Clear Sky Science · pl
Identyfikacja czynników ryzyka dla dużych urządzeń rozrywkowych z użyciem mieszanki ekspertów i fuzji wielu modeli
Dlaczego bezpieczeństwo parków rozrywki wymaga mądrzejszego czytania
Co roku setki milionów ludzi wsiadają na kolejki górskie, wieże spadkowe i karuzele, ufając, że złożone maszyny i zajęci operatorzy zapewnią im bezpieczeństwo. Za kulisami regulatorzy i inżynierowie generują ogromne ilości raportów, zapisów o wypadkach i skarg publicznych — lecz większość tych informacji istnieje w formie tekstowej, którą trudno szybko przeanalizować. Badanie to bada, jak zaawansowana sztuczna inteligencja może „czytać” te dokumenty na dużą skalę, wcześniej wyłapywać wzorce zagrożeń i dawać władzom jaśniejszy obraz miejsc, w których urządzenia rozrywkowe najprawdopodobniej zawiodą.
Z rozproszonych raportów do ujednoliconego obrazu ryzyka
Chiny mają dziś ponad 25 000 dużych urządzeń rozrywkowych i ponad 700 milionów odwiedzających rocznie. Pomimo ogólnych postępów w bezpieczeństwie nadal zdarzają się rzadkie, ale poważne wypadki, często po tym, jak inspekcje nie zauważyły wczesnych sygnałów ukrytych w opisach technicznych lub skargach użytkowników. Autorzy twierdzą, że tradycyjny nadzór — oparty na okresowych ręcznych kontrolach, ocenie ekspertów i zapisach konserwacji — jest zbyt wolny i subiektywny w tak dynamicznym środowisku. Zgromadzili dużą, rzeczywistą kolekcję tekstów obejmującą raporty o wypadkach, przepisy i normy, zapisy inspekcji i konserwacji oraz skargi online związane z obiektami rozrywkowymi. Po starannym oczyszczeniu i przefiltrowaniu, korpus z wielu źródeł staje się surowcem dla zautomatyzowanego, napędzanego danymi systemu monitorowania ryzyka. 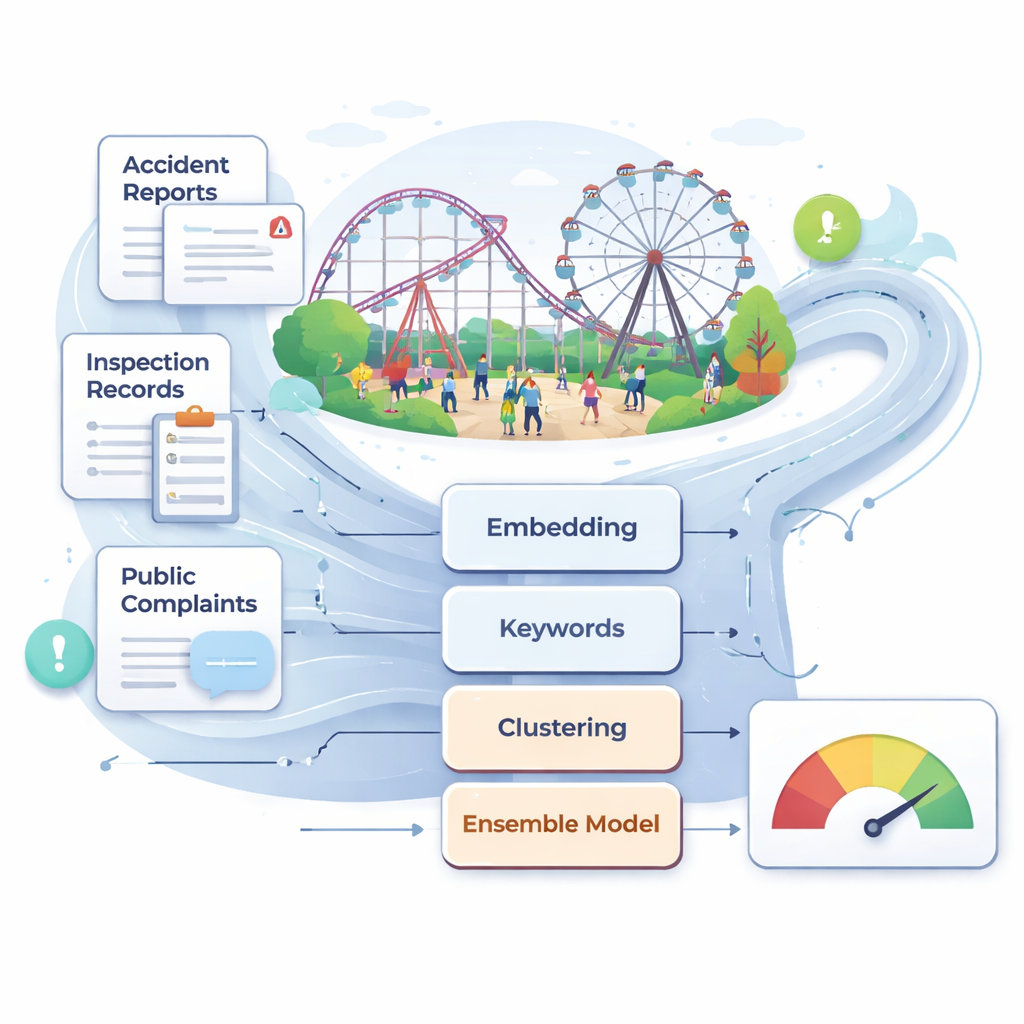
Nauka komputerów rozumienia języka ryzyka
Aby uporządkować ten niejednorodny tekst, badacze opierają się na nowoczesnych modelach językowych, które zamieniają zdania na wektory liczbowe odzwierciedlające ich znaczenie. Głównie używają chińskiego modelu BGE, który reprezentuje każdy fragment tekstu jako punkt w przestrzeni o 1024 wymiarach, oraz kompaktowego zestawu 30 cech opartych na słowach kluczowych skupionych wokół terminów takich jak „konserwacja”, „inspekcja” i „korekta”. To podwójne spojrzenie — głęboki kontekst semantyczny plus ręcznie dobrane frazy ryzyka — pomaga systemowi rozróżniać subtelne różnice między, na przykład, rutynowymi kontrolami a poważnymi usterkami. Zespół eksperymentuje również z innym nowoczesnym modelem osadzającym, Qwen3, by sprawdzić, czy zmiana rdzenia językowego poprawia wydajność; w praktyce BGE okazuje się nieco lepszy w tym zadaniu bezpieczeństwa.
Wykrywanie ukrytych wzorców i kluczowych słabości
Zanim teksty zostaną sklasyfikowane do konkretnych kategorii ryzyka, autorzy stosują metody bez nadzoru, by odkryć naturalne grupowania. Zastosowali k-means do osadzeń i użyli metody wizualizacji UMAP, aby pokazać, że raporty dzielą się na kilka wyraźnych klastrów tematycznych. Następnie budują graf semantyczny, w którym każdy węzeł to słowo kluczowe związane z bezpieczeństwem, a łącza wskazują silne współwystępowanie i podobieństwo semantyczne. Algorytm wykrywania społeczności grupuje te węzły w klastry odpowiadające szerokim tematom, takim jak bezpieczeństwo sprzętu i konstrukcji, codzienna eksploatacja i konserwacja, reagowanie w sytuacjach awaryjnych oraz zarządzanie i nadzór. W obrębie tej sieci niektóre słowa — jak „konserwacja”, „inspekcja” i „odpowiedzialność” — działają jak mosty między klastrami, uwypuklając przekrojowe słabości, które mogą wywoływać wypadki na różne sposoby. Z tej struktury wyodrębnili 31 podstawowych czynników ryzyka obejmujących cztery główne wymiary, od monitorowania sprzętu w czasie rzeczywistym po jasność podziału obowiązków. 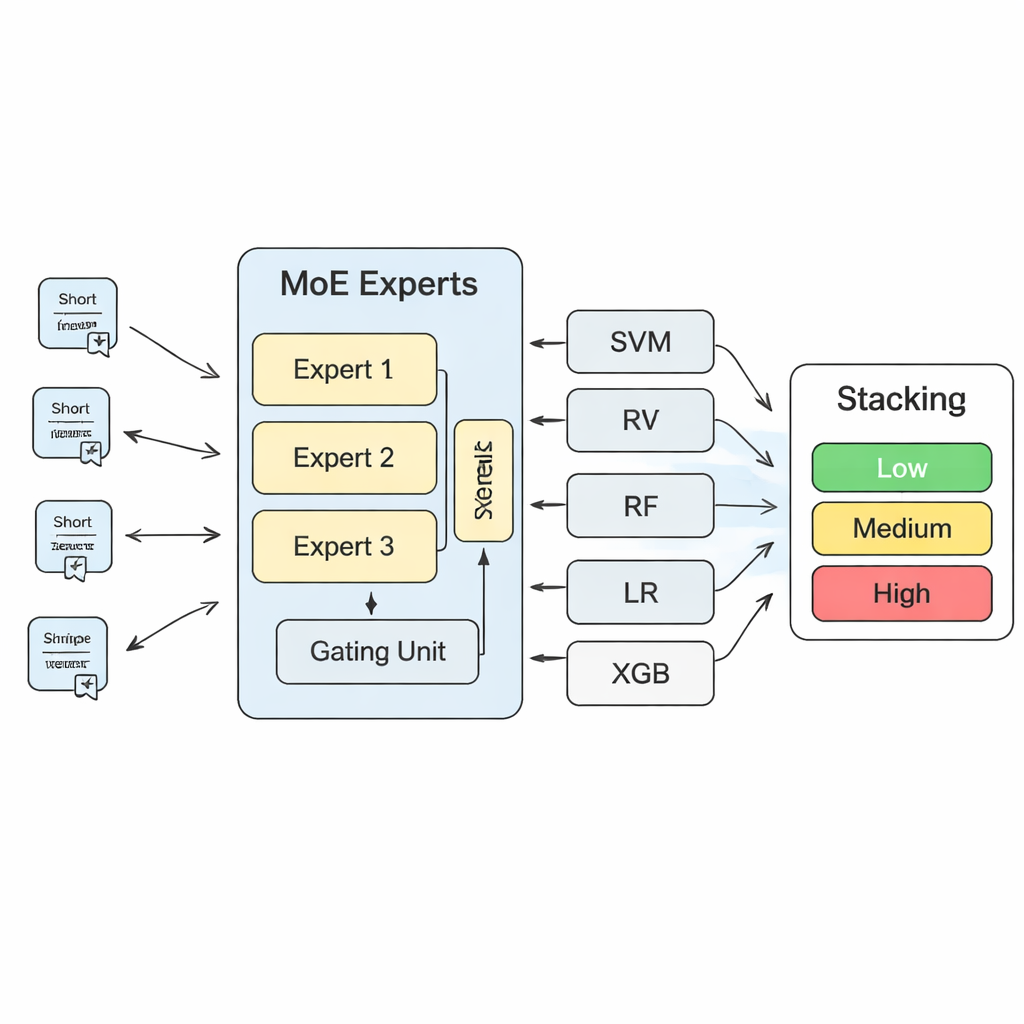
Mieszanie wielu modeli w jednego silniejszego sędziego bezpieczeństwa
Aby przekształcić te wnioski w konkretne prognozy ryzyka, badanie buduje wielowarstwowy system uczenia maszynowego. W jego centrum znajduje się model „mieszanki ekspertów” (Mixture of Experts, MoE): kilka sieci neuronowych, czyli ekspertów, z których każdy uczy się specjalizować w różnych rodzajach wzorców ryzyka, podczas gdy komponent bramkowy decyduje, którym ekspertom ufać najbardziej dla danego tekstu. Wyjścia z tego modelu MoE są następnie łączone z predykcjami bardziej tradycyjnych algorytmów, takich jak maszyny wektorów nośnych, lasy losowe, regresja logitowa i drzewa z gradientowym wzmacnianiem. Końcowa warstwa „Stacking” — kolejny model uczenia maszynowego — uczy się, jak ważyć wszystkie te opinie, by osiągnąć ostateczną decyzję. Na podstawie szerokiej walidacji krzyżowej autorzy stwierdzają, że użycie trzech ekspertów w warstwie MoE daje najlepszy kompromis między pojemnością modelu a stabilnością.
Co zyski oznaczają dla nadzoru w praktyce
W porównaniu z pojedynczym modelem, system MoE-plus-Stacking znacząco poprawia dokładność, precyzję, czułość oraz miarę niezawodności zwaną LogLoss. W praktyce oznacza to mniej przeoczonych ostrzeżeń i mniej fałszywych alarmów podczas przeglądania dużych ilości tekstów o bezpieczeństwie. Model może działać na zwykłej stacji roboczej i dostarczać szybkie oceny ryzyka dla nowych raportów inspekcyjnych lub skarg, co czyni go narzędziem wspierającym decyzje, a nie zastępującym ludzkie orzeczenie. Autorzy podkreślają, że ich podejście można dostosować poza urządzenia rozrywkowe — do innych specjalnych urządzeń, takich jak windy czy koleje linowe. Dla czytelników niebędących specjalistami kluczowy wniosek jest taki, że ucząc komputery czytać język bezpieczeństwa — w dokumentach technicznych, przepisach i codziennych skargach — regulatorzy mogą wcześniej wykrywać wzorce niebezpieczeństwa, inteligentniej celować inspekcje i sprawić, że wizyta w parku będzie nieco bezpieczniejsza dla wszystkich.
Cytowanie: Hao, S., Xing, L. & Zhang, M. Risk factor identification for large scale amusement facilities using mixture of experts and fusion of multiple models. Sci Rep 16, 6804 (2026). https://doi.org/10.1038/s41598-026-36377-6
Słowa kluczowe: bezpieczeństwo urządzeń rozrywkowych, analiza tekstu ryzyka, uczenie maszynowe, mieszanka ekspertów, monitorowanie bezpieczeństwa publicznego