmian, czy spadnie. Te prawdopodobieństwa są potem przekazywane jako dodatkowe dane wejściowe do sieci neuronowej w kolejnej rundzie. W ten sposób silnik testu nie tylko uczy się o studencie, ale także uczy się na podstawie własnych wcześniejszych decyzji — nagradzając trendy prowadzące do trafnych estymacji i karząc te, które takich estymacji nie dawały. 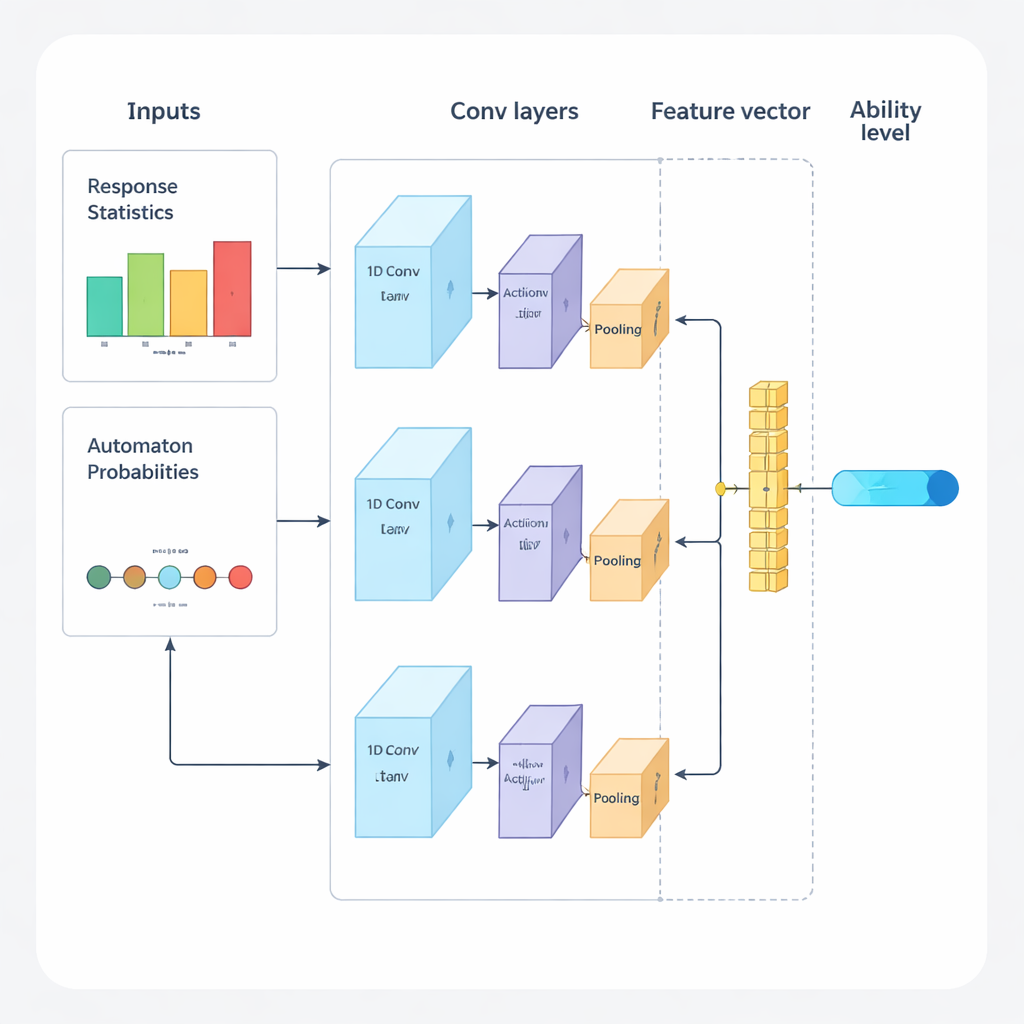
Jak to działa w praktyce?
Badacze ocenili swoją ramę, korzystając z dużego, wielojęzycznego zbioru danych egzaminacyjnych oraz z tysiąca symulowanych zdających, których rzeczywiste poziomy umiejętności były znane. Porównali swoje podejście z kilkoma wiodącymi metodami testowania adaptacyjnego. W różnych miarach błędu i korelacji nowy system dostarczył dokładniejsze estymacje umiejętności przy mniejszej liczbie pytań. Jego błędy — mierzone powszechnymi statystykami, takimi jak pierwiastek średniego błędu kwadratowego i średni błąd bezwzględny — były wyraźnie niższe niż w konkurencyjnych metodach. Jednocześnie rozkład użycia pytań był bardziej równomierny w bazie pozycji, zmniejszając ryzyko nadmiernej eksploatacji i wycieku niektórych pytań.
Co to oznacza dla przyszłych egzaminów
Mówiąc prościej, praca ta sugeruje, że przyszłe testy komputerowe mogą bardziej przypominać spersonalizowaną sesję nauczania niż sztywny egzamin. Pytania szybko dobierałyby właściwy poziom trudności dla każdej osoby, obejmowały pełen zakres istotnych tematów i kończyły się, gdy system byłby pewny poziomu — często przy mniejszej liczbie pozycji niż dzisiejsze testy. Chociaż metoda nadal zależy od dobrych danych treningowych i mocy obliczeniowej, i jak dotąd przetestowano ją na jednym zbiorze danych, wskazuje ona kierunek ku nowemu pokoleniu inteligentniejszych, sprawiedliwszych i wydajniejszych ocen, które naturalnie dostosowują się do indywidualnych uczących się.
Cytowanie: Tang, B., Li, S. & Zhao, C. Reinforcement learning framework for computerized adaptive testing using multi armed bandit approach. Sci Rep 16, 7441 (2026). https://doi.org/10.1038/s41598-026-36394-5
Słowa kluczowe: komputerowe testowanie adaptacyjne, ocena edukacyjna, uczenie głębokie, uczenie przez wzmacnianie, wieloramienny bandyta